Meta亿元天团首个大模型:一雪Llama前耻量子位
再见了,所有的羊驼。
亚历山大王带队9个月从零重构Meta所有AI技术栈,在不断的质疑中交出超级智能实验室第一个模型:
主打原生多模态的Muse Spark。
模型发布后,Meta股价火速拉升约7%,中间一度涨超近10%,当日整体上涨6%左右。
市场的反应可谓相当热烈。
随手一扒你就会发现,这款模型背后藏着不少我们熟悉的高手:思维链作者Jason Wei、o1核心贡献者Hyung Won Chung、被小扎天价挖来的余家辉、扩散模型核心人物宋飏……
嗯?当这群人凑在一起,很明显你就会找到一个关键词:推理。
没错,据Jason Wei爆料,9个月前他们坐在一起讨论时,首先写下的就是一款用于推理的llama模型脚本,而现在,完全体终于诞生。
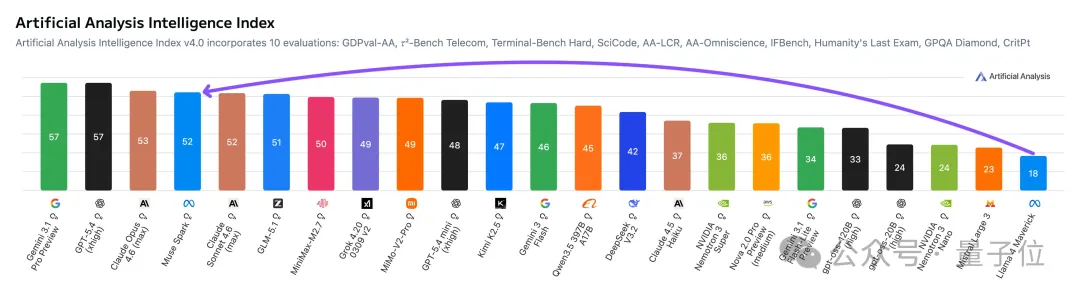
而顶尖高手+耗时9个月打磨,Muse Spark也总算让Meta在第三方测评中赶上第一梯队,一雪llama 4带来的前耻。
