又一华为天才少年入局具身创业量子位
又一位华为天才少年加入具身智能创业战场。
6G冲浪的量子位最新发现,去年从华为诺亚方舟实验室转入学界的周凯文,在入职港中文不到半年后,悄然更新了个人主页。
他已加入具身创企诺因智能,担任合伙人兼算法主管。
顺着周凯文人事变动这条线往下扒,我们发现了三条很值得和大家分享的信息。
第一,这家叫诺因智能的具身智能创业公司,成立时间很短,不满一年,但已经聚集了一批履历极强的技术人员。
第二,该公司选择的方向,是当前争议最大、也最难落地的ToC具身智能机器人。
第三,也是比较亮眼的一点,诺因智能刚发了个新具身模型,已经在一个具身智能权威榜单上拿下第一。
综上,这家半年内连融三轮,但相当低调的具身公司,已经越来越掩藏不住了。
从一条人事变动,扒一扒ToC具身低调玩家
在火热的具身智能赛道,顶级人才的流动本身就是一个重要信号。
周凯文2013年以信息奥林匹克竞赛保送复旦大学,2019年在香港中文大学拿到计算机科学与工程的硕士学位,而后又在港中文攻读博士学位。
2022年博士毕业后,周凯文以“华为天才少年”身份加入华为诺亚方舟实验室。业内人士告知,他是诺亚决策与推理实验室第一位天才少年。
华为诺亚方舟实验室是成立于2012年的AI研究机构,专注于AI基础算法与产业应用,其中决策与推理实验室研究方向涵盖自动驾驶、具身智能、大模型推理等前沿方向。华为的自动驾驶和具身智能业务都离不开诺亚的孵化。
2025年,工作3年的周凯文离开华为,来到香港中文大学系统工程与工程管理系工作。
近日,周凯文更新个人主页,表示已经离开高校,加入具身创业大军。
大厂核心人才→加入高校→再次回归创业公司,这样的职业路径通常意味着两件事。
一是技术判断发生变化,认为产业落地窗口已经出现;二是目标公司在某个关键方向上具备足够吸引力。
具身智能赛道的火热早已无需多言,大厂布局、初创扎堆,资本和人才持续涌入,但诺因智能绝对是赛道中一个低调的存在——全网资料寥寥,除了晚点团队的一次专访,创始团队几乎没有对外发声过。
但我们还是结合多方消息,勾勒出了这家公司的轮廓。
诺因智能成立于2025年7月,总部坐落于深圳。
成立仅小半年时间,就已连续完成了种子轮、天使轮、天使+轮三轮融资,投后估值超20亿元人民币,是目前国内少数专注ToC具身智能方向、且融资节奏强劲的创业公司之一。
不同于当下赛道中多数企业聚焦ToB工业场景,诺因智能从诞生之初,就将目标直指家庭消费场景。
