主动“认输”的DeepSeek,这次到底行不行?钛媒体
没有发布会,没有倒计时,DeepSeek V4就这样直接上线了。
这已经是DeepSeek惯用的节奏。但这次不一样的地方在于,他们在技术报告里主动写下了一句话:V4的能力水平仍落后于GPT-5.4和Gemini-3.1-Pro,发展轨迹大约滞后前沿闭源模型3至6个月。
这句话放在国内AI圈的语境里,显得有些格格不入。大多数模型发布,标配的是“全球领先”“行业第一”。DeepSeek反过来,主动划出差距。
但如果细看这次发布的内容,就会发现这并不是谦虚,V4压根没打算在“谁最强”这个问题上和GPT-5掰手腕。V4想做的,是把百万token的超长上下文变成所有用户的标配,同时把价格打到竞品的三分之一以下。
这篇文章我们想说清三件事:V4是什么、它能干什么,以及这次发布背后值得关注的信号是什么。
01.V4最大变化:超长文本全系标配
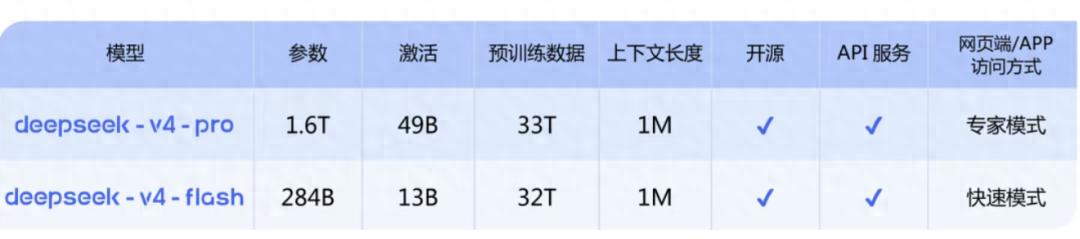
V4模型按大小分为Pro和Flash两个版本,在官方网页端和APP界面分别是专家模式和快速模式。
Pro是旗舰版,主打能力上限,对标的是GPT-5、Gemini这类顶级闭源模型,适合对效果要求极高的复杂任务。Flash是轻量版,速度更快、价格更低,推理能力接近Pro,但世界知识储备稍逊一些。
两款模型都支持同一件事,也是这次发布最值得普通用户关注的变化——百万token的超长上下文,全系标配,不分版本,不加价。
“上下文”这个词听着技术,简言之就是“AI一次能读多少内容”。按照100万token大约是75万汉字换算,差不多把整部《三国演义》喂给V4,它都能完整理解和分析。
