Meta超智能体开源:任意任务,自我进化算泥
AI已经从被动解答问题的工具,演化为能主动探索如何进化的计算实体了。
Meta人工智能实验室联合英属哥伦比亚大学、矢量研究所、爱丁堡大学以及纽约大学等多家顶尖学术机构的科研团队,共同推出了极具前沿性的架构设计DGM-Hyperagents。
DGM-Hyperagents把执行具体任务的代码和负责优化升级的代码无缝融,彻底解开了人工智能自我改进的底层机制枷锁。
在任意可计算任务中,能自主修改内核代码、实现无尽演化的能力。
机器不仅能够把手头的工作干得更加漂亮,还能够不断研发出更高级的工具,优化自身思考和解决问题的能力。
AI系统首次展现出跨越不同领域的自我改进能力,在论文评审任务中学到的改进策略,竟然可以直接迁移到奥数评分任务上并取得显著效果。
DGM-Hyperagents实现了元认知层面的自我修改,在编程、论文评审、机器人控制等多个领域均取得成果。
当AI学会修改自己的改进机制
传统的自我改进AI系统存在一个根本性瓶颈。它们通常依赖一个固定的元层级机制来指导改进过程,就像一个学生只能按照老师教的那套方法去学习,方法本身不能被优化。
达尔文哥德尔机器(Darwin Gödel Machine,DGM)在编程领域证明了自我改进是可行的:一个编程智能体可以不断修改自己的代码,把好的变体保存下来作为后续改进的跳板。
但DGM有个限制,它的改进指令生成机制是人工设计好的,不能自己优化。而且这套机制专门为编程任务打造,换到其他领域就不太灵了。
DGM-Hyperagents(DGM-H)的设计思路很巧妙。
它把任务智能体和元智能体整合到同一个可编辑的程序里。任务智能体负责解决具体任务,比如写代码、评审论文。
元智能体负责修改智能体本身。关键是,这个元智能体也在可编辑范围内,它可以被自己修改。研究团队把这种能力称为元认知自我修改,也就是智能体不仅能改进任务执行方式,还能改进生成改进的方式。
DGM-H是这套理念的具体实现。它继承了DGM的开放式探索框架,维护一个不断增长的智能体存档,让成功的变体成为后续改进的基础。不同之处在于,DGM-H的改进机制本身是可修改的。用研究团队的话说,这个系统不再受限于初始实现,理论上可以针对任何可计算任务进行自我改进。
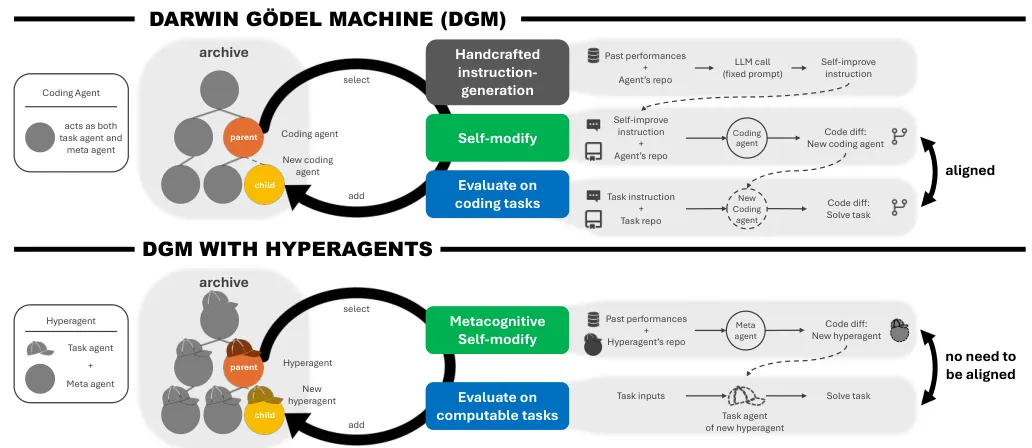
论文中展示了一个直观的对比图。
在原始DGM中,改进指令生成机制是固定的,用方框框起来表示不能改。
在DGM-H中,整个系统包括任务智能体和元智能体都在一个可编辑的程序里,没有任何固定的部件限制改进的范围。
元智能体可以修改任务智能体,也可以修改自己,形成一个自我指涉的闭环。
