纽约时报万字警告:AI正在制造“代码屎山”小智说AI
《纽约时报》发布重磅科技头条《The Big Bang: A.I. Has Created a Code Overload》(大爆炸:AI 制造了代码过载)。文章直指当前 AI 编程工具带来的一个极其恶心、但又被整个行业刻意回避的工程痛点:
代码屎山正在以十倍的速度膨胀。
自从 Cursor、Claude Code 以及各种开源 Agent 普及之后,写代码的门槛被无限拉低。但随之而来的,是一场让所有 Tech Lead 和安全工程师头皮发麻的灾难:代码产出速度彻底失控,人类根本审不过来了。
本文将从《纽约时报》的报道切入,结合本地真实项目,硬核拆解 AI 生成代码的 “Happy Path 陷阱”,并从架构、测试、自动化 Code Review 等多个维度,为你提供一份万字级别的 “代码屎山自救指南”。
第一章:产能爆炸的真相 —— 从 2.5 万行到 25 万行的噩梦
《纽约时报》在报道中引用了一家金融服务公司的真实案例:在全面引入 AI 编程工具之前,这家公司的研发团队每个月大约产出 25,000 行代码。这是一个非常健康的数字,意味着团队有足够的时间进行架构设计、单元测试、安全扫描和同行评审(Peer Review)。
然而,在全面引入 Cursor 和内部的 AI Agent 之后,这个数字飙升到了 250,000 行 / 月。
听起来像是个巨大的生产力飞跃?别急,噩梦才刚刚开始。
这多出来的二十多万行代码,直接把公司的 Code Review(代码审查)系统给干爆了。积压在队列里等待安全审查的代码超过了一百万行,安全工程师根本招不到足够的人来填这个坑。
为什么会这样?因为 AI 生成代码的速度,远远超过了人类阅读和理解代码的速度。
在传统的软件工程中,写代码其实是最快的一环。真正耗时的是:理解业务逻辑、设计系统架构、考虑边界条件(Edge Cases)、处理异常状态(Error Handling)、以及确保代码的安全性和可维护性。
当你用 Cursor 敲下 Cmd+K,或者在 Claude Code 里输入 “帮我写一个完整的用户注册模块,包含邮件验证和 JWT 登录” 时,AI 可以在 10 秒钟内吐出 500 行代码。
这 500 行代码看起来非常完美,变量名规范,甚至还带了注释。但作为 Reviewer,你要怎么审查这 500 行代码?
你需要逐行检查:
密码哈希用的算法是否足够安全?(比如有没有用 bcrypt 或 Argon2,盐值是怎么生成的?)
邮件发送失败时,数据库事务是否正确回滚了?
JWT 的过期时间设置是否合理?有没有处理 Refresh Token 的逻辑?
接口有没有做限流(Rate Limiting)防刷?
数据库查询有没有潜在的 SQL 注入风险?
人类工程师写这 500 行代码可能需要半天,他在写的时候大脑里已经过了一遍这些逻辑。但 AI 是 “吐” 出来的,它没有任何责任感。Reviewer 必须像排雷一样,用比写代码多得多的时间去审查这些代码。
当整个团队都在用 AI 疯狂 “吐” 代码时,Code Review 系统必然崩溃。
第二章:本地实测 —— 揭开 “Vibe Coding” 的遮羞布
为了直观感受一下这种 “产能过剩”,我刚才在自己的本地项目 xiaolongxia 里跑了一把脚本。
这个项目是我最近在折腾的一个基于 OpenClaw 的多渠道 AI Agent 框架。为了统计真实的业务代码量,我写了一条极其严苛的 find 命令,排除了所有的依赖库(node_modules)、Python 虚拟环境(venv 和 .venv-cover),只统计我自己的 TypeScript、Python 和 JavaScript 业务代码:
终端的真实输出如下:
整整 4.8 万行代码!
