Claude Code更新后“翻车”华尔街日报
Anthropic旗下AI编程工具Claude Code遭遇严重口碑危机。来自AMD的AI总监在GitHub官方仓库公开提交问题报告,基于对数万条会话日志的量化分析,指控Claude Code自今年2月起出现系统性能力退化,思考深度骤降67%,模型行为全面走样。这一报告迅速在开发者社区引爆讨论,将Anthropic推上舆论风口。
提交这份分析报告的是AMD的AI团队负责人Stella Laurenzo。她在GitHub官方仓库直接开Issue,措辞严峻:"Claude已无法被信任来执行复杂工程任务。"她表示,团队已切换至其他服务商,并警告Anthropic:"6个月前,Claude在推理质量和执行能力上独树一帜。但现在,其他竞争者需要被非常认真地关注和评估。"
这一Issue在Hacker News上迅速发酵,获得975点支持和548条评论,成为近期Claude Code相关讨论中热度最高的帖子之一。网友评论直指问题核心——"ClaudeCode曾经像一个聪明的结对编程伙伴,现在感觉像一个过于热情的实习生,不停地把事情搞砸,然后建议最简单的临时方案";"最近总跟我说'你该去睡觉了。太晚了,今天就到这吧'这类话,一开始我还以为是我不小心让Claude知道了我的deadline。"
Anthropic对此作出回应。Claude Code团队成员Boris出面澄清,称思考内容隐藏功能(redact-thinking)仅为界面层面的改动,"不会影响模型内部实际的推理逻辑本身,也不会影响思考预算或底层推理运行机制"。
他同时承认,团队在2月进行了两项实质性调整:一是2月9日随Opus 4.6发布引入"自适应思考"(adaptive thinking)机制;二是3月3日将默认effort等级从高调整为中等(Medium)。Boris建议用户通过/effort high指令或修改配置文件手动恢复高强度思考模式。
然而,这一解释并未平息社区质疑。多位开发者表示,即便将effort调至最高,"急于完成任务"的摆烂行为依然存在。用户richardjennings称:
"在输出质量断崖式下跌之前,我完全不知道默认effort已经被改成了Medium。为了纠正这些问题,我大概花了一整天的工作时间。"
数据实锤:思考深度骤降,行为全面走样
Laurenzo的分析基于其团队在~/.claude/projects/目录下积累的6852个Claude Code会话JSONL文件,覆盖17871个思考块、234760次工具调用及18000余条用户提示词,时间跨度从2026年1月底延伸至4月初,全程使用Anthropic官方API直连Opus模型。
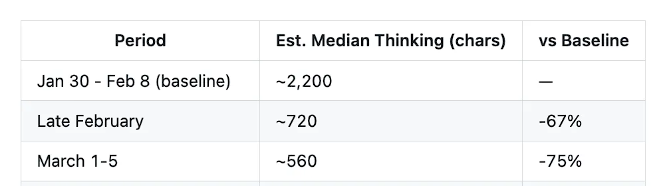
数据揭示了一条清晰的退化时间线。在1月30日至2月8日的"优质期",Claude Code的思考深度中位值约为2200字符;到2月下旬,这一数字暴跌至约720字符,降幅达67%;3月初进一步缩水至约560字符,降幅达75%。
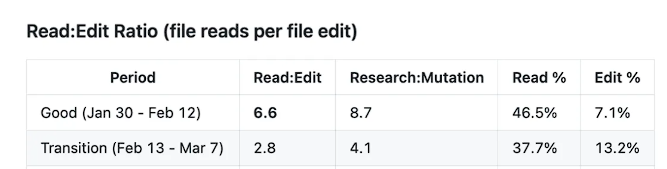
