内存厂暴跌上百亿,只是一个乌龙?差评
如果不是谷歌 TurboQuant 的搞了这样一场闹剧,我都没发现我们忍 AI 这么久了。
这个月的 24 号,谷歌研究院(Google Research)突然发帖,详细介绍一项名为 TurboQuant 的极端压缩算法。
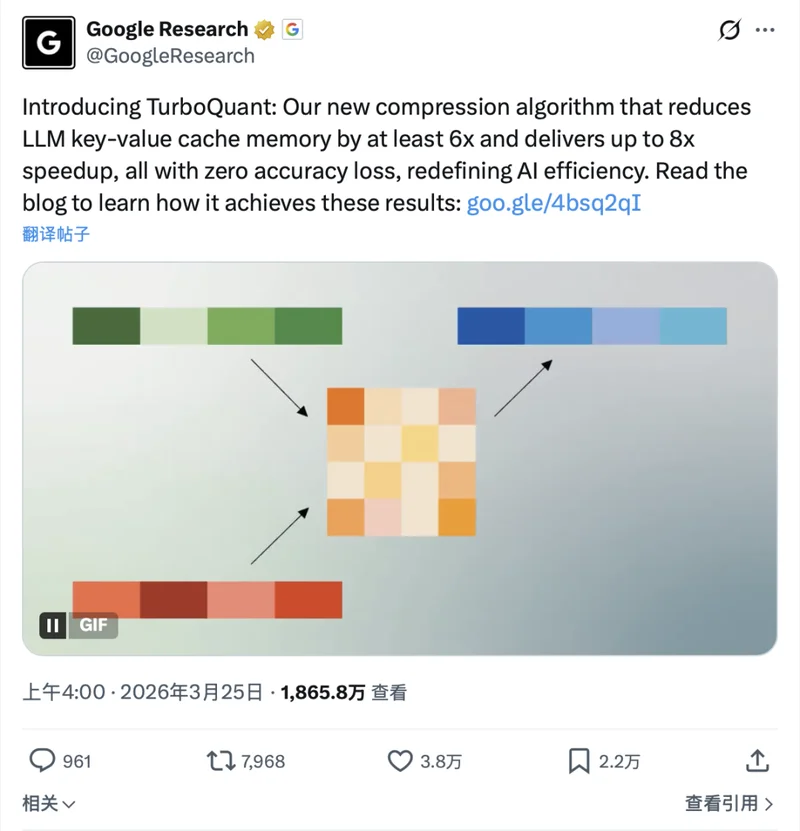
这篇帖子非常简单地总结了 TurboQuant 这个算法的用处 —— 它能把大模型推理时的 KV cache 内存压缩到 3.5 bit(约 6 倍),而且几乎不丢精度。
翻译成人话就是,谷歌研究院介绍了一种算法,能大幅度减少大模型对于内存的消耗了,以前用 600G 内存才能搞定的事儿,用上这个算法后只要 100G 就行了!
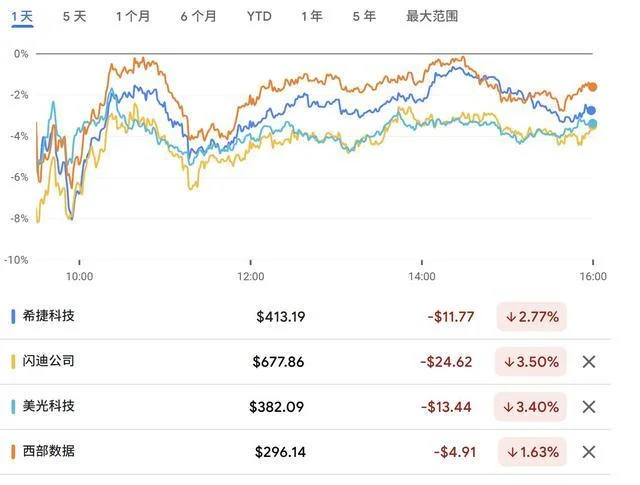
第二天,原本还在吃着火锅唱着歌的几个存储大厂,股价应声下跌。
美光科技股价下跌3.4%,市值损失151.66亿美元,闪迪(SanDisk)股价一度大跌6.5%,收盘时跌幅收窄至3.5%,市值损失36.3亿美元。西部数据(Western Digital)下跌1.63%,市值损失16.64亿美元。
图表来源:新浪财经
整个 AI 圈都炸开了锅,大家都纷纷开始分析,TurboQuant 到底厉害在哪里,又是怎么影响
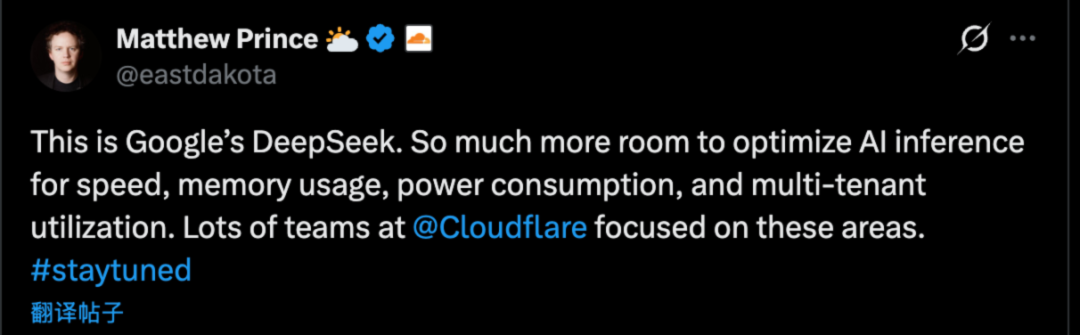
就连 Claudflare 的 CEO 都发文评价说,这是谷歌的 DeepSeek 时刻。
很多差友看到这个消息,可能要在被窝里笑出声了:干的漂亮!接下来的内存、固态硬盘,是不是也得跟着跌了?咱们攒机党是不是终于熬出头了?
我当然也希望事情往这个方面发展。
为了搞清楚咱这个最朴实的愿望能不能实现,我还特地去做了点功课,学习了下 TurboQuant 到底是个什么东西。
结果还没等我搞明白这个 TurboQuant 到底怎么个Turbo 法,事情就迎来了180° 的大反转 ——
3月27号晚上10点,苏黎世联邦理工学院的博士后高健扬,在知乎、X 和 ICLR 评审平台上同步发文,指控当初 谷歌用来介绍 TurboQuant 算法的论文学术存在严重的学术不端。
