Claude官方下场:5招治好上下文腐烂新智元
给了100万token,现在却手把手教你怎么删记录!Anthropic官方承认:塞太多东西,Claude就会变蠢。面对失控的「上下文腐烂」,Anthropic连夜甩出5招救命指南。
Anthropic自己戳破了百万上下文神话?
近日,Anthropic一篇关于「如何管理百万上下文」的博客中再次提到了「上下文腐烂」(context rot)的问题,简单说就是:
上下文越长,模型越蠢。
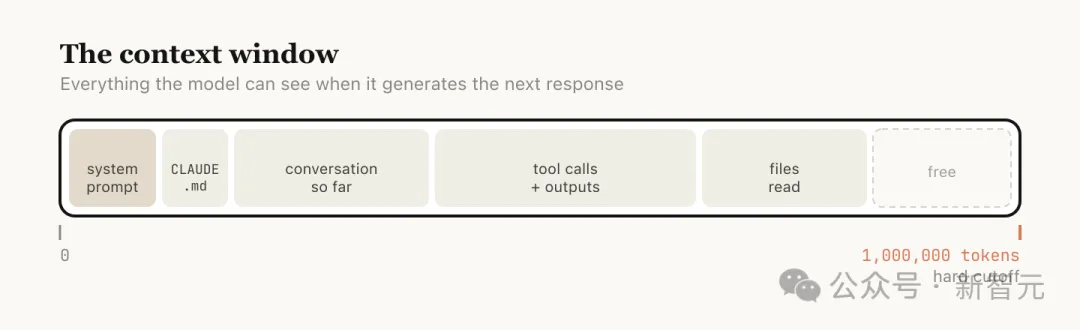
Anthropic解释道,上下文窗口是指模型在生成下一条回复时能够「看到」的全部内容,它包括你的系统提示、迄今为止的对话内容、每一次工具调用及其输出,以及所有已读取的文件。
目前,Claude Code的上下文窗口为一百万个token。
但上下文并非越长越好。模型的注意力被分散到更多token上,更早的、已经不相关的内容会开始干扰当前任务,导致表现下降,这就是「上下文腐烂」。
这并非社区自造的概念,而是出自Anthropic官方博客。
早在今年2月Sonnet 4.6发布时,公告里就写明了:Sonnet 4.6提供了测试版百万token上下文窗口。
但百万Token≠百万有效Token。
你往对话里塞的每一条消息、每一次文件读取、每一轮工具调用,都在稀释模型的注意力。
早期那些已经不相关的内容不会自动消失,它们会像噪音一样持续干扰当前任务。
提出问题后,Anthropic通过这篇博客给出了一套完整的管理方法。
先告诉你「你的对话在腐烂」,然后再手把手教你怎么治。
先把「上下文腐烂」的机制拆开看。
100万Token听起来很多。
一个中型代码库,连文档带源码,可能也就几十万Token。理论上你可以把整个项目塞进去,然后随便问。
但模型的注意力是有限资源。
你两小时前读的那个配置文件、一小时前调试失败的那段日志、半小时前探索的一条死胡同,全都还在窗口里,全都在抢模型的注意力。
这就是context rot的机制:模型被迫同时「记住」太多不相关的东西,没法集中精力处理眼前的任务。
也许你会觉得,这不就和人类开会开久了走神是一个道理嘛。
信息过载导致注意力稀释,这与能力无关,是带宽问题。
更要命的是,当上下文快要撑到100万Token上限时,系统会自动触发「压缩」(compaction):