思考深度的崩塌直接引发了工具使用模式的根本性转变。在优质期,Claude Code修改代码前的"读改比"(每次编辑前的文件读取次数)高达6.6,遵循"先研究再修改"的严谨工作流。而到3月8日之后的"退化期",这一比率骤降至2.0,研究投入减少约70%。更触目惊心的是,退化期内每三次代码修改中,就有一次是在未读取目标文件的情况下直接进行的——这直接导致代码被插入错误位置、注释语义关联被破坏等低级错误频发。
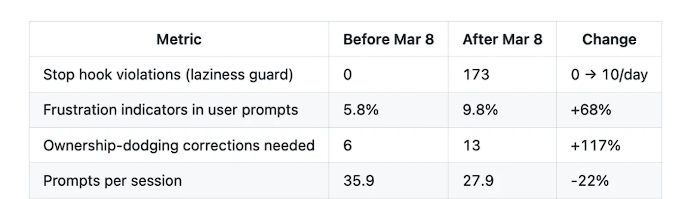
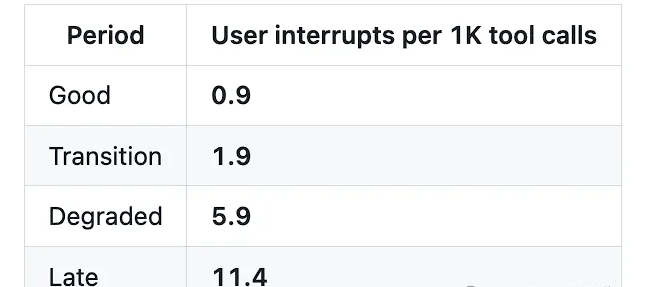
行为层面的量化指标同样触目惊心。用于捕捉"推诿责任、提前终止、请求许可"等不良行为的终止钩子脚本(stop-phrase-guard.sh),在3月8日之前从未触发;而在此后17天内,触发次数飙升至173次,平均每天10次。用户提示词中的负面情绪占比从5.8%升至9.8%,涨幅68%;用户中断率(即用户发现模型犯错并强行终止的频率)从优质期到后期飙升了12倍。
隐藏的"思考内容隐藏"功能:退化被刻意遮蔽?
Laurenzo的分析指出,上述退化与一项名为redact-thinking-2026-02-12的功能部署时间线高度吻合。数据显示,该功能从3月5日开始灰度上线(1.5%),至3月10日至11日已覆盖逾99%的请求,3月12日起全量生效。
这一功能的作用是在API响应中剥离思考内容,使用户无法从外部观察模型的实际推理过程。Laurenzo认为,这一设计客观上使思考深度的退化对用户变得不可见——"3月初上线的隐藏功能,只是让这一退化对用户变得不可见。"
她进一步指出,思考深度的下降实际上早于该功能上线,在2月中旬便已开始。这与Anthropic在2月9日推出Opus 4.6并引入"自适应思考"(adaptive thinking)模式,以及3月3日将默认思考等级调整为"Medium effort"(effort=85)的时间节点相吻合。
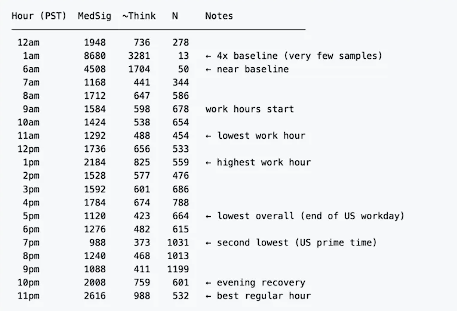
报告还发现,思考深度在隐藏功能上线后呈现出明显的时段波动特征——太平洋时间17:00(美国西海岸下班时段)是全天最差时段,中位估算思考深度仅423字符;19:00为第二差时段,仅373字符。
这一模式与固定预算分配不符,更接近负载敏感型动态分配系统的特征,暗示思考资源可能随平台负载实时波动。
Anthropic官方回应:设置问题,非模型退化
面对GitHub议题的快速发酵,Claude Code团队成员Boris在数小时内于GitHub和Hacker News双平台作出回应,承认了部分问题的存在并提供了技术解释。
Boris的核心澄清包括:
第一、思考内容隐藏功能(redact-thinking)属于UI层改动,不影响实际推理过程,用户可通过settings.json中的showThinkingSummaries: true选项恢复显示;