而且很有意思的一点是,Meta这次一反常态,没有反复强调自己拿了多少SOTA,而是稍显克制地表示:
Muse Spark在多模态感知、推理、健康和自主任务方面表现不错,但在编程和长时间自主运行方面仍与对家的顶尖模型存在差距。
咳咳,看来之前llama 4确实给Meta留下了心理阴影(doge)。
另外,Muse Spark的出生也终于让长期以来有关“Meta开闭源”的讨论盖棺定论:
这次是真闭源了。
目前这款模型已上线Meta网站和APP,API仅向部分合作伙伴开放。
(不过亚历山大王还是留了个口子,表示“计划未来开源后续版本”)
“Meta回来了”
老规矩,先看一波测评成绩。
作为Meta迄今最强大的模型,Muse Spark这次主要在三个方面表现突出:
一是多模态理解能力。
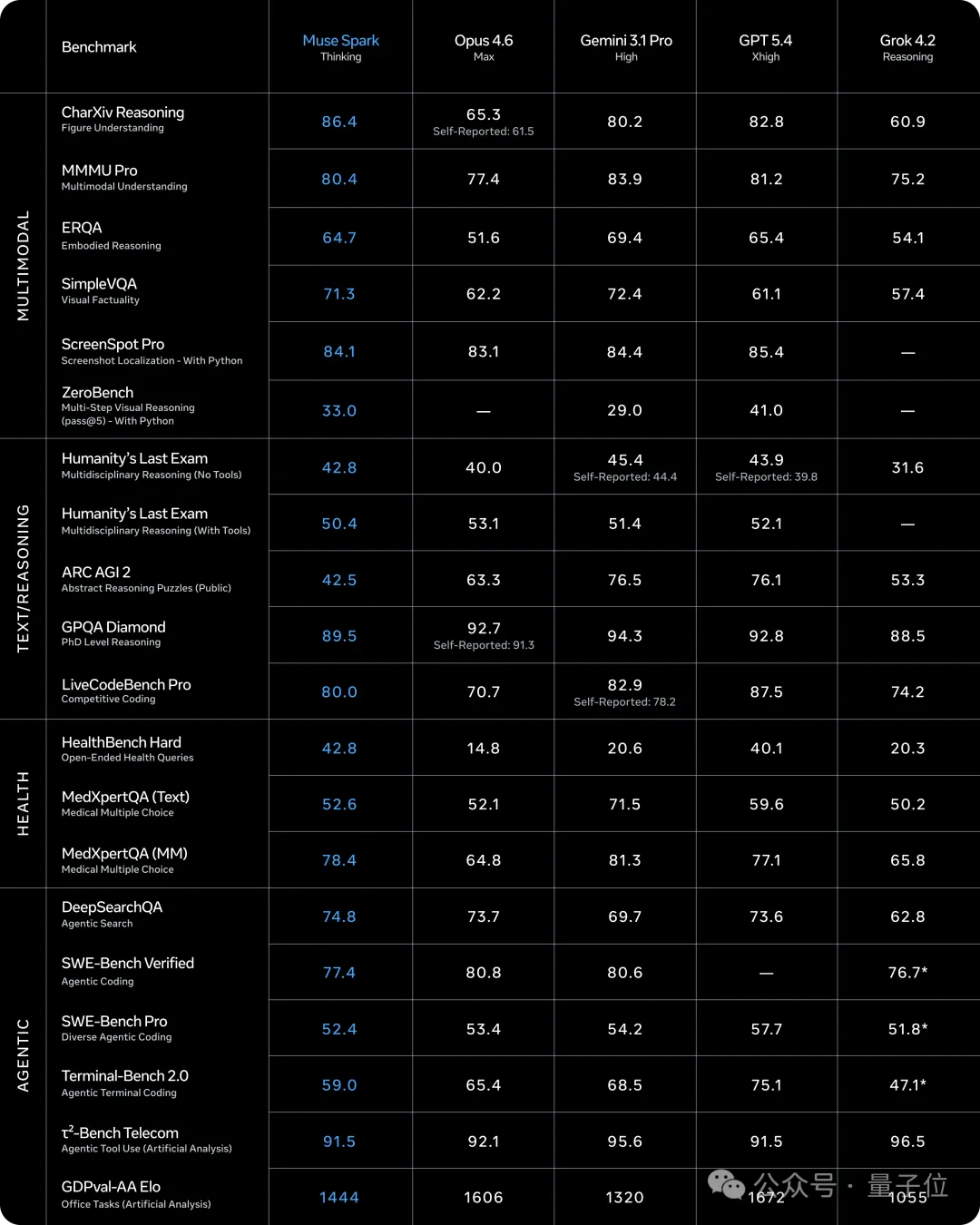
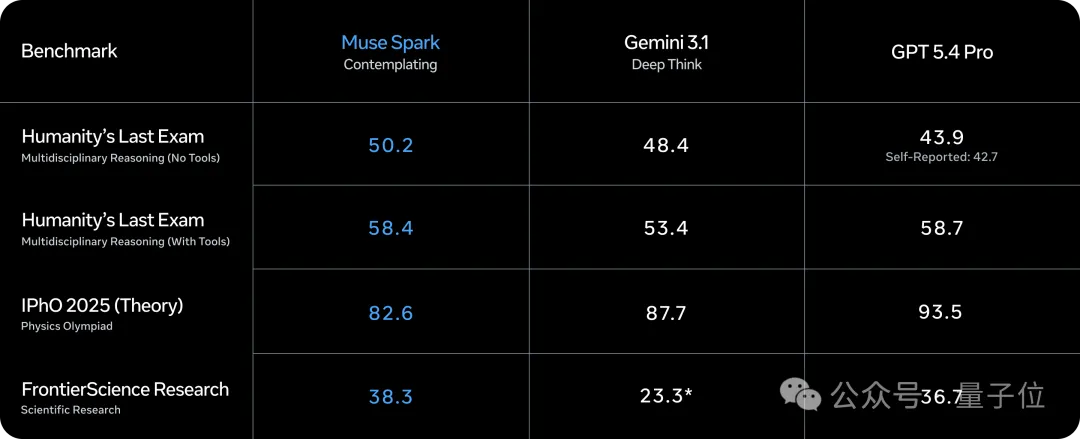
不管是看论文图表还是屏幕,各项得分要么第一、要么和Gemini 3.1 Pro、GPT 5.4等不相上下。