即把整段对话总结成一个更短的摘要,然后在新窗口里继续工作。
这听起来很智能,但自动压缩发生的那一刻,恰恰是上下文最长、模型表现最差的时候。
用最蠢的状态去做最关键的总结,这事儿本身就很难靠谱。
每一轮对话都是岔路口
Anthropic在博客里把每一次对话交互定义为一个决策节点。
每一轮交互结束后,你其实站在一个岔路口,不是只有「继续聊」这一条路。
第一条:Continue。在同一会话中发送另一条消息,直接继续聊。上下文还相关,没必要折腾。这是最自然的选择,大多数时候也确实够用。
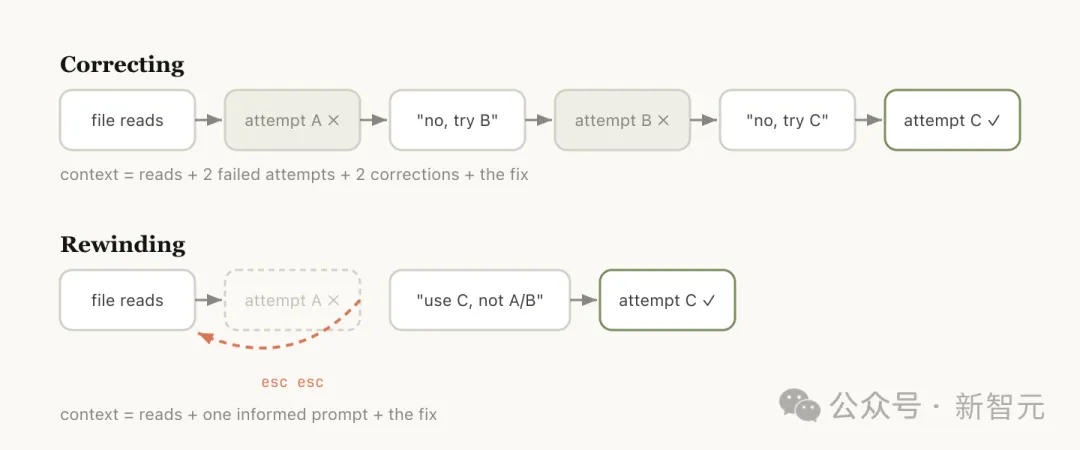
第二条:/rewind。 连按两下Esc,跳回之前某条消息,从那里重新来。
官方博客里有一个很精准的判断:与其纠正,不如回退。
回退(Rewind)通常是更佳的修正方式。
比如Claude读了五个文件,试了一种方法没成功,你的本能反应是说「这个不行,换个方法」。
但这样做的问题是,那次失败尝试的全部中间过程还留在上下文里,继续污染后续判断。
更聪明的做法是rewind到读完文件那个节点,带着新信息重新发一条更精确的指令:别用方案A,foo模块没暴露那个接口,直接走B。
有用的文件读取保留了,失败的尝试丢掉了。上下文干干净净。
你也可以让Claude总结它学到的内容并创建一条交接信息。这有点像未来的Claude给过去的自己留了一封信:这条路我试过了,走不通。
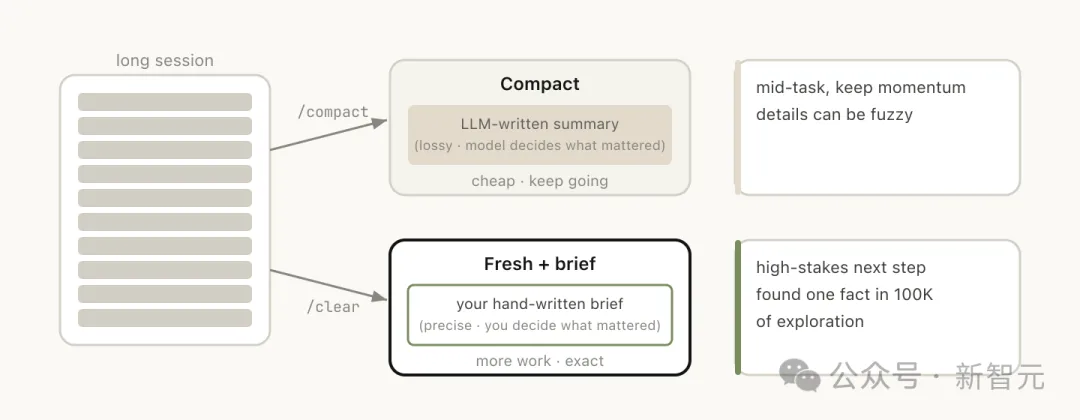
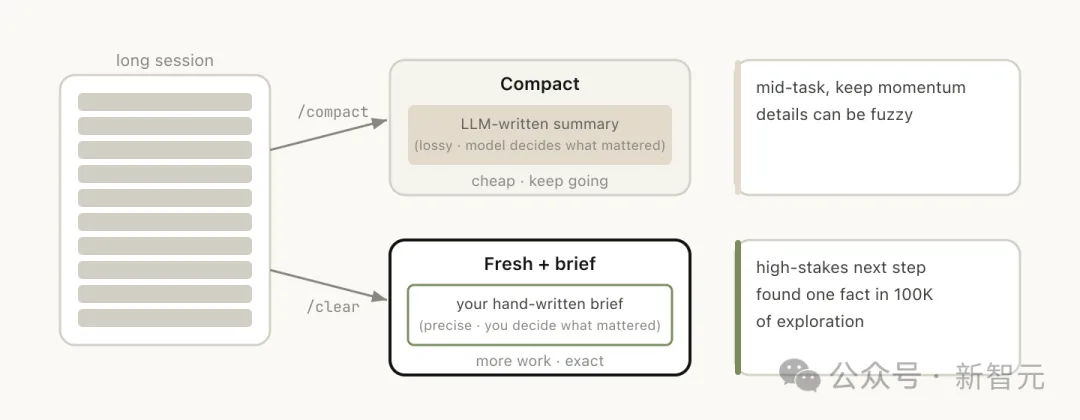
第三条:/clear。开启一个新会话,附带一段简要说明:之前做了什么、现在要干什么、哪些文件相关。
好处是零腐烂,上下文完全由你控制。坏处是费事,所有背景都得你自己写。
第四条:/compact。让模型总结当前对话,用摘要替换掉原来的历史记录。
省事,但有损。
你可以附上引导指令:/compact focus on the auth refactor, drop the test debugging(聚焦认证重构,删掉测试调试。)
让它知道什么该留什么该扔,而不是去猜。
/clear和/compact看起来相似,但行为截然不同:
/compact由模型决定什么重要,你省心但可能丢关键信息,而/clear由你自己写下关键内容,费事但精确。