要知道,这只是一个个人维护的 Agent 框架。对于一个资深工程师来说,在没有 AI 的时代,业余时间手敲 5 万行高质量的底层框架代码,至少需要大半年的时间。
但可怕的是,这 4.8 万行代码里,有超过 80% 是我在这两个月里,用 OpenClaw 和 Cursor 疯狂 “Vibe Coding(凭直觉编程)” 生成的。很多底层逻辑、错误重试机制、甚至一些复杂的正则匹配,我根本就没有仔细看过。它只要在 Happy Path(理想情况)下能跑通,我就直接 git commit 了。
如果这是一个企业级的生产项目,这种极度缺乏敬畏之心的代码一旦上线,后果不堪设想。这 7490 行代码,就像是一个外表光鲜亮丽,但地基全是用纸糊的危楼。
第三章:硬核拆解 ——AI 代码的 “Happy Path” 陷阱
根据 4 月份最新的一份开发者调查,目前有 84% 的开发者每天都在使用 AI 编程工具。但令人讽刺的是,只有 29% 的人信任这些工具生成的代码,敢不经严格审查直接推向生产环境。
为什么大家不敢信?因为 AI 写的代码,太容易掉进 “Happy Path 陷阱” 了。
所谓 Happy Path,就是指一切条件都完美满足时的执行路径:网络永远畅通,数据库永远秒回,用户永远输入正确的数据,第三方 API 永远不限流。
AI 大模型在训练时,看过 GitHub 上无数的开源代码。但开源代码中,绝大多数都是 Demo 级别的实现,只覆盖了 Happy Path。真正处理极端边界条件、高并发锁冲突、缓存击穿的生产级代码,往往深藏在各大公司的闭源仓库里。
