让Agent把成功经验固化成skills:跨模复用100%量子位
AI会用工具了,问题才真正开始…
这两年,大模型Agent在“用工具”这件事上进步很快。搜索、查信息、调API,很多模型已经能把一串操作接起来,完成相当复杂的多步任务。
但一旦把场景拉近到真实工作流,问题很快就会显现出来。很多任务表面上不同,底层流程其实高度相似:先搜,再筛,再整理,最后再做一点汇总分析。换一个对象,这套流程往往又要完整走一遍。
麻烦在于,现有Agent虽然会做这些事,却不太会把已经做成功过的流程留下来。
圆满完成任务后,再遇到同样任务它还是会重新规划、重新传参、重新走一遍工具链。结果就是:任务也许做成了,但token越跑越多,上下文越来越长,成本和不稳定性也一起上来了。
为解决该问题,近期一项由NIPS时间检验奖得主等参与的新研究——SkillCraft,在圈内自发形成了一定热度。该研究尝试回答这个很具体的问题:Agent能不能把已经跑通的工具链,逐渐变成以后还能继续用的skill。
SkillCraft让Agent工具“越用越熟”
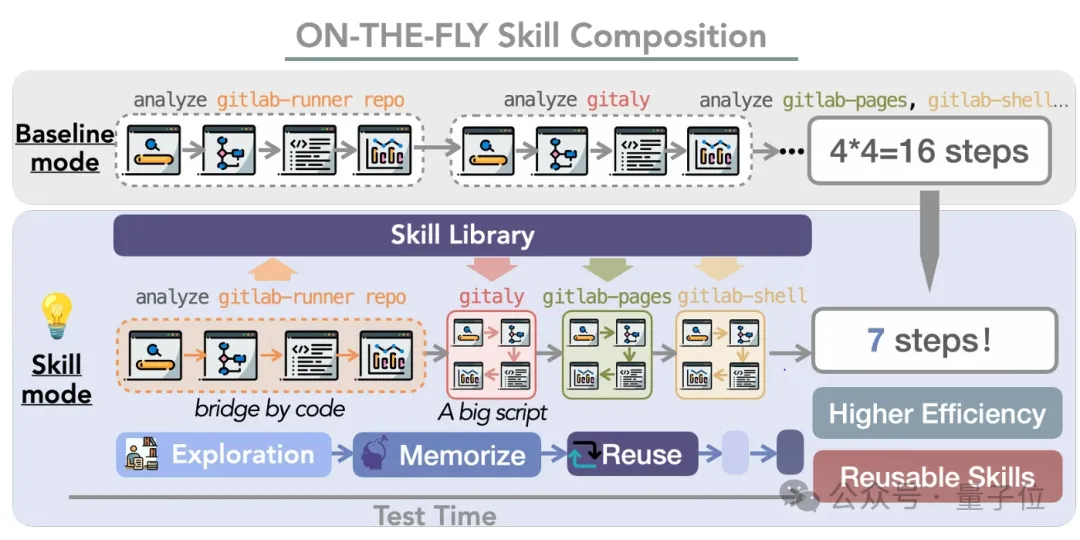
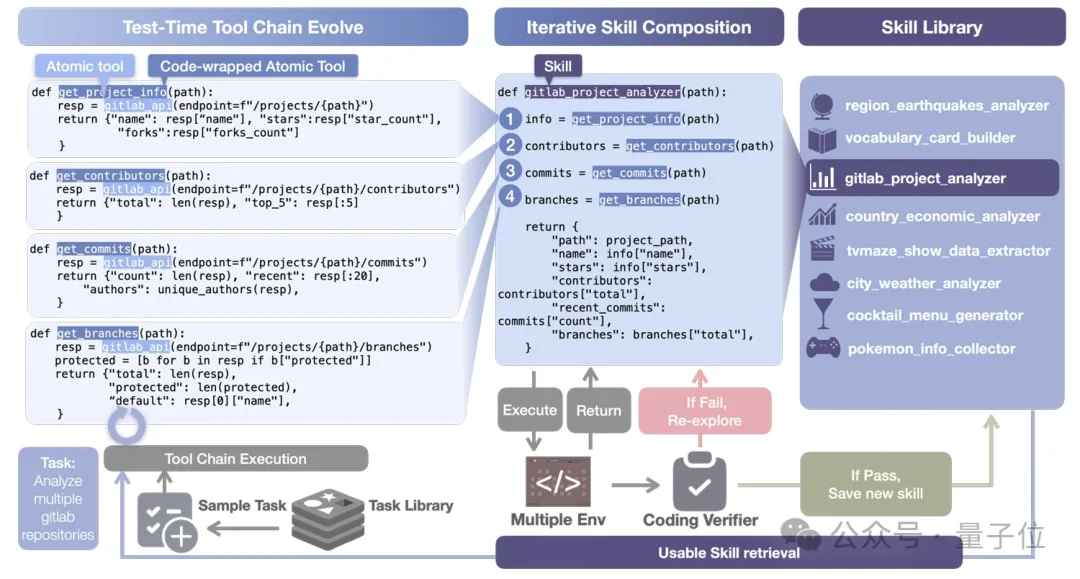
SkillCraft的核心思路是:让Agent在测试时一边做任务,一边把反复有用的工具链整理成skill。
这个过程可以理解成四步:
1、先看看库里有没有现成的skill能用
2、没有的话,就先按老办法用原子工具把任务做出来
3、做出来之后,把这条成功轨迹抽象成一个带参数的skill
4、最后过一遍verifier,再放进skill library