这源于V4采用了CSA(压缩稀疏注意力)和HCA(重度压缩注意力)的混合架构。同样处理一百万字的内容,V4只需要前代模型四分之一的算力和十分之一的显存。
以前这个能力不是没有,但价格都很贵,得单独付费或者升级套餐。V4把它变成了所有用户默认就有的基础能力。对日常使用来说,感知最明显的一点是:使用者不再需要把一份长报告剪来剪去分段喂给AI,整份材料可以一次性丢进去,让它直接处理。
此外,V4提供了三档推理强度:
Non-think直出模式,AI直接给答案,适合简单问答和日常对话,速度最快;在网页和APP上关闭深度思考即可。
Think High是常规深度思考,AI会在脑子里推导一遍再回答,适合需要分析计算的场景;
Think Max则适合极难推理,但耗时更长,消耗的token大约是普通模式的两倍。思考的强度,由模型根据问题的复杂程度自动判断,或者使用者可以通过API参数手动指定为High或Max。
定价方面,V4延续了DeepSeek一贯的激进风格。
V4-Pro每百万token输入1元(缓存命中)或12元(缓存未命中),输出为24元;V4-Flash为每百万token输入0.2元(缓存命中)或1元(缓存未命中),输出为2元。
粗算下来,DeepSeek的定价大约是竞品的三分之一甚至更低。另外,V4同时支持OpenAI和Anthropic两种API接口格式,对开发者来说,切换只需要改一个参数,迁移成本几乎为零。
02.三个场景实测:长文本、写代码、复杂推理
在实际使用中,V4表现如何?我们围绕三个高频使用场景对其展开测试:长文本处理、代码生成与调试和复杂推理。
场景一:长文本处理
