开发者用10天婚假爆肝,让AI小镇「活」了过来新智元
2023年斯坦福「AI小镇」火了,后续也诞生了大量类似的热门项目,但所有这类项目都有一个共同瓶颈——世界是人工搭建的,固定的。最近,一位独立开发者用10天婚假爆肝了一个项目WorldX:输入一句话、5分钟,一个完整的AI世界就诞生了——地图、角色、动画、人设全部自动生成,AI角色们自主在其中生活、对话、形成记忆、产生戏剧性的涌现行为。
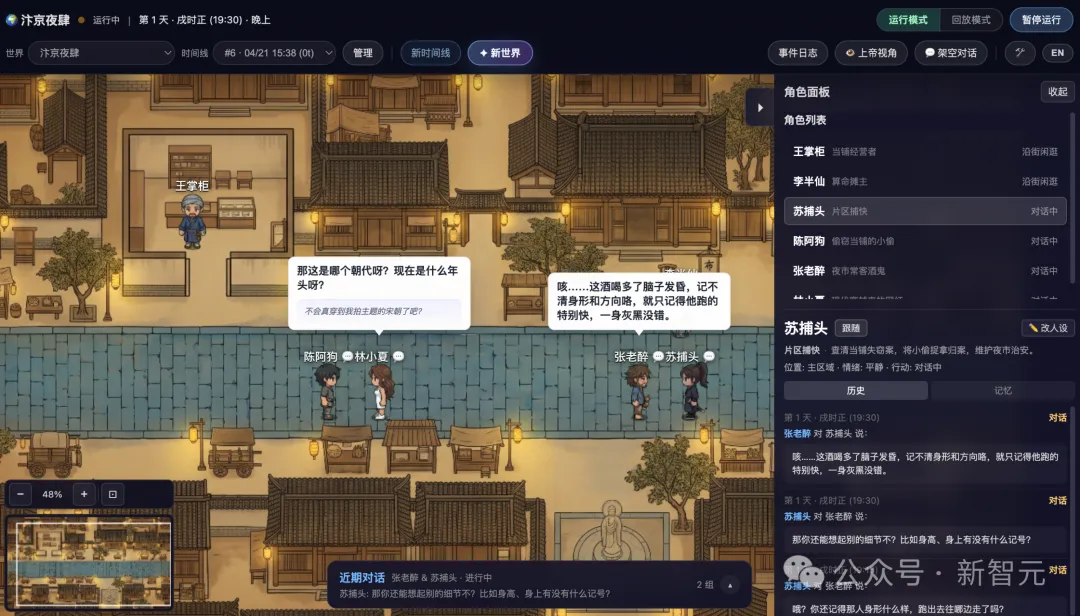
输入这样一句话:「夜晚的宋朝繁华夜市,有当铺掌柜、算命先生、捕快、小偷、酒鬼,还有一个刚从现代穿越来的网红。」
5分钟后,一张工笔画风格的宋朝夜市地图出现在你面前。当铺、算命摊、菩萨像各居其位。
然后6个角色自己开始活动——
当铺掌柜守着柜台念叨被偷的事,算命先生等客上门,捕快四处巡逻打听线索,小偷装作普通路人混在人群里,酒鬼醉醺醺地从街头晃到街尾。而那个穿越来的网红——飘逸长发、衣着和旁人格格不入——正被所有人好奇地打量着。
没人写过剧本。
接下来发生的一切,完全由AI角色自主决定。捕快可能会找上每一个人盘问;小偷可能会主动接近捕快试探,又会突然觉得自己暴露了想找借口溜走;算命先生会拉住穿越来的网红说「姑娘印堂发暗」;酒鬼可能会撞翻当铺掌柜的招牌,引来一场争吵。
这是一个真正「活着」的AI世界。
项目地址: https://github.com/YGYOOO/WorldX