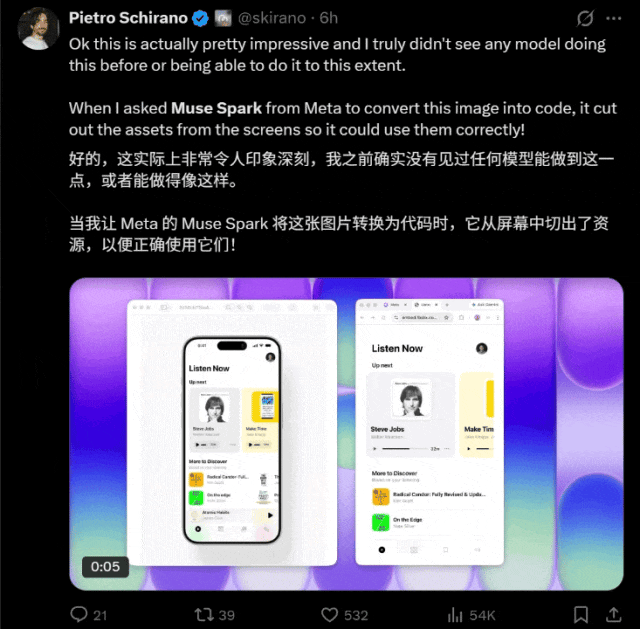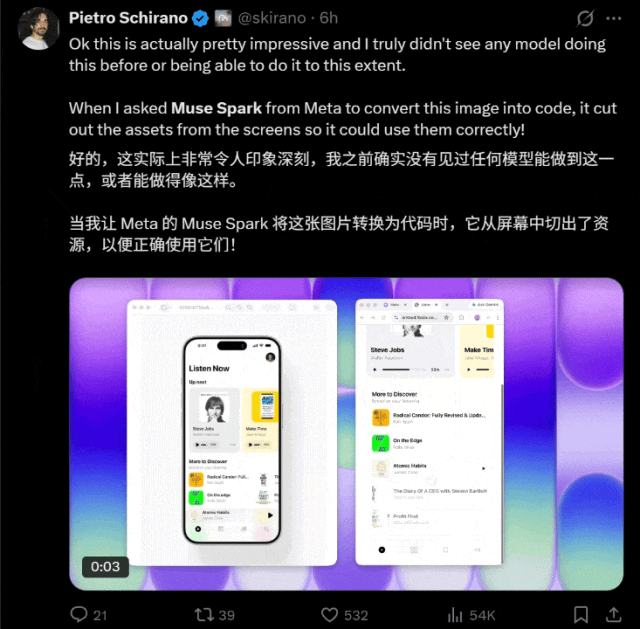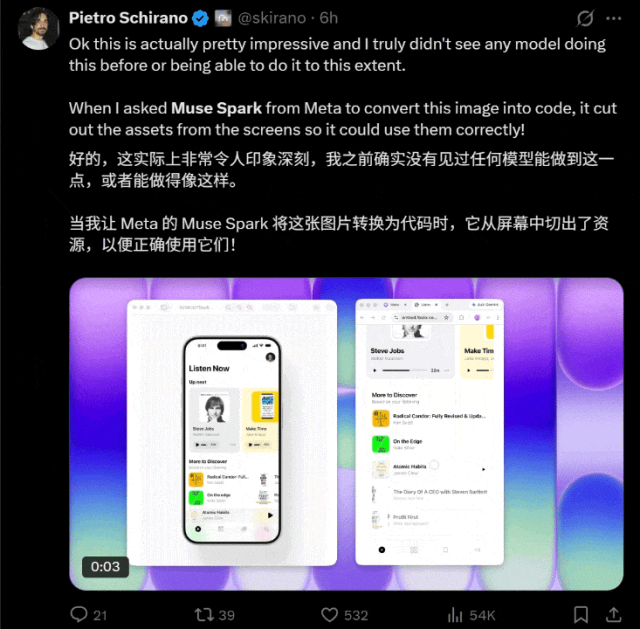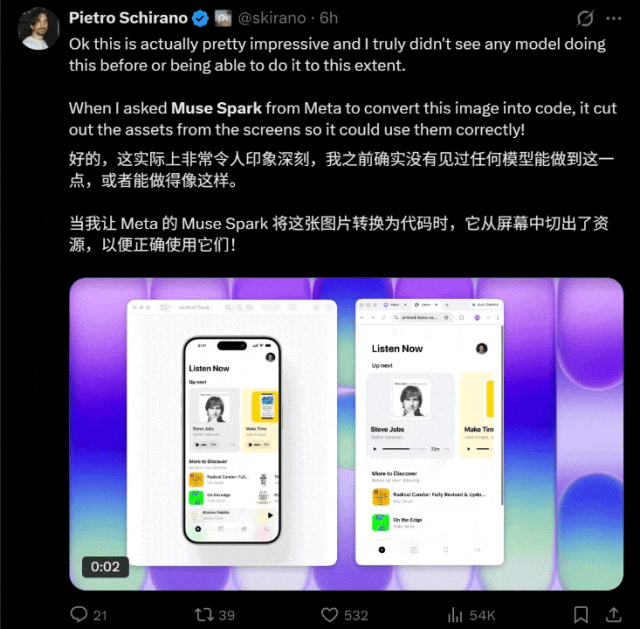
从网友们的测试来看,它好像尤为擅长图片转代码。
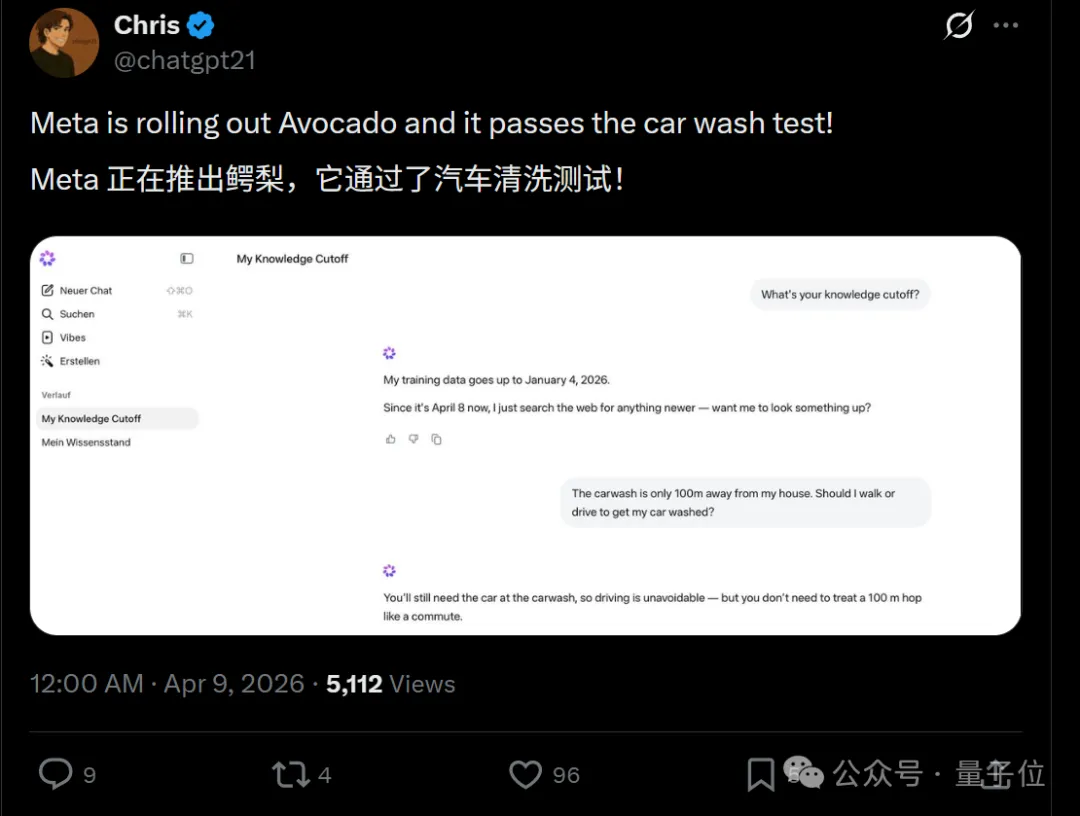
当然文本能力也不差(doge),在网友的激情测试中,它就火速通过了新版弱智吧风格的洗车测试。
100米外有个洗车店,我该开车去还是走路去。
Muse Spark:洗车当然要把车开过去,但没必要搞得跟上下班通勤似的。
(当然也不排除是数据污染的问题,毕竟问题出来也挺久了…)
再一个就是工具调用能力,测评情况也和多模态理解能力类似。
以及这次Muse Spark着重强调的医学能力。
由于和1000+医生展开了合作,它不仅在开放式健康问答HealthBench Hard上拿到42.8的最高分,而且在多模态医学问答MedXpertQA MM中位居前列。
不过短板我们开头也说了,Muse Spark仍在编程和Agent类任务上与其他顶尖选手存在差距。
可能也是为了尽量弥补这一点,他们这次还专门推出了Contemplating沉思模式。
主要是让多个Agent同时思考同一个问题,然后汇总结果找出最好的。
在这套打法下,Muse Spark就能和Gemini Deep Think、 GPT Pro这类极限推理模式展开正面PK了。
比如在“人类最后的考试”中,Muse Spark明显压过一头(不过在物理奥赛理论题中还是略逊一筹)。
(目前沉思模式正在Meta网站灰度测试)
另外值得一提的是,Meta这次无预告直接上线了“购物模式”。
亚历山大王表示,模型会结合用户在ins、Facebook、Threads上关注的创作者和品牌偏好,做个性化的购物推荐。
好好好,这次也不给你讨论的机会了,之前OpenAI可没少因为广告挨骂。