长文本处理是V4此次核心卖点,我们直接选用某上市公司2025财年年度报告作为测试材料。这份年报篇幅为324页,涵盖财务报表、附注及股东信息等多个模块,信息密度高、数据分散,是测试长文本理解能力的理想素材。
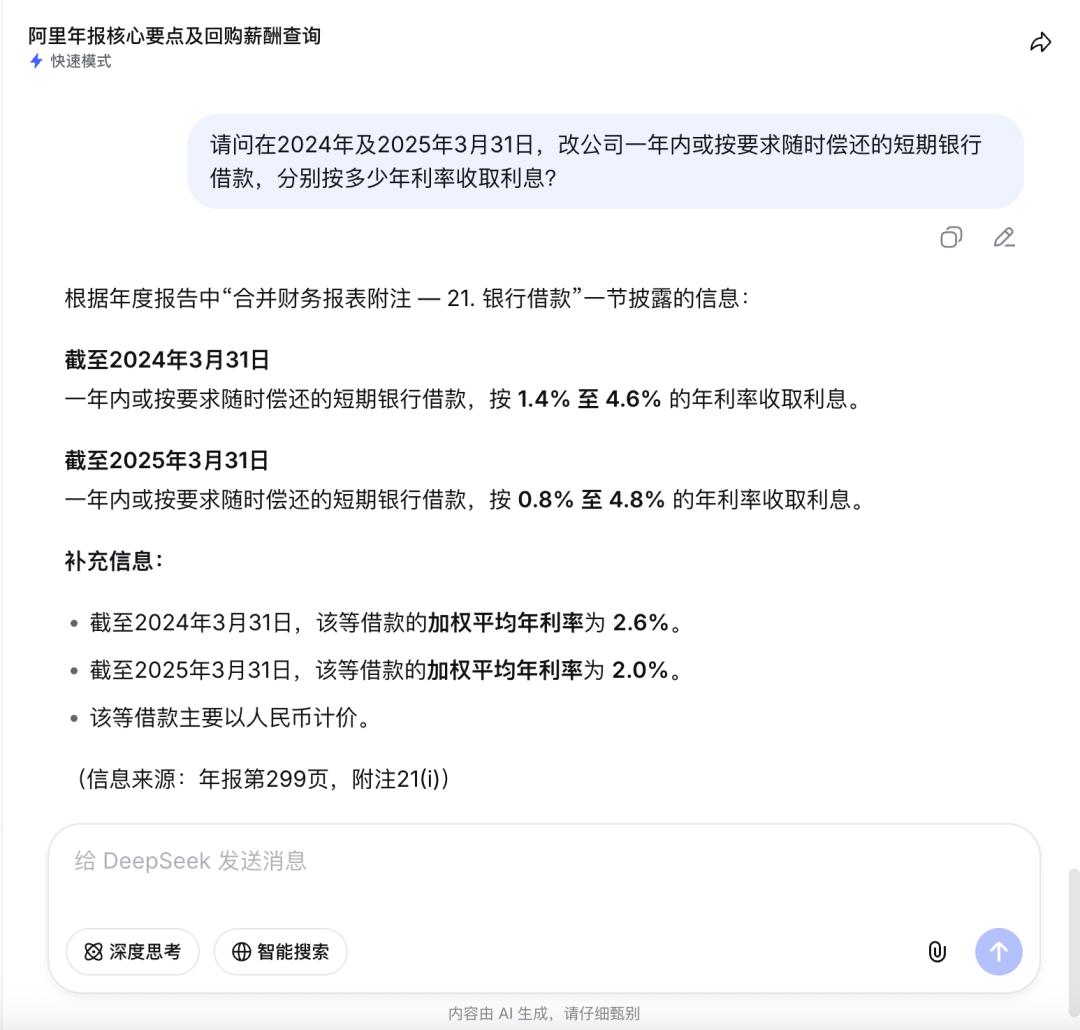
我们的测试问题分两层:第一层要求提炼年报核心要点;第二层追问两个藏在文档深处的具体数据——该年度回购股份的总数量与总对价,以及管理人员酬金排名第三的具体人员与金额。这两个问题的答案分别散落在年报第212至213页和第311至313页,位置偏后,必须完整阅读文档才能准确定位。
V4响应时间约19秒,给出的答案完全符合原报告。
此外,在追加提问短期银行借款利率区间时,我们关闭了“深度思考”,选择Non-think模式,V4同样准确找到年报数据,信息来源同样精确到页码。
从整体表现来看,快速模式下V4对这份300余页年报的处理相当稳定。数据定位准确、跨章节关联清晰、单位换算无误,且在回答过程中主动识别了潜在的口径歧义并加以说明,并没有因为文档体量大而出现答非所问或信息遗漏的情况。
对于需要快速从大体量文档中提取特定数据,V4的长文本处理能力已经达到了实际可用的水准,且在快速模式下便能完成,不需要开启深度思考来换取准确性。
场景二:代码生成与调试
这一场景我们分两步进行测试:
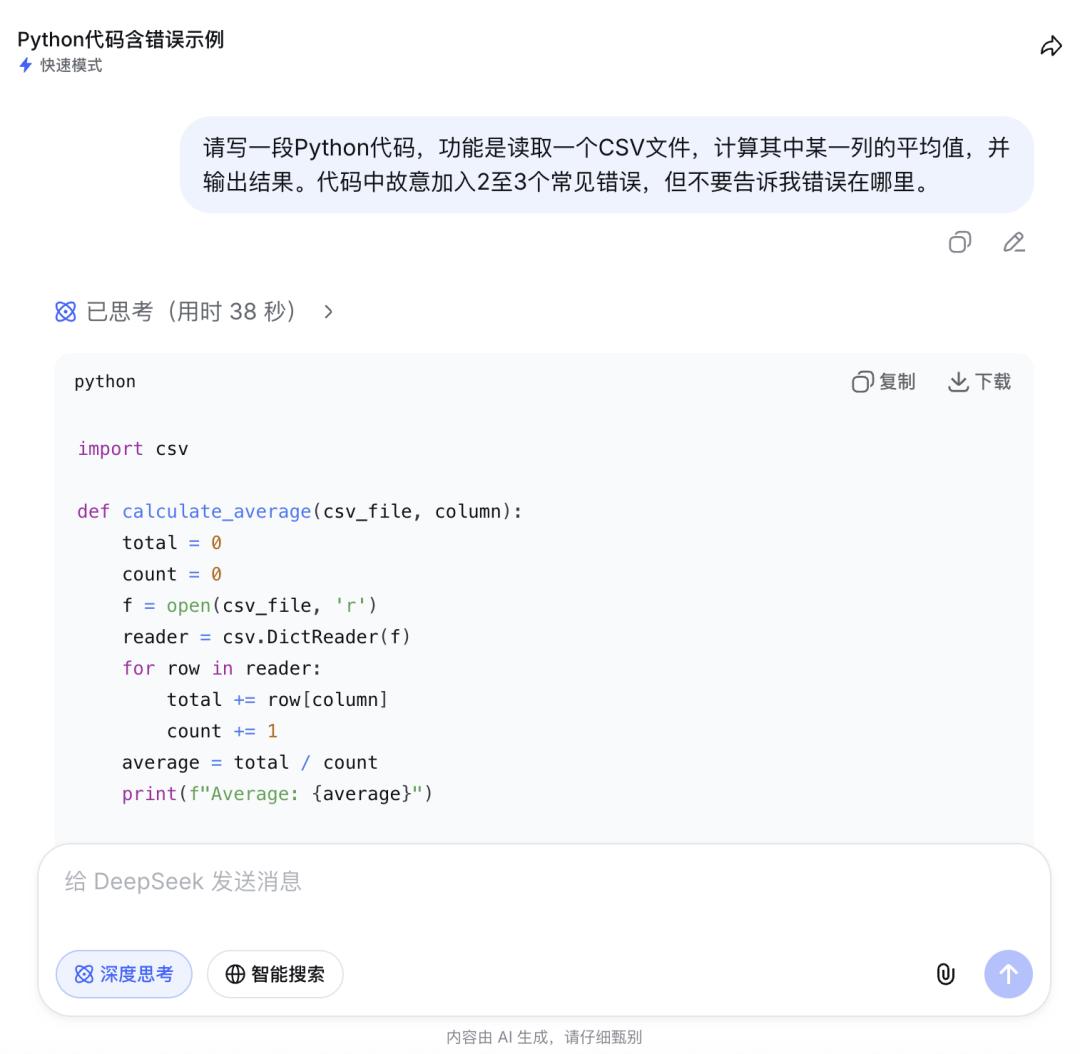
第一步,让V4生成一段含有隐藏Bug的Python代码,要求故意埋入2至3个常见错误但不提示位置;
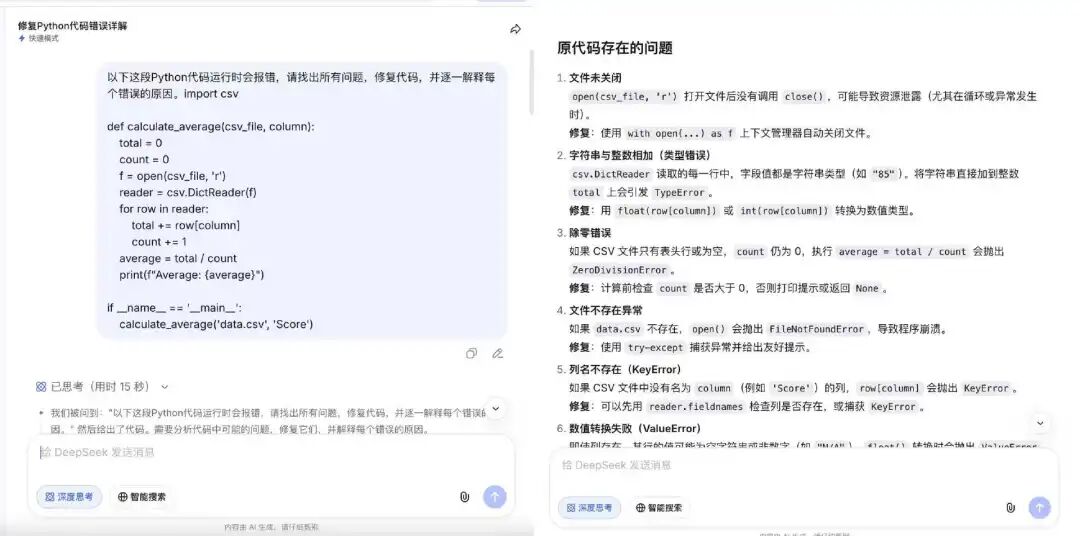