这个设计的妙处在于,它不是简单“记住答案”,也不是给模型多塞一段提示词。
它做的是更进一步的事:把经验变成一个能执行、能复用的高层操作单元。
让Agent在完美完成一个任务后将可行方案归纳整理,从而在下一次遇到类似问题时,快速复用已有的可行路径。
固化成功流程,收益立竿见影
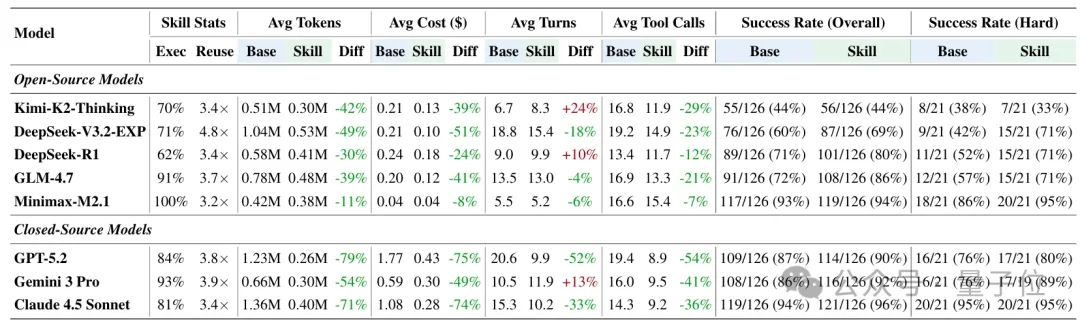
论文结果显示,在引入skill保存与复用后,多数模型都出现了明显收益:
token更少
工具调用更少
成功率通常提升或者持平
一旦允许Agent在测试时保存并复用skill,多数模型都会出现比较明显的收益:工具调用更少,token更低,成本下降,成功率提升
以GPT-5.2为例,Skill Mode下的成功率从87%提升到90%,平均token从1.23M降到0.26M,成本也从1.77美元降到0.43美元。这说明,skill的保存和复用不是一个可有可无的小技巧,而是会真实影响agent表现的能力。
换句话说,SkillCraft最有价值的地方,不是单纯证明“skill这个概念有意义”,而是证明:一旦Agent真能把成功流程保存为可复用的技能,效率和表现都会切实提升。
技能树不能只追求深度
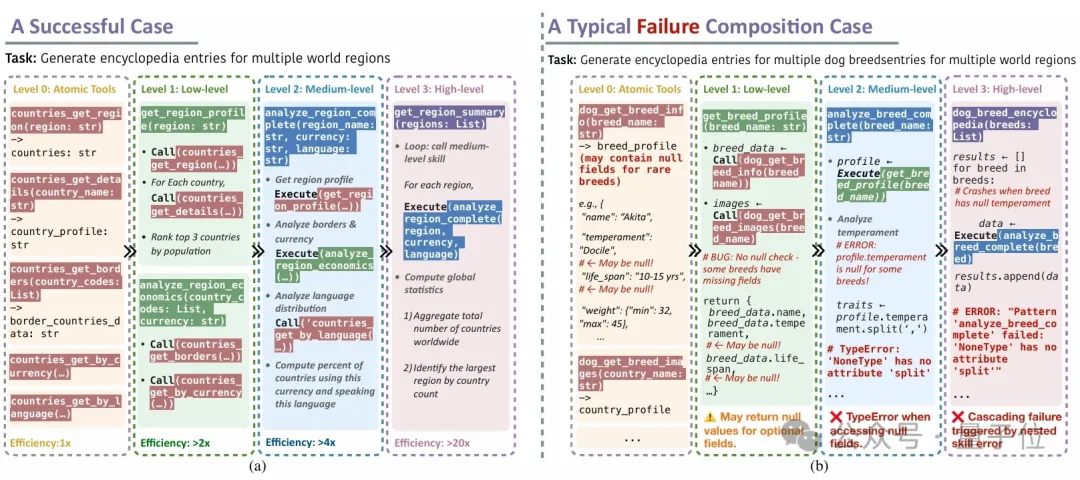
论文测试了hierarchical skill composition,允许agent通过在skill内部调用已有skill的方式,实现更复杂的skill。结果发现:
层级更深,未必更稳
低层bug会向上级联
一个边界条件错误,可能拖垮整棵技能树
这说明现阶段更实用的路线,可能不是自动生成越来越深的技能树。
