全流程可视化:逐步拆解LLM的每一步计算AI-lab学习笔记
引言:当你在 ChatGPT 输入"请解释量子力学",它是怎么一步步生成回答的?
今天我们用一个 可以完全看透的小模型,把这个过程从头到尾拆给你看。不是示意图,不是模拟数据——是直接打开模型内部,提取每一步的真实计算结果。
我们的工具:
用《西游记》全文训练的 nanoGPT(4.3M 参数,4 层 Transformer)
看模型如何预测下一个字
这个模型和 GPT-4 使用完全相同的架构(Transformer),区别只在规模。理解了这个小模型,就理解了所有大模型的本质。
全局架构总览
在深入每一步之前,先看完整的数据流路径:
接下来逐步拆解每个环节,展示真实的中间数据。
阶段 1:原始文本输入
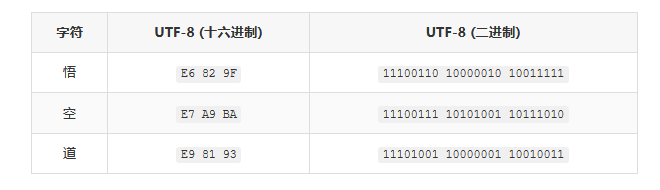
人类输入的文字,对计算机来说只是一串字节。先看看每个字符的 UTF-8 编码:
中文每个字占 3 个字节,英文每个字母只占 1 个字节。 这是 UTF-8 编码的特点。
阶段 2:Tokenization — 文字变数字
LLM 不直接处理字节,而是将文本转换为 Token ID(数字编号)。
我们的模型使用字符级分词——每个字符就是一个 token,词表大小 4487 个唯一字符。
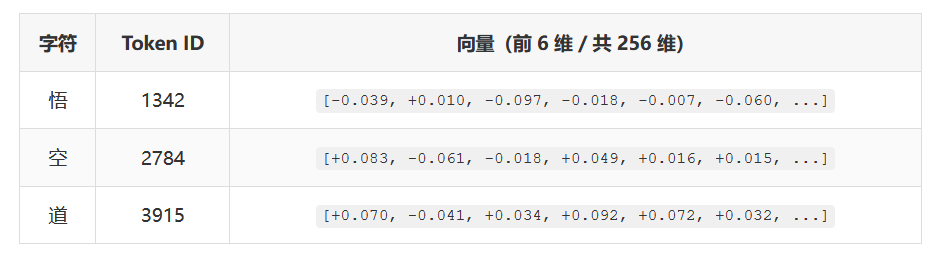
结果:"悟空道" → [1342, 2784, 3915]
stoi 是 "String TO Integer" 的缩写,就是一个字符→数字的查找表,在数据准备阶段从训练语料中自动构建。
Token 的大小不是固定的
Token ID 本身用 16-bit 整数存储(2 字节),但它代表的原文可长可短。
阶段 3:Token ID → 二进制 → 张量
Token ID 是整数,计算机用二进制存储。然后打包成 PyTorch 张量(Tensor)——这才是进入模型的真正输入。
数据变换路径: 文字世界 → 数字世界 → 二进制 → 张量 (Tensor)
阶段 4:Embedding — 给每个 Token 一张"数字身份证"
每个 Token ID 在 Embedding 矩阵中查找对应的一行向量。矩阵形状:(4487 x 256)——词表中每个字符都有一个 256 维的向量表示。
Token Embedding(语义嵌入)
直接调用 model.transformer.wte(idx),即 nn.Embedding 查表:
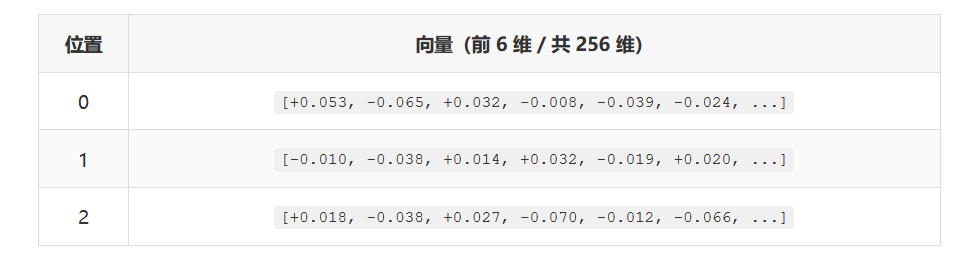
Position Embedding(位置编码)
让模型知道字的顺序。调用 model.transformer.wpe(pos):
两者相加 → 每个 token 的初始表示,输出形状 [1, 3, 256]。
阶段 4B:Embedding 是怎么来的?