技术解析: https://zhuanlan.zhihu.com/p/2032410449854068566
AI小镇火了3年
还没解决「造世界」
故事得从2023年说起。
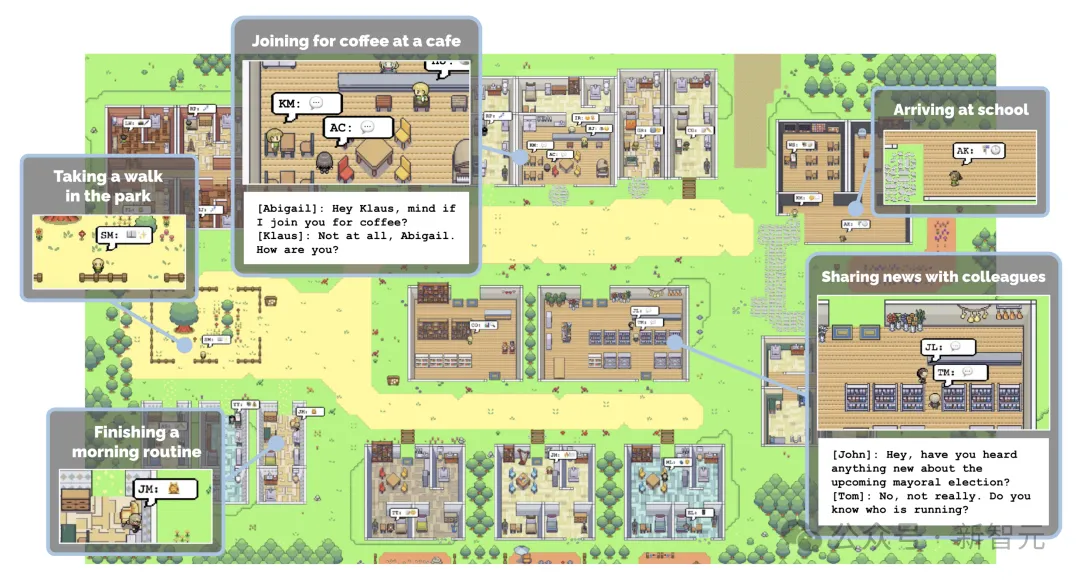
那一年,斯坦福发布了著名的Generative Agents论文——25个AI角色在一个虚拟小镇里自主生活、社交、形成记忆,展现出令人惊叹的「 涌现行为」。「AI小镇」这个概念瞬间出圈,引爆了整个Agent研究领域。
之后3年里,类似的热门项目层出不穷,ai-town、Microverse、AgentSims、TinyTroupe……都在试图复现并扩展这件事。
但所有这些项目,都有一个共同的瓶颈:
世界是写死的。
地图需要人工绘制。角色需要逐个手动配置。场景交互需要逐条编排。你想换一个「赛博朋克拉面馆」或者「末日便利店」的设定?对不起,从头来过。
学术界也意识到了这个问题。盛大AI研究院、上海AI Lab等机构联合发表了「World Craft」(arXiv 2601.09150)尝试解决这件事——但论文中也明确写道:当前系统只支持室内场景(住宅、办公室、单体建筑内部),不支持街道、广场、开放世界。而且地图风格高度同质化——都是从一个5500+素材库里检索拼装的标准RPG像素风。
真正「任意一句话造任意一个世界」,迄今没人做到。
直到WorldX出现。