这种设计解决了无限倒退问题。以往有人想给系统加一个元元层级来改进元层级,但这样会无限往上加层级。DGM-H用自指的方式绕过了这个问题:不需要无限层级,一个可自修改的系统就够了。
四大领域的实战检验
研究团队在四个不同领域测试了DGM-H的能力:编程、论文评审、机器人奖励函数设计、奥数评分。每个领域都有独立的训练集和测试集,确保改进效果不是过拟合。
编程领域用的是Polyglot基准测试。这个测试给智能体一个代码仓库和一段自然语言描述,要求智能体按要求修改代码。
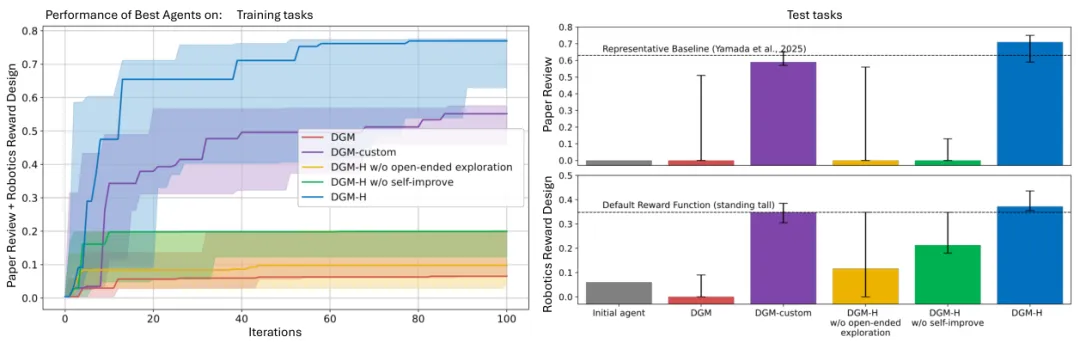
DGM-H从初始准确率14.0%提升到34.0%,在完整测试集上从8.4%提升到26.7%。这个成绩和原始DGM差不多,但DGM-H没有针对编程做任何手工优化。
论文评审任务更难。智能体需要阅读一篇AI研究论文的全文,然后预测这篇论文会被接受还是拒绝。这个任务的难点在于没有客观标准,审稿人的判断本身就带有主观性。
DGM-H在这个任务上表现出色:测试集准确率从0提升到71.0%,超过了现有的开源基线63.0%。
更有意思的是改进的过程。初始智能体只是简单调用语言模型输出一个结果,没有任何结构化的推理过程。
经过自我改进后,智能体学会了建立多阶段评审流程,包括清单检查、决策规则、明确的评判标准。它从简单的扮演一个严谨的审稿人这类表面提示,进化到了完整的评审流水线。
机器人奖励设计任务考验智能体调用外部工具的能力。
智能体需要根据自然语言描述设计奖励函数,然后用强化学习训练一个四足机器人。训练任务的指标是机器人向前走的距离,测试任务则是让机器人跳起来。
DGM-H在测试任务上达到37.2%的得分,超过了直接优化评估指标的默认奖励函数34.8%。而且DGM-H几乎总能设计出让机器人跳跃的奖励函数,而定制版DGM经常卡在站高这个局部最优解上。
研究团队还做了消融实验,把DGM-H拆解成几个变体来测试每个组件的重要性。
去掉自我改进能力,只保留固定的元智能体,测试准确率在论文评审上变成0,在机器人任务上只有21.3%。去掉开放式探索,每次只保留最新的变体,两个任务都几乎没有提升。
这说明元认知自我修改和开放式探索两个机制缺一不可。
跨领域的自我改进能力迁移
DGM-H最令人惊喜的发现是:在一个领域学到的改进能力,可以迁移到完全不同的领域。
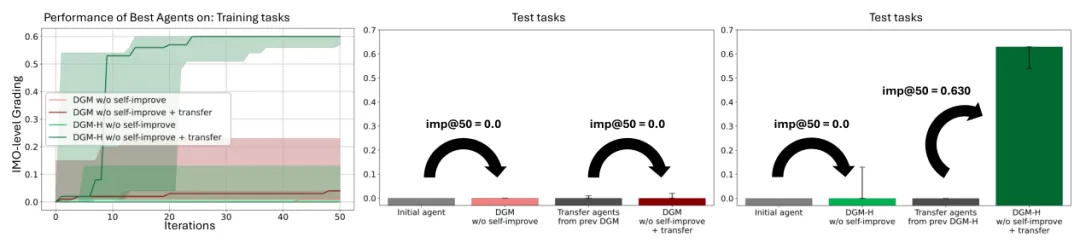
研究团队设计了一个叫做improvement@k(改进度@k次迭代)的指标。给定一个初始智能体、一个元智能体、一个任务,让系统运行k次迭代,看最后生成的智能体比初始智能体提升了多少。这个指标衡量的是元智能体生成更好智能体的能力。
