全球顶尖大模型一夜惨遭血洗新智元
今夜,整个AI圈震动了。全球最难AGI测试ARC-AGI-3一上线,就把全球顶尖AI打到集体失声,人类满分通关,最强模型Opus 4.6得分仅0.2%,还不到1%。AI这是一夜被打回「原始人」了。
就在今天,这条消息把整个AI圈给震了。
众望所归的,全球唯一尚未饱和的智能体基准测试ARC-AGI-3出炉了,直接血洗了全球顶尖大模型。
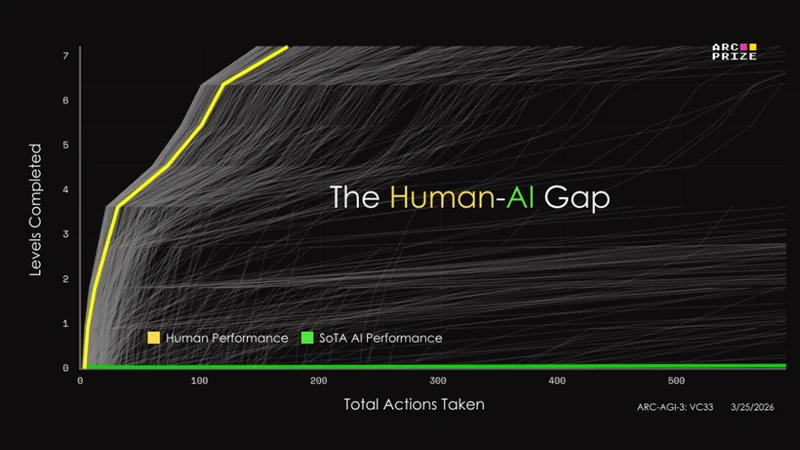
在这个测试中,人类得分100%,AI的得分普遍低于1%。
这个差距,比珠穆朗玛峰还高。
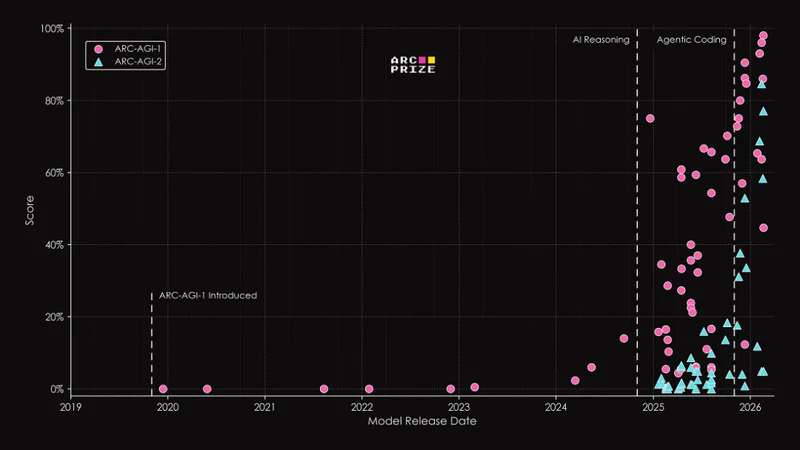
最惨烈的是,在上一代测试中还能拿下69.2%高分的「模范生」Opus 4.6,在ARC-AGI-3面前直接现了原形,得分仅为0.2%。
这位曾经横扫各大榜单的「学霸」,连蒙带猜都拿不到1分。
这面镜子,照出了当前AI能力中最深的裂缝。
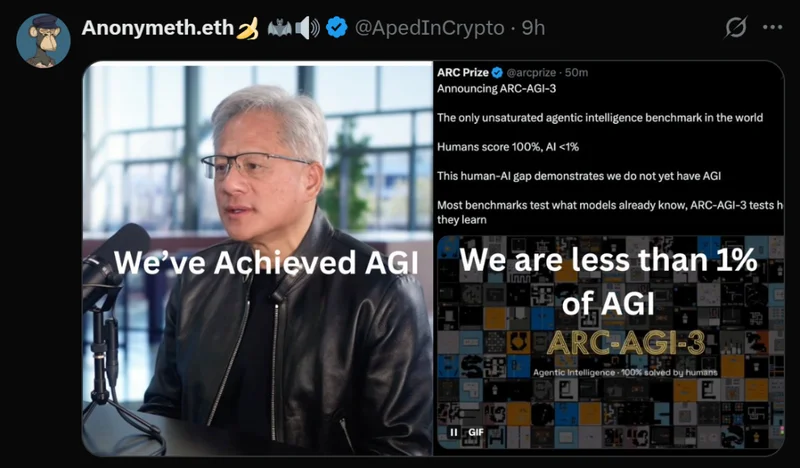
在最近的采访中,老黄认为我们已经实现了AGI。但是ARC-AGI-3显示,或许如今的AI连1%的AGI都没有实现。
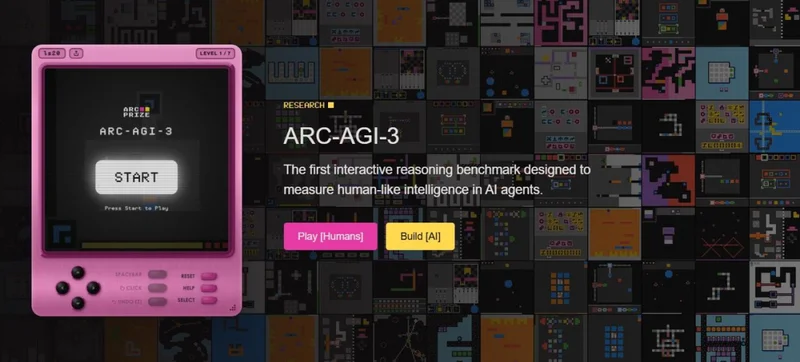
ARC-AGI-3,到底有多变态
它的前身ARC-AGI-1和ARC-AGI-2,已经是AI圈出了名的「魔鬼测试」。
那些测试里,AI需要观察几个示例,然后推断出网格变换的规律,完成新任务。
听起来不难?但就是这些看起来像幼儿园连线题的东西,曾经让无数大模型铩羽而归。
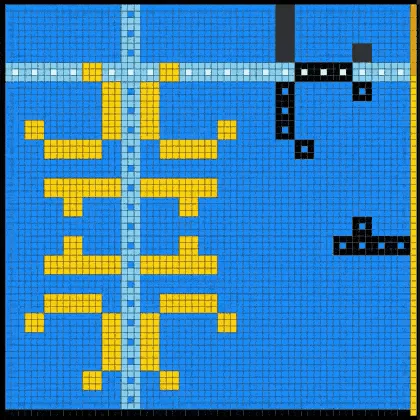
