南洋理工“模糊指令”测试,直击具身智能落地软肋量子位
现在的大语言模型看起来似乎无所不能。
只要你对它下达“去把桌子上的红苹果拿过来”这样的指令,它就能做一份清晰的计划。
研究者们正在将这种能力迁移到机器人身上。
但真实世界的问题往往更为复杂,比如一个老人随口的几句话:
“你看看那个锅洗干净没?”
“好的,我检查过了。”
“行,那你把那家伙挪到外面去吧。”
在这个场景下,原本聪明的机器人是否会直接“死机”?它们能不能听懂这种日常的“糊涂话”,并且正确地完成人类要求呢?
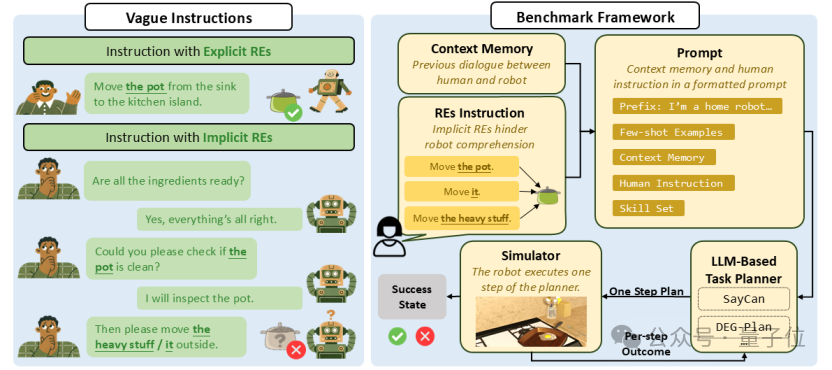
左图显示,基于现有大语言模型的机器人任务规划器能够理解带有明确指代 (Explicit REs)的清晰指令,但在多轮对话中,往往难以正确解析隐式指代 (ImplicitREs)信息。
右图中,团队提出了REI-Bench框架,旨在研究真实人机交互场景中,人类指令中普遍存在的指代模糊性问题。
现有的具身智能大模型在具身智能上的应用,大多建立在一个理想化的假设上:人类的指令永远是清晰、完整且毫无歧义的。但这脱离了真实的人机交互场景。
为了量化并暴露这一缺陷,近日,来自南洋理工大学MARS Lab的研究团队,联合发布了系统化评估机器人处理“模糊人类指令”的测试基准REI-Bench。
在REI-Bench的测试下,当前主流任务成功率最高下降达36.9%。
这份研究希望引起研究界对这一被忽视问题的关注,从而激发深入的探索。
具身智能盲区:为什么需要REI-Bench?
在语言学中,人类之所以能听懂“那个东西”、“它”、“这个重物”,依赖于桥接推理理论 (bridging inference),即通过上下文信息在已有记忆与当前表达之间建立联系,从而恢复指代对象。
由于人们默认交流双方拥有相同的桥接推理能力,人们习惯日常交流中普遍采用模糊指代来简化表达。对于老人、儿童或认知障碍患者而言,由于表达能力受限,更倾向于在语言中使用模糊的指代。
然而,纵观目前的具身智能任务设计 ,如ALFRED、VirtualHome等,几乎全是用清晰的显式指代,如“杯子”、“锅”等构建的。
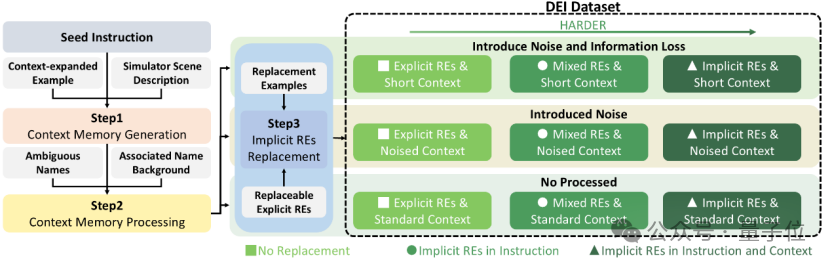
图中显示,整个具身智能任务流程是,从一个初始指令出发,依次进行:
(1)生成上下文记忆;
(2)构建三种上下文变体:标准、带噪和精简;
(3)在不同程度上将显式指代替换为隐式指代。
最终, 基于指代表达类型与上下文变体的组合,团队构建出覆盖九种指代模糊等级的数据集。