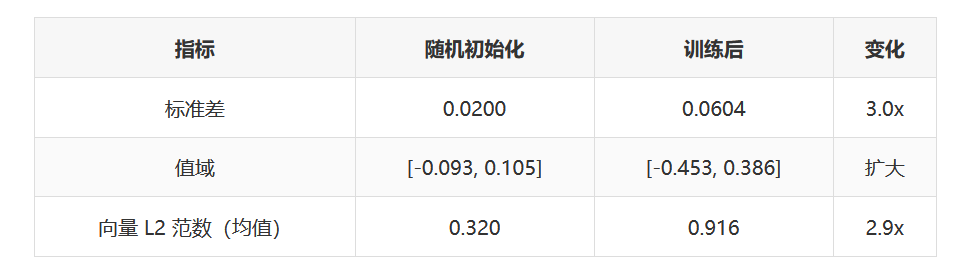
一开始是随机数,通过训练逐渐学出有意义的值。
训练前后对比
训练后,向量空间扩大了约 3 倍,常用字的向量更大更"自信",罕见字的向量较小。
语义相似度的涌现
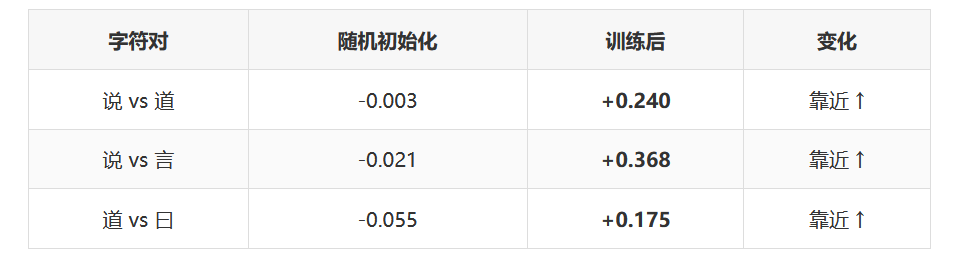
同义词组:说、道、言、曰(都表示"说话")
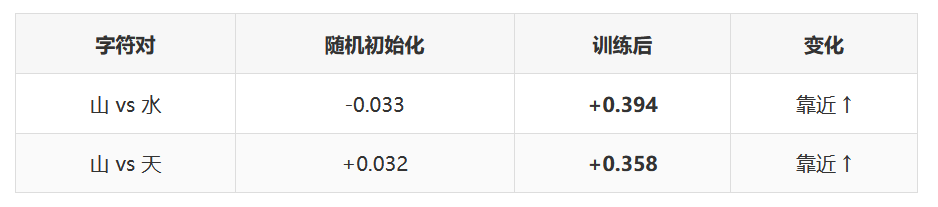
场景词组:山、水、天(都是自然/场景词)
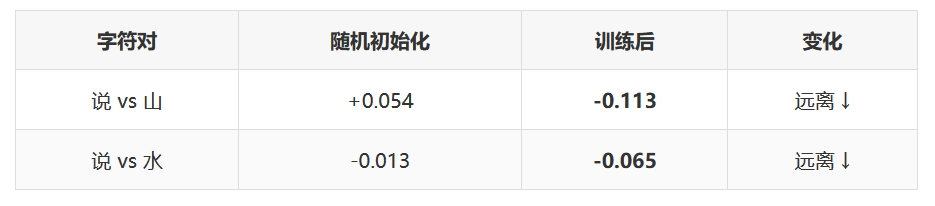
跨组对比("说话"类 vs "自然"类)
关键发现: 训练前所有向量都是随机噪声(相似度接近 0)。训练后,语义相关的字自动靠近,不相关的字保持距离甚至远离。没有人告诉模型这些字"意思相近"——这个语义结构完全是从数据中涌现的。