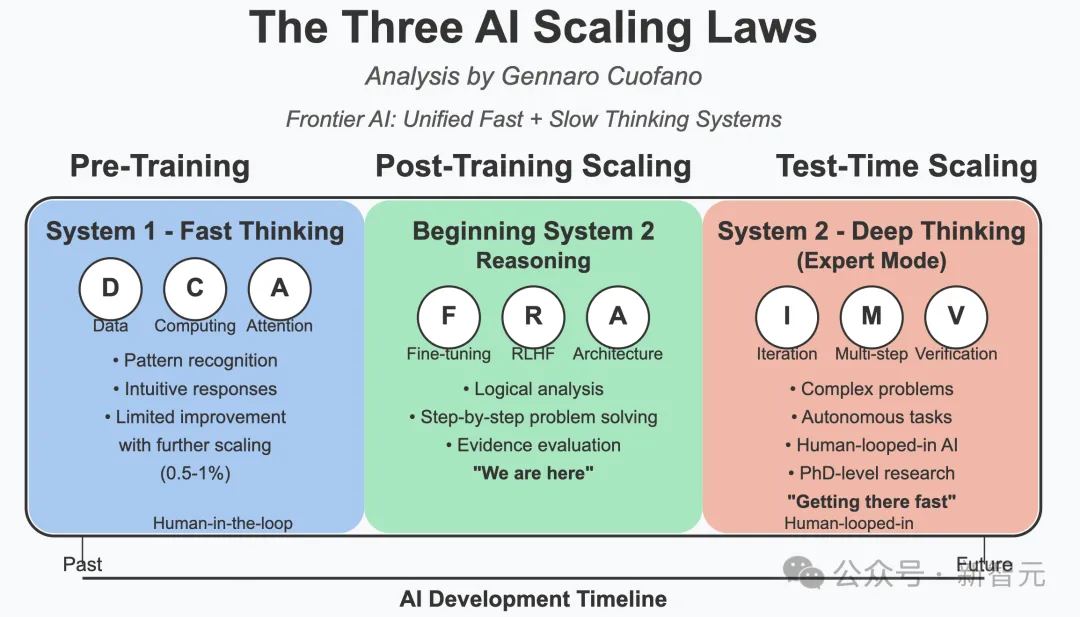
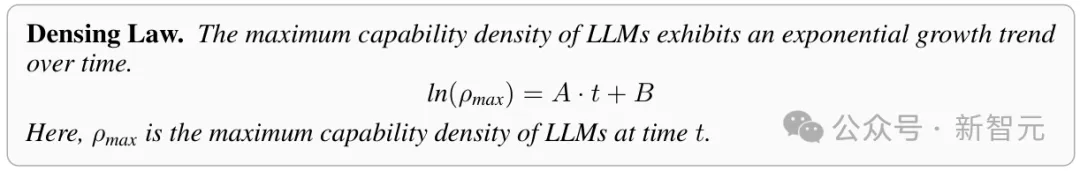清华2年前预言,正成为全球共识新智元
太疯狂了!Meta和METR刚测出的AI进化数据,与中国团队两年前提出的「密度定律」完美重合。硅谷猛然回头,发现中国研究者在这条路上已领先两年!
全球三家最严肃的AI研究机构,过去一周集体撞车了!