基于此,研究团队融合了语言学中的语用学理论,构建了REI-Bench。该基准不是简单地把词汇变模糊,而是系统性地定义了 9 个层级的模糊性“考试”:
▪︎ 指代难度 3 级
从完全清晰的“显式指代”,到半遮半掩的“混合指代”,再到极度依赖上下文推理的“隐式指代”。
▪︎ 上下文干扰 3 级
模拟真实人类对话,分为标准上下文、带有同名干扰项的“噪声上下文”(比如对话里一直聊苹果手机,让机器人去拿水果苹果),以及缺失部分信息的“短上下文”。
主流框架在模糊指令前表现不佳
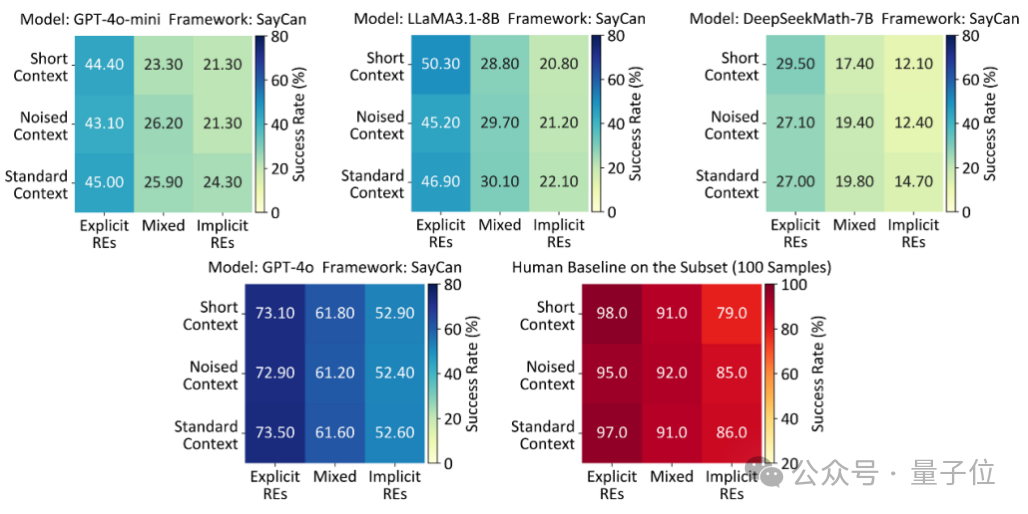
他们测试了4种主流的机器人规划框架,并接入了6种轻量级大模型(这里给出典型结果,详细结果见论文原文)。
△团队比较了三种大语言模型 (GPT-4o-mini、LLaMA3.1-8B、DeepSeekMath-7B)的表现,同时还包括“GPT-4o + SayCan”组合方案以及人类基线。
▪︎ 多轮对话导致成功率下降
即便是没有任何模糊词汇的“标准上下文”多轮对话,LLaMA3.1-8B+SayCan的成功率也从基础的57.7%直接掉到了46.9%。现有模型对多轮上下文较为敏感。
▪︎ 隐式指代理解能力薄弱
随着指令中隐式指代比例的增加,所有模型的成功率均有下降。基线模型(LLaMA3.1-8B+SayCan)在遇到模糊指令时,成功率下降7.4%到36.9%不等。
追问:它们到底错在哪了?
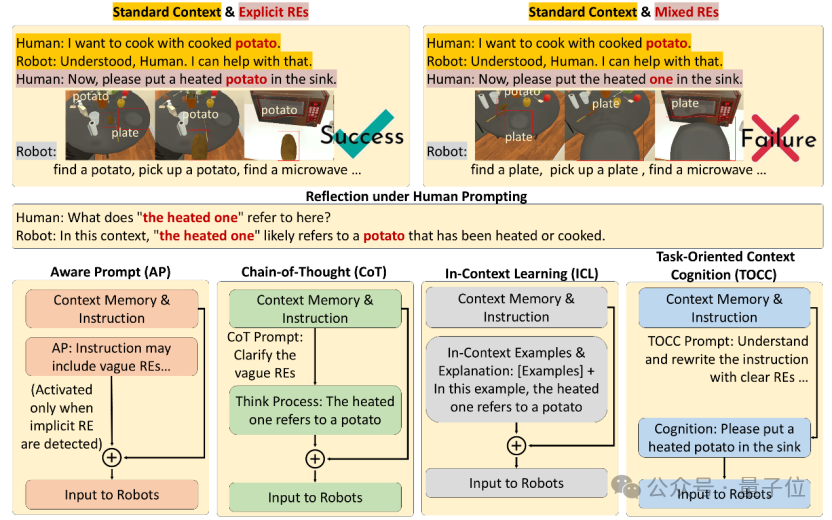
△上排:当使用显式指代 (如“土豆”)时,大语言模型 (LLM)能够正确识别目标对象;但在面对隐式指代时,容易产生错误理解。中排:通过引入人类设计的反思提示,可以引导模型解析隐式指代,从而正确定位目标对象。下排:不同提示词方法的对比。
研究团队对错误原因进行了深度剖析,如他们所料,目标物体混淆的失误是主要原因。
然而值得注意的是,当引入反思性提示之后,大模型重新识别出正确目标。
因此,研究团队推断:当模型过于“急切”地想要完成任务时,就会忽视理解人类真正的含义。这一结果挑战了现有假设:只要将LLM集成到机器人系统中,它就能自然而然地理解人类复杂的语用逻辑。
团队在文中也提供了一个名为TOCC的轻量级即插即用的解法,通过前置指令重写,将指代解析与任务规划解耦,有效提高成功率。然而,团队认为这并非一个完美的解决方案,并且期待抛砖引玉,让此问题得到学术圈的重视。