而到了ARC-AGI-3,难度直接换了个维度:从「静态题」变成了「互动游戏」。
150多个手工设计的交互式游戏环境,包含1000多个关卡。
每个游戏都有自己的内在逻辑、隐藏规则和通关条件。但没有任何说明文档,没有自然语言提示,没有人告诉你「左边的按钮会开门」或者「收集三个红色方块就能过关」。
AI智能体被丢进去,只能看到当前画面,选择一个动作,观察结果,再决定下一步。
它只能像盲人摸象一样,一步一步试探,然后在大脑里拼凑出一个「这个世界可能是这样运作的」的模型。
这正是ARC Prize基金会想测的四件事。
探索:能不能通过主动与环境互动来获取关键信息?
建模:能不能把零散的观察凝聚成一个可以预测未来状态的世界模型?
目标获取:没有人下达指令,能不能自己判断出「我应该以什么为目标」?
规划与执行:能不能规划出行动路径,并根据环境反馈随时修正?
「几何级数」的羞辱:0.2%是怎么来的?
评分标准同样残忍。
ARC-AGI-3的评分不看「有没有通关」,而是看「效率」,而且是和人类比效率。
这在AI基准测试的历史上,还是头一回。
受Chollet那篇《论智能的衡量》的启发,ARC Prize团队把「智能」操作化为一个转换率:
你从环境中获取信息的效率有多高?你把这些信息转化为正确行动的速度有多快?
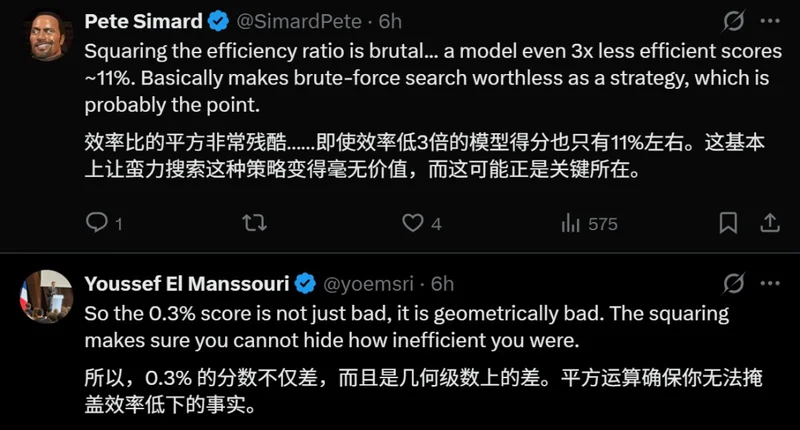
假设人类解决这个游戏需要10步,而AI用了100步,那AI的得分是多少?
不是10%,而是1%。
公式是:(人类步数/AI步数)²。人类10步,AI 100步,那就是(10/100)²=0.01=1%。
如果AI用了200步,这一数字就是0.25%;500步就是0.04%。
这一下,把AI所有的「蛮力」路都堵死了。