高博士发现,谷歌的 TurboQuant ,跟自己团队搞的 RaBitQ 算法高度撞车,底层都用了“随机旋转加JL变换”。
要说英雄所见略同也就罢了,但离谱的是,高博士甩出的邮件证明早在2025年1月,谷歌这篇论文的二作 Majid 就专门发邮件,低声下气地找高博士求助怎么跑通 RaBitQ 的代码。
这就不对了,谷歌这样的做法,算不算是把人家底细都摸透了,却在胜利结算的时候决口不提别人干了啥呢?
光掩盖来源还不算,谷歌的 Turbo Quant 团队甚至无视既定的数学证明,直接在论文里空口白牙地硬踩高博士的理论。
高博士认为自己的 RaBitQ 的算法,已经被严格证明达到了理论计算机顶会级别的一流标准。
结果 TurboQuant 团队连推导都不看,在毫无证据的情况下,直接在正文里给高博士盖了个“理论次优、分析粗糙”的帽子。
但最让人绷不住的,是谷歌那堪称“魔幻”的跑分双标。
论文里吹牛说自家算法比 RaBitQ 快了几个数量级,但背后的暗箱操作极其下作:
谷歌给自己配的是算力怪兽 A100 GPU,给对手安排的却是关掉了多线程的 CPU。
而且他们放着人家现成的、高度优化的 C++ 开源代码不用,非要用TurboQuant 论文二作自己半吊子翻译的 Python 版本去跑,给高博士的算法又叠了一层debuff。
在去年5月的邮件里,这篇论文的二作作者亲口承认了这种 “ 单核打多核” 的非对称操作,也承认把这事同步给了论文的其他共同作者。
但在最终发表的论文里,这两层能引发量变级差异的软硬件信息,被抹得干干净净。
同时 TurboQuant 论文的作者也拒绝承认自己的算法跟高博士的 RabitQ 在结构上相似。
这篇带有硬性错误的论文,被 ICLR 2026 会议接收,再后来,就有了我们开头说的故事,通过谷歌研究院官方渠道大规模推广这篇论文。
谷歌研究院只提到了TurboQuant 有多厉害,能节省多少内存,但只字未提支撑 TurboQuant 的这篇论文本身的种种错误。
这些推广,在社交媒体浏览量已达到数千万次,于是便有了上周几个头部存储厂商的股市震荡。
高博士估计也是实在是看不下去了,才选择发文公开实锤了。
随即存储市场这边,也逐渐从第一波震荡中缓过神来了。