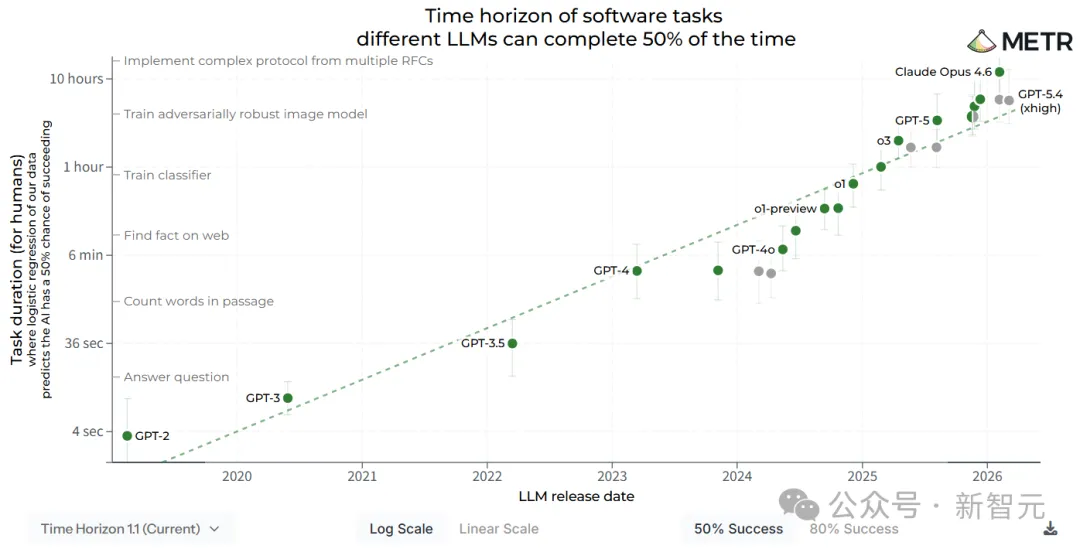
4月3日,美国研究机构METR悄悄更新了一份技术报告,核心结论压成一句话。
AI能力每88.6天翻倍一次。
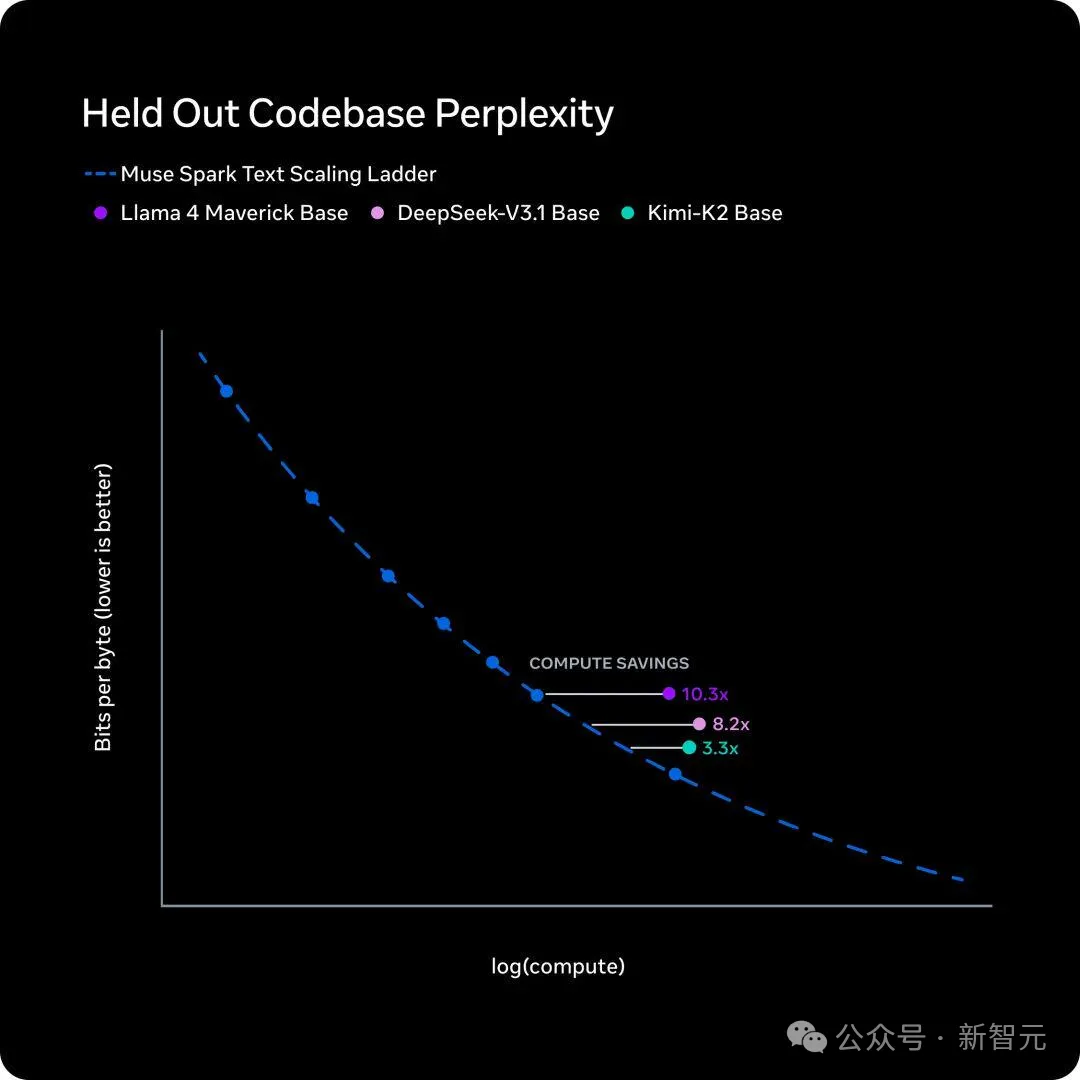
5天后,4月8日,Meta超级智能实验室发布全新模型Muse Spark,公开了一条内部叫做scaling ladder的训练效率曲线,结论也是一句话。
要追上一年前Llama 4 Maverick的性能,新模型只需要不到十分之一的训练算力。
一份测任务时长,一份测训练算力。两家机构没有任何往来,研究方法毫无重合。
但当两条曲线被换算到同一坐标系里,斜率几乎完全重合。
到这里,事情已经够离谱了。
更离谱的是,这条曲线,被一个中国团队两年前就完整地画出来过,还登上了Nature子刊。
它叫密度定律。
两年前,有人提前画过这条线
这个概念最早出现在一篇叫「Densing Law of LLMs」的论文里。
作者是面壁智能和清华大学的联合团队,孙茂松和刘知远两位教授领衔,第一作者是博士生肖朝军。