第二步,将这段代码重新交回V4,要求找出所有问题、修复代码并逐一解释原因。两轮分别在开启和关闭深度思考的模式下各跑一次。
开启深度思考模式响应时间15秒。V4在思考过程中主动梳理了代码的所有潜在问题,最终给出了6项错误分析,超出原题预设的2至3个范围。除了最核心的数据类型错误和文件未正确关闭之外,还额外识别出除零错误、列名不存在时的KeyError等。
关闭深度思考模式明显更快,直接输出结果,没有可见的思考过程。识别出的问题同样是文件未正确关闭、列数据类型错误、除零错误、列名不存在等,与开启深度思考的核心结论基本一致。
对于不懂代码的用户来说,日常的代码调试任务,关闭深度思考已经足够可用,速度也更快;如果是生产环境的代码审查,或者需要考虑各种异常边界,开启深度思考会给出更完整的分析。
场景三:复杂推理与分析
对于复杂推理测试,我们设定为一家中高端护肤品公司的经营困境分析:三年收入年均增长18%,但净利润率从12%腰斩至6%,同时面临库存积压、营销费用失控、电商渠道落后和竞争对手低价抢市等多重压力。
要求V4以商业顾问身份,识别核心问题、按紧迫程度列出三个优先风险并说明判断依据,随后在同一对话中追问:若公司决定优先发力电商渠道,可能面临哪些新风险。
深度思考响应用时9秒。V4在思考过程中先完成了问题拆解:将所有负面信号归类为现金流威胁、盈利能力恶化、市场结构性风险三个维度,再依据“若不立即处理会导致现金流断裂或持续亏损”的紧迫性标准完成排序,逻辑链条清晰可见。
最终它给出的三个优先风险依次是:库存积压与现金流风险排第一; 盈利能力持续恶化排第二,中端市场被抢占与渠道结构性短板排第三,并均给出了充分理由。