因此,AI 生成的代码,往往带着一种 “天真的乐观”。
我们来硬核拆解几个真实的工程灾难案例,看看 AI 是怎么把系统写崩的。
灾难案例一:缓存击穿(Cache Stampede)
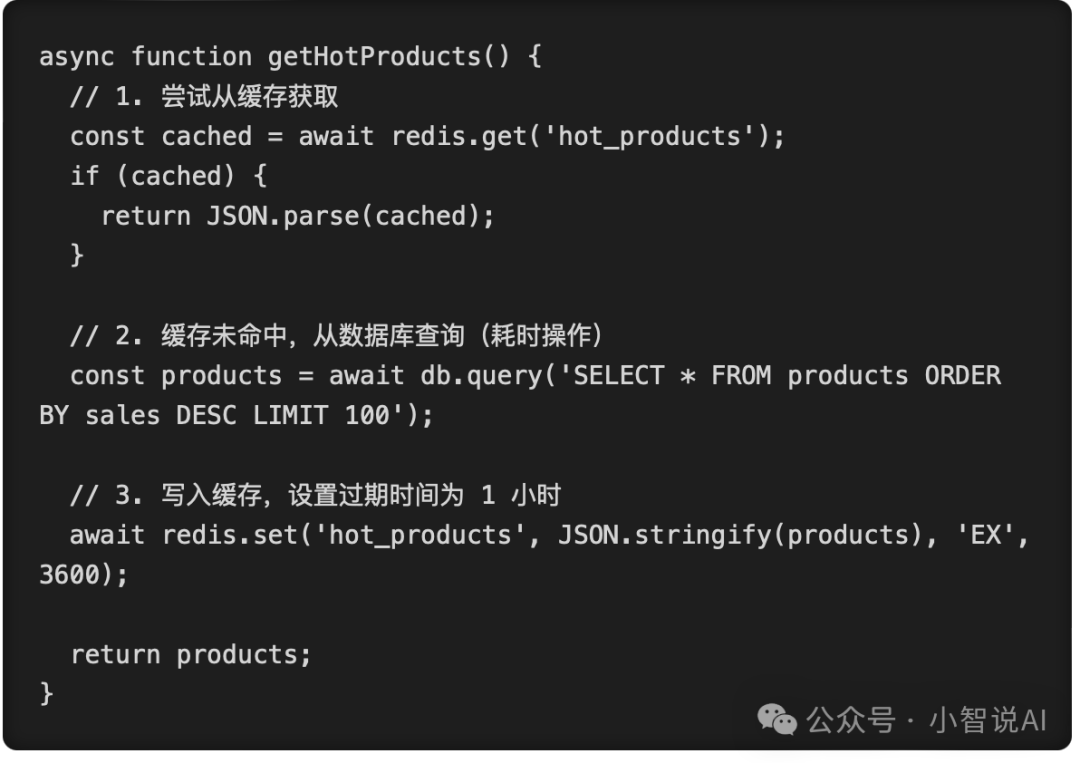
假设你让 Claude Code 帮你写一个获取热门商品列表的接口,并要求加上 Redis 缓存。
AI 生成的典型代码(Happy Path):
这段代码看起来非常完美,逻辑清晰,注释明了。在本地测试时,第一次请求查数据库,之后的请求全部走缓存,速度飞快。
但一到真实的生产环境,这就是个定时炸弹。
为什么?因为在电商大促期间,这个接口的 QPS 可能是 10000。当 1 小时的缓存过期那一瞬间,这 10000 个并发请求会同时发现 cached 为空。
于是,这 10000 个请求会同时越过缓存,直接砸向底层数据库,执行那个耗时的 ORDER BY sales DESC 查询。
数据库的连接池瞬间被耗尽,CPU 飙升到 100%,整个数据库直接宕机。这就是经典的 “缓存击穿(Cache Stampede)”。
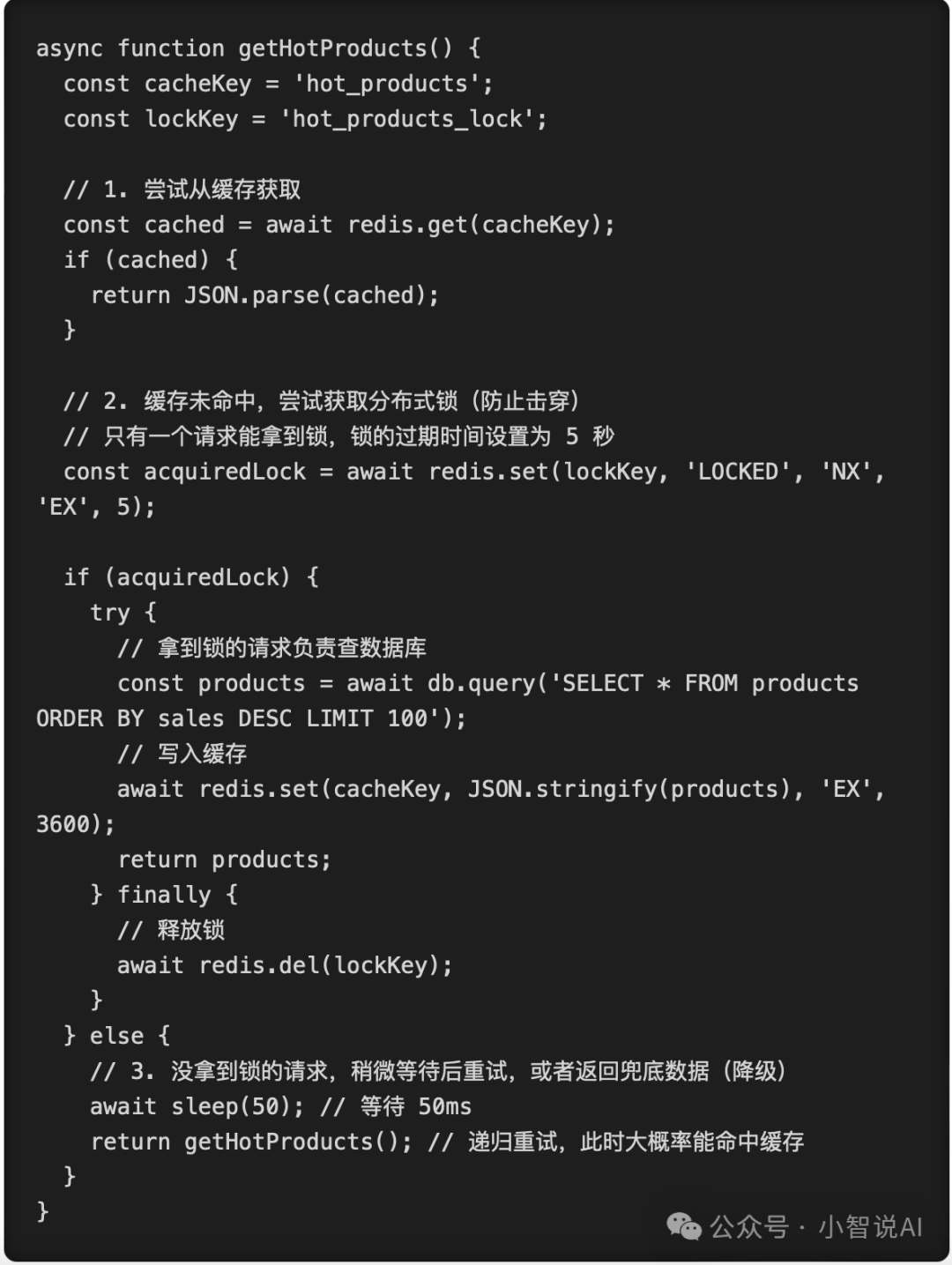
资深架构师会怎么写?(防御性编程):