论文2024年12月挂上arXiv,2025年11月被Nature Machine Intelligence接收。
论文地址:https://arxiv.org/abs/2412.04315
论文地址:https://www.nature.com/articles/s42256-025-01137-0
论文的核心判断只有一句话。
模型智能密度随时间呈指数级增强,达到特定智能水平所需的参数量,每3.5个月下降一半。
放在2024年底,这话听上去有点过激。
那时全行业都在崇拜scaling law。OpenAI在堆模型,Anthropic在堆模型,Meta也在堆模型。
所有人都觉得参数越大智能越强,把GPU烧到极致才是正道。
但研究团队不这么看。
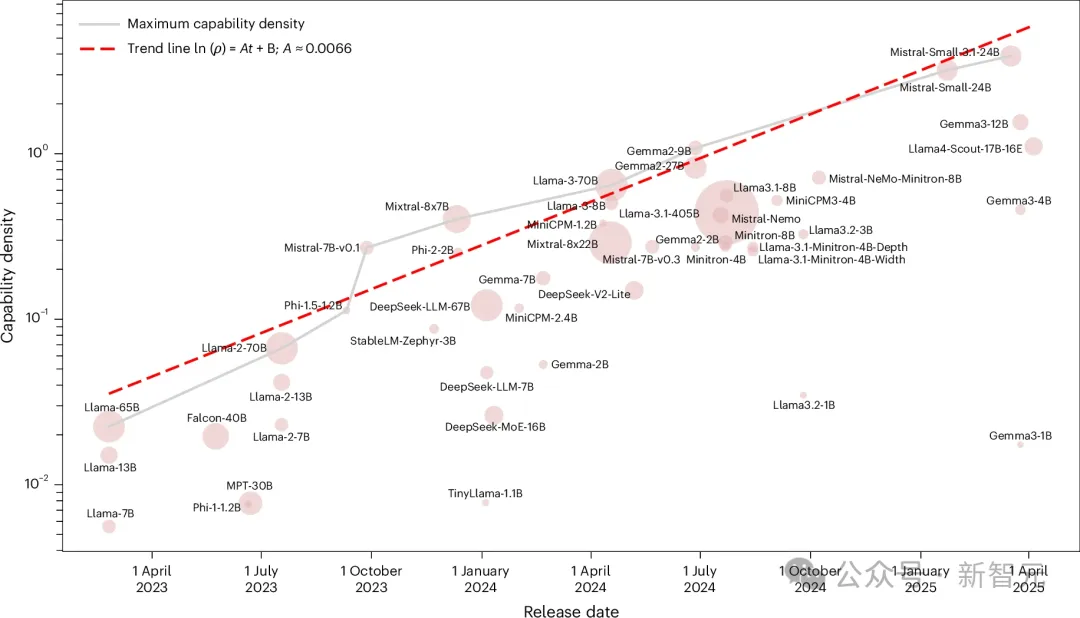
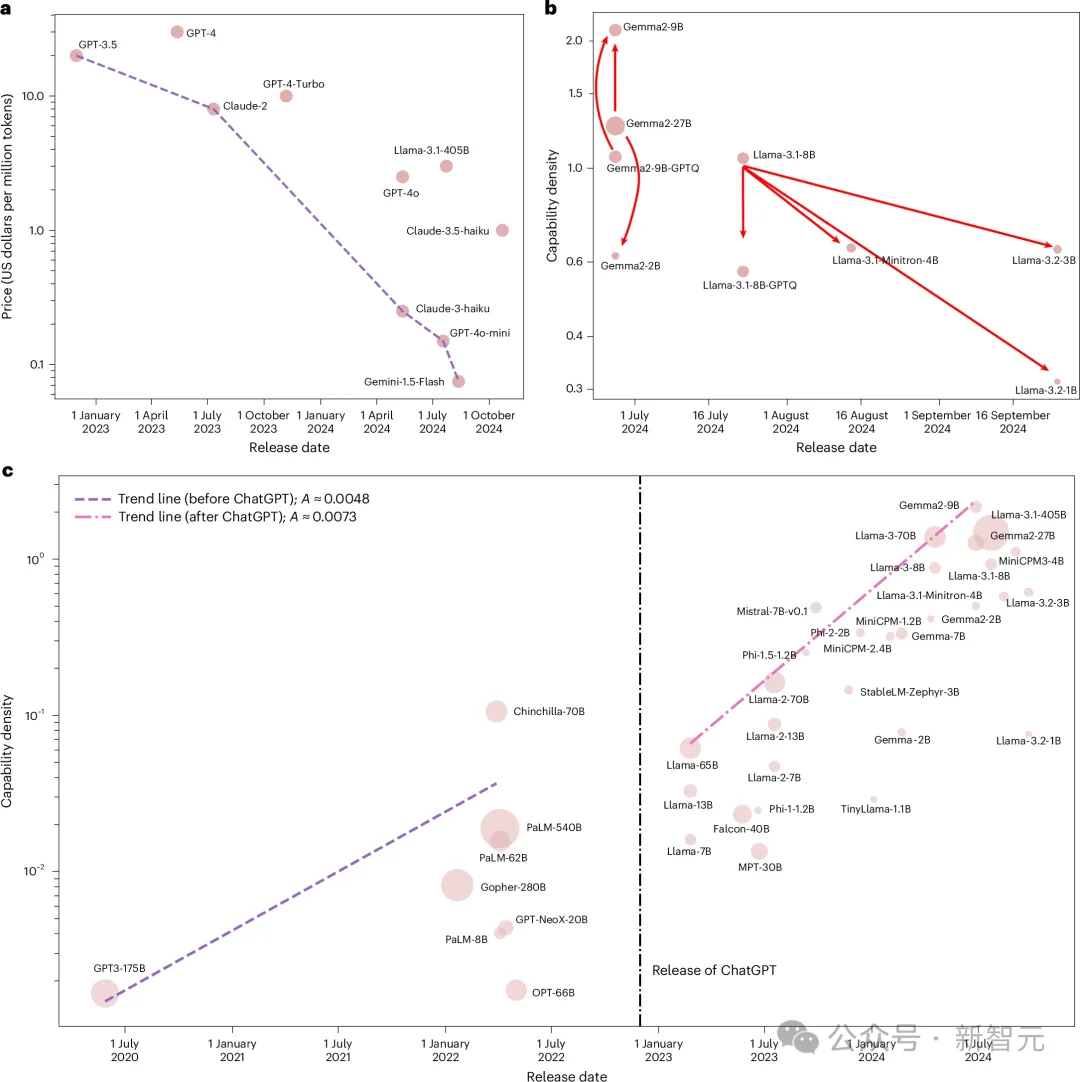
他们把当时所有有影响力的开源基础模型,从Llama-1一路到Gemma-2、MiniCPM-3,总共51个模型都放进了同一把尺子里去量。