而是优先构建高质量、浅层、可验证的skill library。
不只当前任务,还有“技能迁移”
SkillCraft的另一个亮点,是它还评估了skill的泛化能力。
研究发现,高质量skill不仅在当前任务能用,在很多情况下还能:
甚至跨模型复用
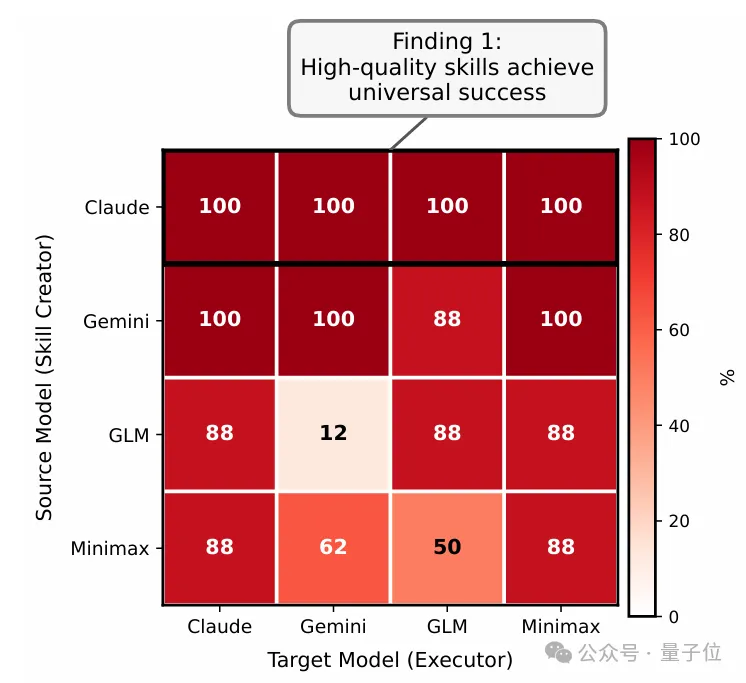
以下两张图展示的,正是跨模型skill reuse的两个关键结论。
通过skill跨模型复用的Success Rate Heatmap,团队发现:
由更强模型创建的skill,往往能在不同执行模型上都保持较高成功率
最典型的是Claude这一行,四个执行器上都是100%;
真正高质量的skill往往具有较强的可迁移性,而不是只能被创建它的那个模型自己使用。
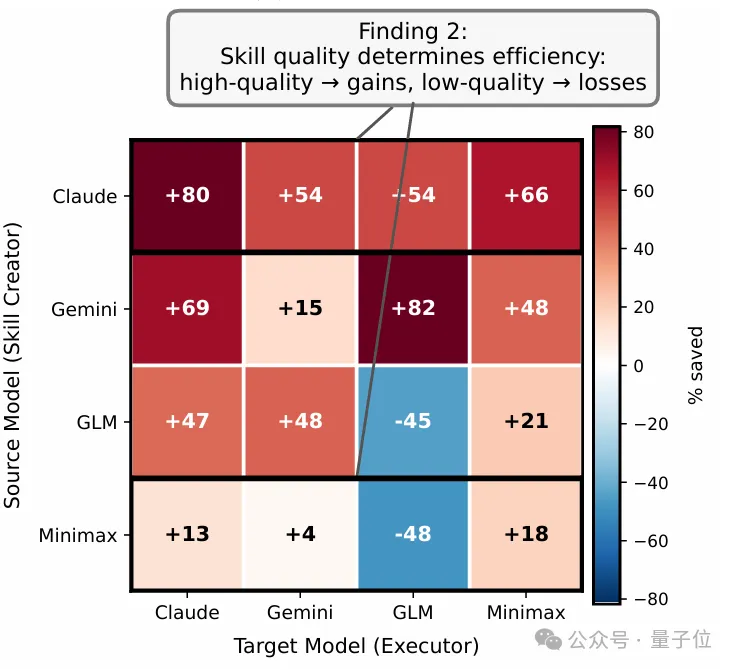
通过skill跨模型复用的Token Saving heatmap,团队发现:
Skill不只是“能不能用”,还要看“用了之后值不值”。比如Claude创建的skill,在不同执行器上普遍都能带来很高的节省;而质量较弱的skill,节省效果就明显更不稳定,甚至在某些组合下会出现负收益。也就是说
高质量的skill不仅成功率更稳定,也更容易带来显著的token节省。
SkillCraft解决的,不只是Agent会不会用工具,而是它能不能把确认可行的工具链,变成随时可复用的技能。
这可能比“再多做几道题”更重要。因为真正有用的Agent,不该永远像第一次做任务那样工作,而应该拥有自己的经验积累,产出真正可复用、可迁移、而且值得复用的skill。