你看,为了处理一个高并发下的边界条件,代码的复杂度瞬间提升了一个量级。引入了分布式锁(NX)、锁的过期时间、try...finally 释放锁、以及没拿到锁的自旋重试机制。
这种充满血泪经验的防御性代码,AI 除非你极其明确地在 Prompt 里要求(比如:“请使用 Redis 分布式锁解决缓存击穿问题”),否则它绝对不会主动给你写出来。它只会给你最简单的 Happy Path。
灾难案例二:缺乏幂等性(Idempotency)的支付接口
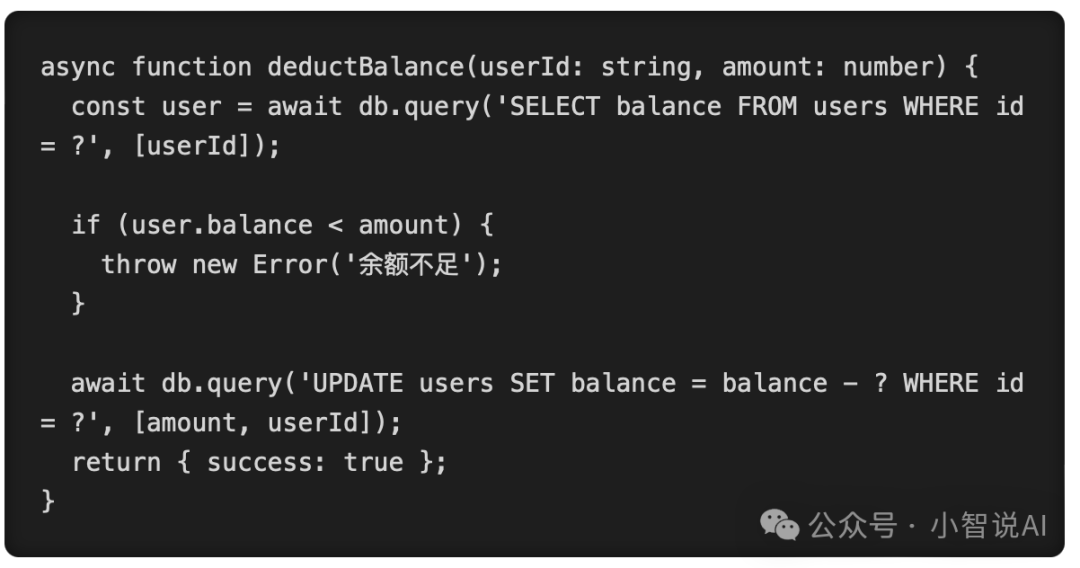
再来看一个更致命的例子。你让 Cursor 帮你写一个扣减用户余额的接口。
AI 生成的典型代码:
这段代码在本地跑完全没问题。但在生产环境中,如果用户的网络不好,点击了 “支付” 按钮后没反应,他又疯狂连点了 3 次。
前端发起了 3 个并发请求。这 3 个请求同时查询数据库,发现余额都是 100,都满足扣减条件。然后它们同时执行 UPDATE 语句。
结果就是:用户原本只有 100 块钱,却成功买到了 3 个价值 100 块钱的商品,余额变成了 -200。这就是经典的 “并发竞态条件(Race Condition)”。
更可怕的是,如果这是一个第三方支付回调接口,它完全没有考虑幂等性(Idempotency)。如果支付网关因为超时重发了两次回调,你的系统就会给用户充值两次。
资深开发者的写法:
加入了幂等性校验(transactionId)、数据库事务(beginTransaction)、以及悲观锁(FOR UPDATE)。