「一句话造世界」的5分钟魔法
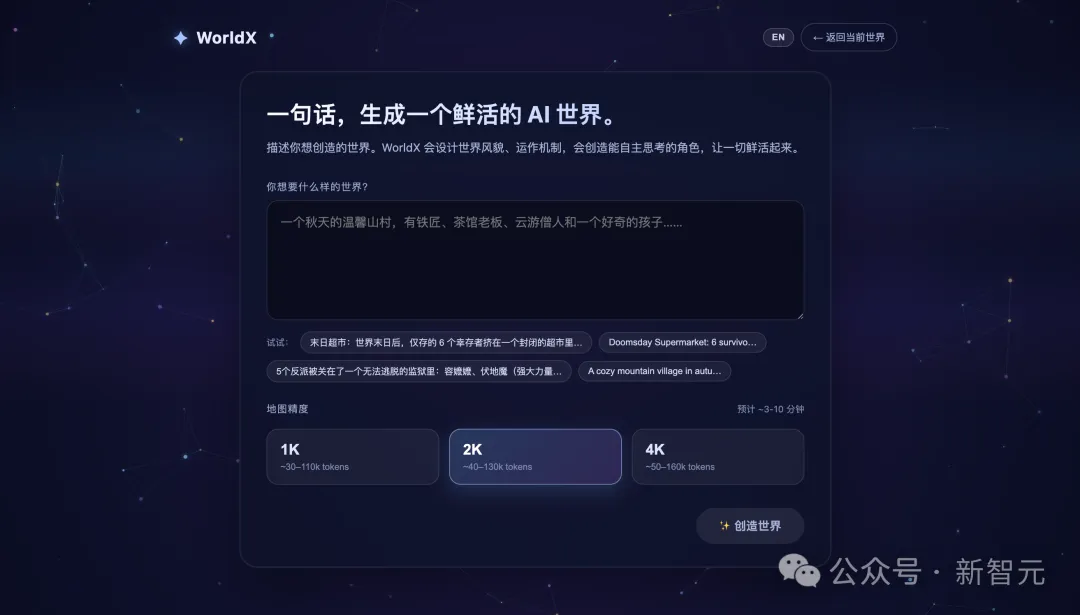
WorldX让这件事变得简单到不可思议。
你只需要输入:
末日便利店,6个幸存者挤在里面
北宋汴京夜市,有算命的、说书的、捕快和一个穿越者
魏无羡的师姐江厌离、卡卡西的挚友带土、扶苏、晴雯——那些没等到好结局的人住进了同一个小镇
6个经典反派被关进了一个像素小镇:容嬷嬷、伏地魔、灭霸、琴酒……
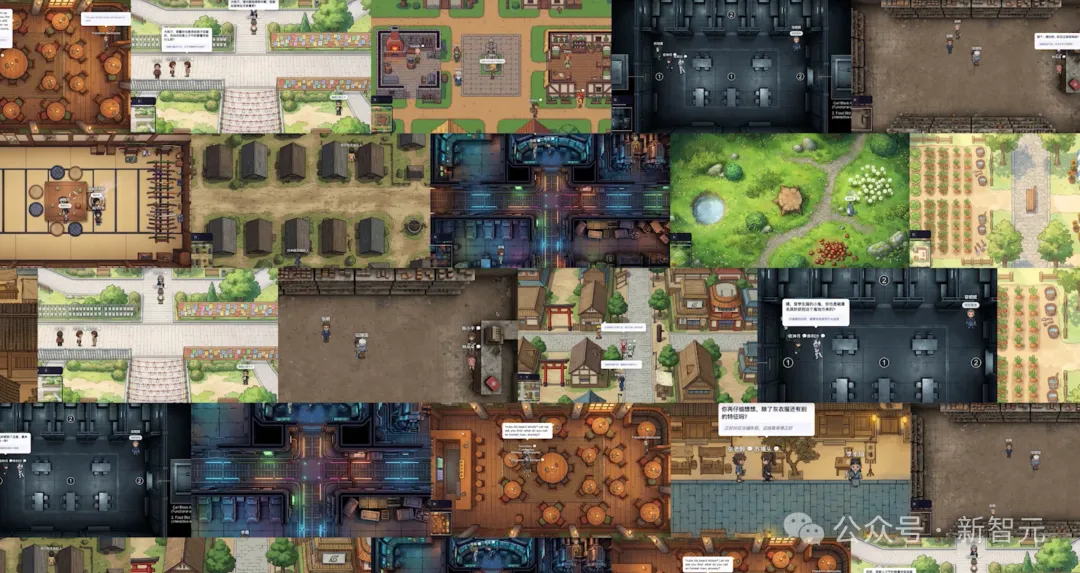
5分钟后,一个完整的、有美术风格、有角色立绘动画、有完整运行逻辑的AI世界就出现在你面前。每一个世界都是从零生成的,没有任何模板复用。
更关键的是——生成完只是开始。
进入世界后,你会看到:
每个AI角色在地图上自由走动、决策、互动
角色头顶会冒出对话气泡和内心独白OS(小偷和捕快客套时心里想着「她不会已经知道了吧……」——节目效果直接拉满)
角色们形成记忆、产生情绪、做出反思——一天结束时它们会在脑海里回顾今天发生的事
世界有真实的时间流转,凌晨1点夜市会自动收摊,第二天19点又重新开张
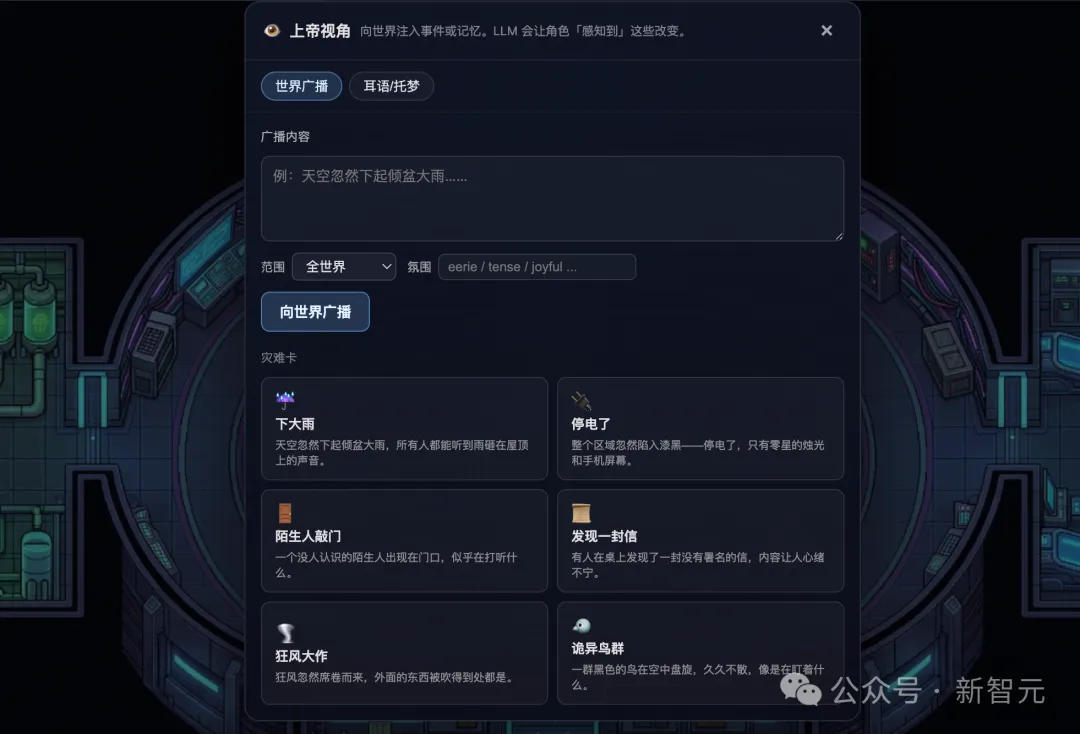
而你呢?你是这个世界的「上帝」。
全局广播事件——「突然下大雨了」,所有角色下次决策时都会知道
给特定角色耳语/托梦——你突然想起当年捕快办过的一桩旧案……