五大基准跑完,结果是几乎完美的指数关系,R²达到0.934。
考虑到大模型评测很容易被数据污染干扰,他们又用一个新构建的污染过滤数据集MMLU-CF重测了一次。R²=0.953。
两次拟合都拿到了接近1的R²。统计学上,这几乎不可能是巧合。
换句话说就是,这两年发布的每一个主流开源模型,不管来自哪个团队、用什么架构,都落在了同一条「每3.5个月翻倍」的指数线上。
到这里,故事还只是「一个中国团队提出了一个看上去很激进的经验规律」。
真正让这件事变成一个「时刻」的,是接下来这小半年发生的事。
三家机构,三种方法,同一个斜率
把面壁、Meta、METR三方的结论摊开看。
面壁的密度定律衡量的是「同样的智能水平需要多少参数」。结论是参数需求每3.5个月减半。
Meta的scaling ladder衡量的是「同样的智能水平需要多少训练算力」。结论是Muse Spark比一年前的Llama 4 Maverick节省了一个数量级。
METR的时间跨度报告衡量的是「同样的模型能搞定多长任务」。结论是任务时长每88.6天翻倍。
三把尺子。三个学术机构。三种没有任何重合的研究路径。
但当所有数字被换算到同一坐标系里看时,它们的曲线斜率几乎完全重合。
这事最容易被忽略的一点是,密度定律是这三者里最早提出的。比Meta的scaling ladder早了近两年,比METR的完整建模也早了一年多。
而当Meta在四月初的发布博客里画出那条scaling ladder时,他们大概自己都没意识到。这张图的形状,和2024年北京一个学术会议PPT上的曲线,几乎是同一条线。
什么样的观察,才配得上「定律」两个字
在科学界,有一套不成文的标准,来判断一条经验观察是否有资格被叫做「定律」。
不是看数据有多漂亮,是看它能不能在多个独立的测量系统下同时成立。
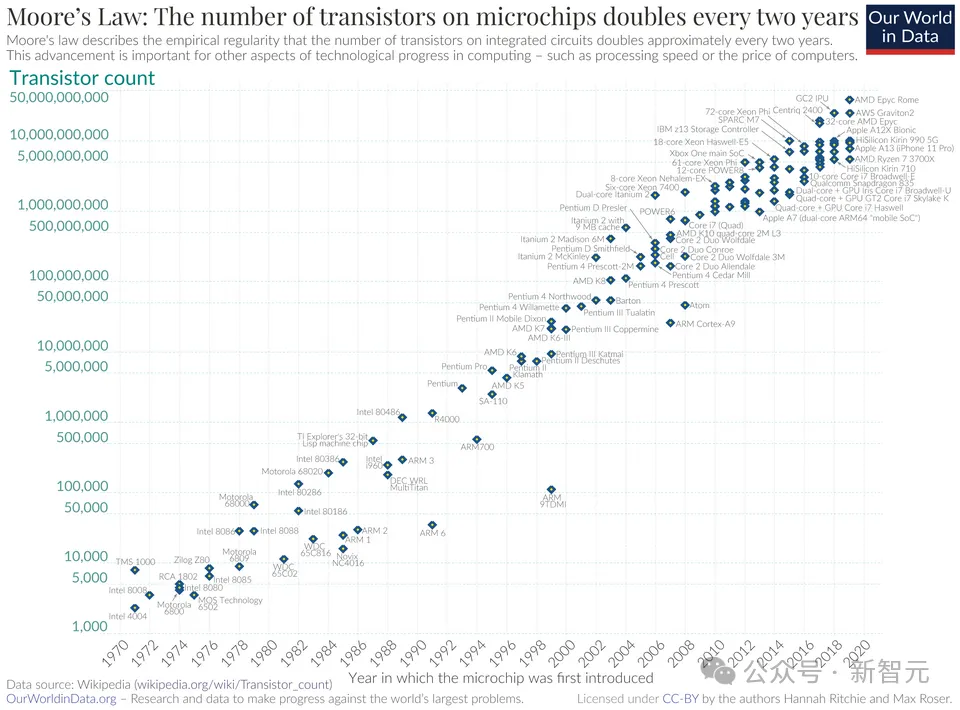
摩尔定律之所以是定律,因为半导体行业从光刻精度、晶体管密度、单位算力成本三个完全不同的维度,几十年来一遍遍验证过它。
密度定律走的是同一条路。
它最初只是来自单一团队的一条拟合曲线。到Nature子刊接收时,它已经能在污染过滤后的数据集上重现。到这个月,它在Meta的训练数据和METR的任务评测里又被两次独立验证。