豆包「成精」了,一夜告别机械感新智元
AI交互的「机械感」消失了!今天,豆包甩出原生全双工语音大模型Seeduplex,不仅能边听边说,甚至能听懂你在思考时的「卡壳」,就算环境再吵也不怕,抗干扰能力直接拉满。
终于等来这一天!AI语音交互,终于像个人了。
今天,字节跳动Seed团队悄然出手——
原生全双工语音大模型Seeduplex正式发布,并已在豆包App全量上线。
注意,是全量上线。不是内测,不是灰度,不是「敬请期待」。
豆包的语音交互体验一直是独一档,和老罗辩论也不在话下。
但是从今天起,上亿豆包用户打开App的那一刻,就能直接体验到一种前所未有的感觉——
AI不再是那个等你说完一句、按一下、再说下一句的乖学生,而是一个会边听边说、会等你思考、会被你打断、还能听懂你咖啡馆里在聊什么的「对话搭子」。
这是一件被业内低估了的大事。
它意味着:全双工语音技术,第一次真正走出了实验室,在业界率先实现了规模化落地。
我们第一时间冲上去做了几轮实测。
说实话,体验下来只有一个感受:那种和AI说话时如鲠在喉的「机械感」,终于消失了。
那个总是「抢话」的 AI
终于像个真人了
通常来说,人与人的交互,存在着大量的信息交叠、打断、迟疑、环境噪音等。
传统的「半双工」语音AI,在面对这些复杂场景时,往往会力不从心——
要么在你刚停顿思考时强行抢话,要么在嘈杂环境中胡言乱语。
这一次,在保持极速响应的同时,Seeduplex啃下了「精准抗干扰」与「动态判停」的两块硬骨头。
想要上手非常简单,把豆包App升级到最新版本,进入后点击右上角打电话,即可开启「语音通话」的丝滑体验了。
场景一:咖啡厅里聊行程,精准抗干扰
假设进入一家人声鼎沸的咖啡馆里,和豆包讨论周末去哪儿玩。
背景里,邻桌大叔在大声讲电话,服务员的报单声此起彼伏,咖啡机在嗡嗡作响......
聊到一半,我顺手转向前台:「你好,我要一杯拿铁,不加糖」。
在这样吵闹的环境中,放在过去任何一个语音助手身上,几乎都是「车祸现场」——
要么把对别人说的话当成新指令一本正经地执行,要么直接卡壳中断,得重新喊一遍唤醒词才能接着聊。
令人惊喜的是,豆包没有抢话,并在嘈杂环境下保持极强的抗干扰力。
它只是安静地停了一下,等你把咖啡点完,然后顺着刚才的话题继续往下接,仿佛中间那段嘈杂从未发生过。
它不是单纯把背景噪音「降掉」,而是在持续聆听的同时,判断谁在对它说话、哪句话是主线交互、哪句话只是环境声。
这个差别非常大:前者只是声学降噪,后者已经开始接近「交互意图识别」。
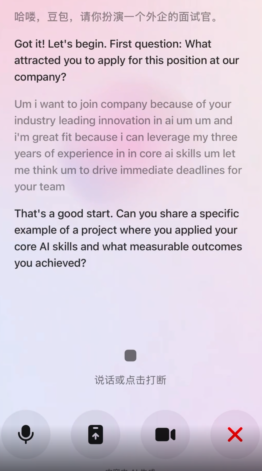
场景二:英文面试模拟,我故意卡壳了5秒
让豆包扮演一个外企面试官,然后故意在回答 「为什么申请这个职位」 时卡住——
... um... um... I'm a great fit because...
um... Let me think... um
真正的人类面试官会知道,你不是说完了,你只是在想。
这要是换做是以前的语音模型,早在每一次「um/uh」之后,火急火燎地跳出来接话。
结果,硬生生地把面试模拟变成「抢答比赛」,毫无一点沉浸感。
下面demo中,Seeduplex就像一个有涵养的面试官,始终安静地听我磕磕绊绊地组织语言,不急不躁,没有一次抢话。
直到我真正讲完,它才不紧不慢地递出下一个问题。
Seeduplex这次强调的「动态判停」,本质上就是解决这个问题:
它不再只靠静音时长来猜你是不是说完,而是把声学特征和语义状态一起纳入判断。
也就是说,它不仅在听你有没有停,还在判断你为什么停。这就是为什么全双工语音最关键的体验,并不只是「更快」,而是「更懂分寸」。
场景三:飞花令快问快答,逼它「秒回」
接下来,上一个更硬核的「极限挑战」——玩飞花令,试试豆包反应有多快?
「带『月』字的诗句,我先来:床前明月光,疑是地上霜」。
「举头望明月,低头思故乡」——几乎是话音刚落,下一句就精准空降
我:小时不识月,呼作白玉盘
AI:明月松间照,清泉石上流
我:明月几时有,把酒问青天
AI:月落乌啼霜满天,江枫渔火对愁眠
不得不说,这种对答如流、零延迟感的体验非常惊艳。