实时修改角色人设——把「老实木讷」改成「心机深沉」,看世界走向会怎么变
把任意角色「拉出来」,和它进行架空对话——而且不影响主世界进程
更绝的是WorldX还做了多时间线 + 历史回放机制——同一个世界可以衍生出多条时间线,看相同的初始条件下故事是否会走向同一个结局;任意一段历史也能像看录像一样被回放,让你不错过任何「名场面」。
让AI看懂自己生成的图
作者自己列了一份「卡点问题」清单,每一项都几乎能让整个项目卡死,比如下面这个问题:
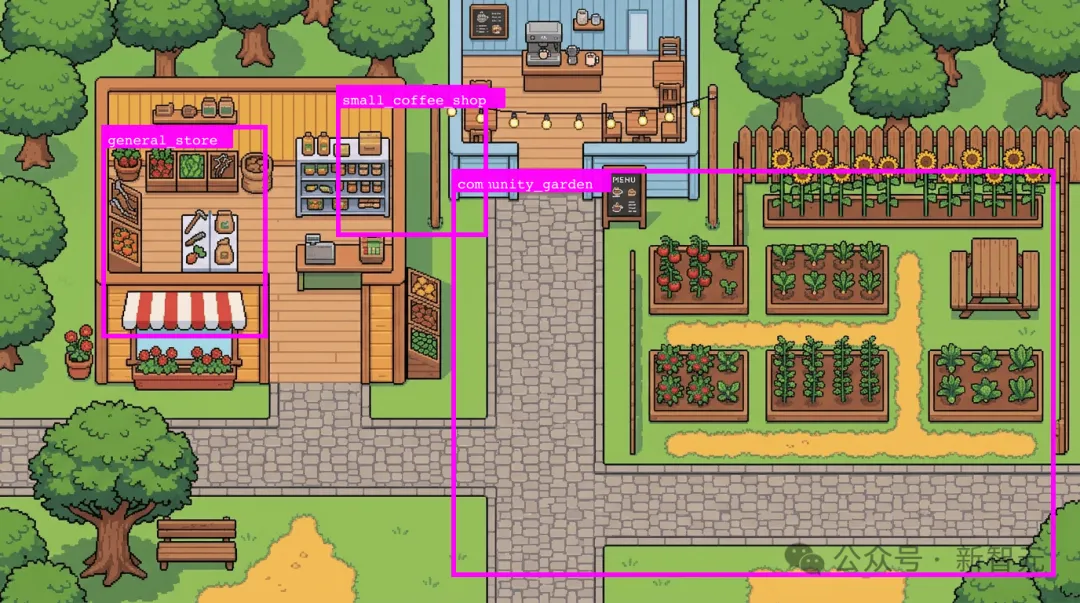
如何让代码精确知道——AI生成的这张地图里,哪些区域是可行走的?
这件事看起来简单——人一眼就能看出哪里能走、哪里是树木屋顶。但要让代码知道,意味着需要精确到每个像素的坐标。而文生图模型生成的地图,本质上就是一张「图片」,没有任何分层、标注、坐标信息。
最直觉的方案是让多模态大模型(如 Gemini 3 Pro)直接看图返回坐标。作者实测后发现完全行不通——VLM输出的像素坐标误差极大,同一张图问两次能给出差很远的答案。
这是大模型的本质局限:它们被训练出来是为了像人一样理解图片内容,而不是当尺子用——人也远不可能肉眼看出精确坐标。
加网格辅助呢?作者也试了——给图片打上参考线,然后让 VLM 看着网格定位,再加自我审查循环不断纠偏。有效,但只对建筑、可交互元素这种「小目标」非常勉强地能用。对于「可行走区域」这种大范围、不规则的区域标注,几乎不可解。