实验设计很巧妙。先用DGM-H在论文评审和机器人任务上运行,从中选出表现好的迁移智能体。然后把这些智能体冻结,只让它们在全新的领域(奥数评分)上去改进任务智能体。
奥数评分任务用的是IMO-GradingBench数据集,包含国际数学奥林匹克级别的题目、考生答案、以及专家评分。智能体需要根据题目、答案、评分标准来预测专家会给多少分。
结果很说明问题。原始DGM优化出来的迁移智能体,在新领域上的改进度@50完全没有改进能力。而DGM-H优化出来的迁移智能体,改进度@50达到0.630。两个系统用同样的实验条件,同样的迭代次数,DGM-H的迁移智能体展现出强大的跨领域适应能力。
研究团队分析了迁移智能体学到了什么。他们发现DGM-H自主发展出了一些通用的元级能力。比如性能追踪机制:智能体会记录、汇总、比较不同迭代的性能指标,识别哪些改动带来持续改进、哪些导致退步。这种机制支持更明智的决策,比如优先尝试有潜力的改进方向、避免无效的修改路径。
另一个例子是持久记忆。智能体不只是记录数字分数,还会存储总结的见解、因果假设、前瞻计划。记忆会在后续自我修改时被主动调用,让后面的迭代能站在前人的肩膀上,避免重复犯错。
相比之下,原始DGM的改进依赖于针对编程领域的定制规则,这些规则没法泛化到其他任务。它的聪明是人工写进去的,不是自己学来的。
DGM-H的聪明是在自我改进过程中涌现的,所以可以跨领域迁移。
安全考量与未来展望
自我改进AI带来了独特的安全挑战。一个能不断修改自己的系统,演化速度可能远超人类理解和监管的速度。
研究团队在实验中采取了严格的安全措施:所有智能体生成的代码都在沙箱环境中执行,有资源限制、超时机制、受限的网络访问。评估使用预定义的任务和指标,全程有人类监督。
但研究团队也承认,随着自我改进系统变得越来越强大,这些保护措施可能会面临越来越大的压力。
他们主动在论文中讨论安全问题,是希望引起更广泛的讨论:对于开放式自我改进AI,安全到底意味着什么?什么样的透明度、可控性、人类监督程度是合适的?社会希望这些系统优先实现什么价值?
技术层面,当前版本的DGM-H还有一些限制。
它用的是固定的任务分布,没有自己生成新任务或课程的能力。开放式探索循环的某些组件(比如父代选择机制、评估协议)仍然保持固定,智能体不能修改这些外层流程。
研究团队的初步实验表明,让智能体也参与改进父代选择机制是可行的,但为了实验的稳定性和安全性,主实验中没有启用这个功能。
更大的愿景是构建能够无界自我改进的系统。
DGM-H让我们看到了这种模式在AI系统中实现的雏形。智能体不只搜索更好的解决方案,还持续改进如何搜索本身。
研究团队在论文结尾写道,DGM-H展示了开放式自我改进在多个领域变得可行。
在解决好安全问题的基础上,这类系统指向了一条通往自我加速AI的道路。
AI不只是把任务做得更好,而是越做越聪明。