第二、2月下旬的思考深度下降,主要与2月9日Opus 4.6引入自适应思考机制(adaptive thinking)以及3月3日默认effort等级调整为中等有关,前者可通过CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING=1关闭,后者可通过/effort high或/effort max手动提升。
Boris还表示,团队计划测试将Teams和Enterprise用户的默认effort等级调整为高,并正在就部分用户反映的自适应思考机制在特定轮次分配推理不足的问题展开调查。
然而,这一解释在社区中引发广泛质疑。用户koverstreet回应称:
"问题远不止是默认思考等级被改成了中等。即便把effort调到最高,模型'急于完成任务'的摆烂行为也明显变多了。"
还有用户直接指出,原始报告的提交者在提交时已采用了所有已知的公开设置,问题并非配置不当。一位用户提出讽刺性反问:
"这是一种什么精神——告诉用户'你们调错设置了'"。
成本雪崩与用户出走
退化带来的代价不仅是质量损失,更引发了成本的灾难性膨胀。
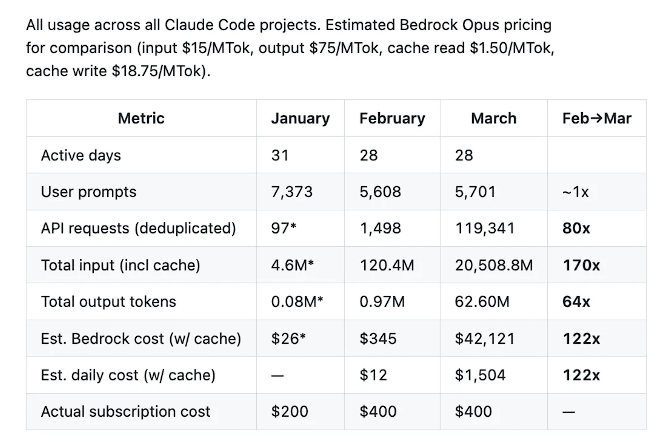
Laurenzo的数据显示,从2月到3月,其团队的用户提示词数量几乎持平(5608条 vs 5701条),但API请求量暴涨80倍,总输入token增长170倍,输出token增长64倍,按Bedrock Opus定价估算的月度成本从345美元飙升至42121美元,涨幅达122倍。
Laurenzo解释,成本暴涨部分源于团队主动扩容并发Agent数量,但退化本身造成的无效循环、频繁中断和重试,使每单位有效工作消耗的API请求量额外放大了8至16倍。团队最终被迫关停整个Agent集群,退回到单会话人工监督模式。Laurenzo写道:
"人类投入的工作量几乎没变,但模型消耗了80倍的API请求和64倍的输出token,却产出了明显更差的结果。"
在Hacker News的讨论中,大量用户表达了类似遭遇,部分人已宣布切换至OpenAI Codex或其他替代方案。"我已经取消了订阅,切换到了Codex";"现在用Qwen3.5-27b,虽然不如两个月前的Opus那么锋利,但我们又能正常推进工作了。"
用户自救:临时应对方案
面对退化,部分开发者已摸索出若干临时应对策略。
在CLAUDE.md中明确授权是最常见的做法——通过在项目根目录的配置文件中写入"你有权编辑本项目任何文件""不要在重构时请求确认"等指令,可在实践中将安全中断频率降低约70%。
将复杂任务拆解为边界清晰的子任务,也被广泛验证有效。相比"重构整个认证系统","仅重构auth.js,完成后输出变更摘要"这类有明确边界的指令,能显著减少模型的提前终止行为。
在设置层面,将effort调至high或max,并通过CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING=1禁用自适应思考,是目前官方认可的最直接干预手段。
Laurenzo则在报告中提出了更系统性的诉求:Anthropic应公开思考token的分配情况,推出面向复杂工程工作流的"满额思考"专属订阅档位,并在API响应中暴露thinking_tokens字段,让用户能够自主监控推理深度是否达标。