讲真,家庭场景远比工业场景复杂,光照变化、背景干扰、物品形态的多样性,以及层出不穷的长尾任务,都让ToC家用具身智能机器人的研发难度呈指数级上升。
这也是为何该方向始终争议不断、落地缓慢。
哪怕掰着指头细数,ToC具身智能在国内玩家也真的没两家;也就国外有零星几家公司声量不错——比如前几天刚宣布完成B轮融资、估值来到11.5亿美元的Sunday Robotics。
用视觉生成模型给具身机器人喂数据
继续往下看。
除了落地场景与众不同外,诺因与其它具身智能公司的核心差异,其实集中在技术路线。
目前具身智能在采集训练数据时,通常有遥操作数据、仿真数据、人类视频数据、UMI等解法。
量子位了解到,诺因采集数据的方式比较先锋,通过生成式模型构建专属训练数据体系,用视频生成的数据来训练具身大模型。
这里唠几句视频生成模型生成数据和一般仿真合成数据的区别。
仿真合成数据,需要投入大量人力进行精细的场景建模,把所有资产、物理规律逐一嵌入,完成一个场景的建模后,才能基于该场景迭代数据。
视频生成模型合成数据,所有的场景都是自动化生成的,光照、背景、纹理等关键要素都能实现多样化调整,直接省去了人力建模的繁琐过程。
理论上,后者能无限量产出适配家庭复杂场景的训练数据。
此外,诺因官网相关资料显示,该公司的具身模型采用了自研的KNOWIN具身基础模型架构。
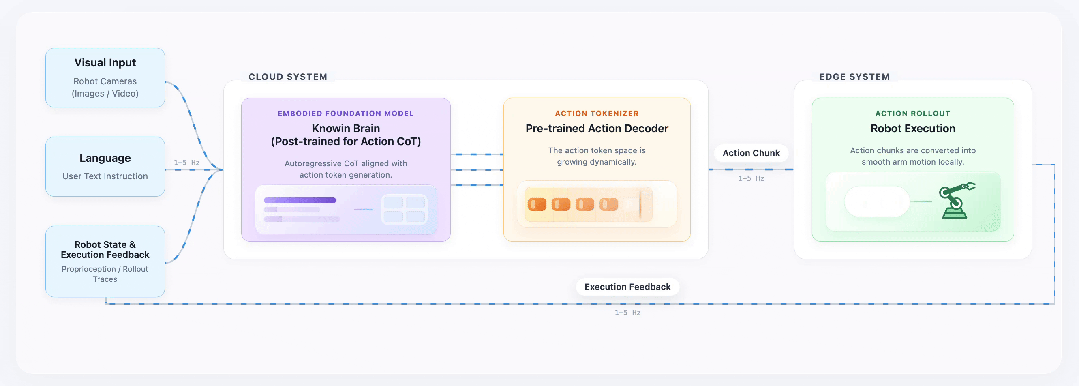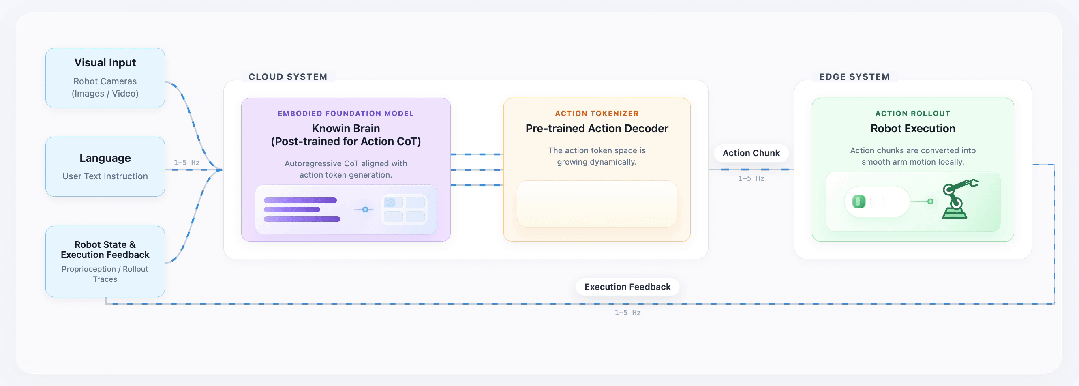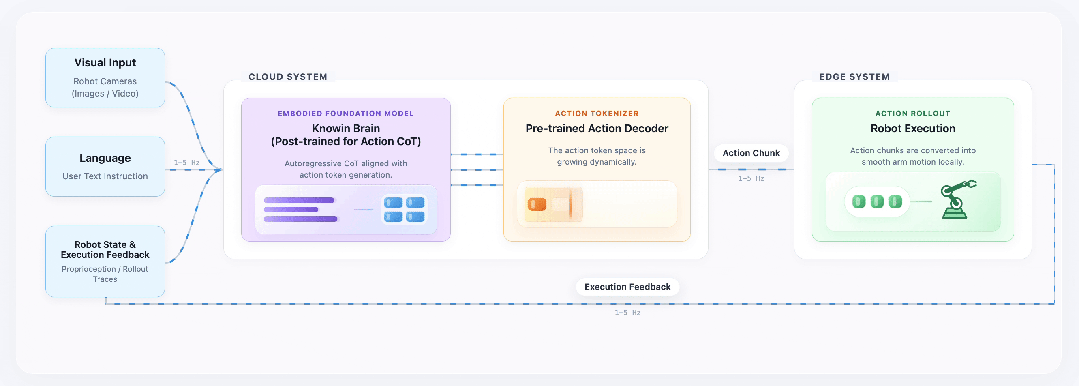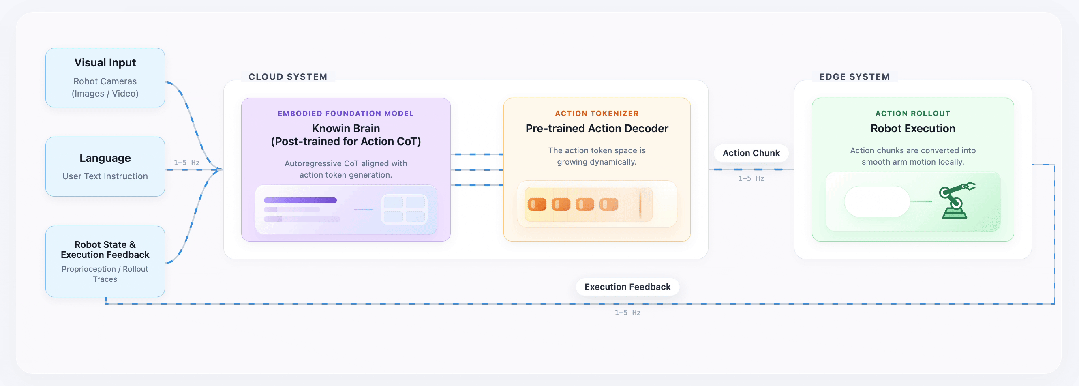
如下图所示,这是一套从数据、认知到执行的生成式闭环系统。
这套架构以云端系统为核心大脑、边缘系统为执行终端。
输入端整合机器人摄像头视觉数据、用户文本指令与本体状态反馈,以1-5Hz的频率同步输入云端KnowinBrain具身基座。
经过Action CoT后训练的KnowinBrain,能基于自回归逻辑完成动作思考与策略规划,再将决策结果传递给预训练的Action Tokenizer。
Action Tokenizer作为生成式动作编解码器,会把KnowinBrain输出的Action Token高效解码为可泛化执行的Action Chunk,最终由边缘端转化为平滑连贯的机械臂操作。
同时,机器人执行后的状态与环境反馈会以1-5Hz频率回传云端,让KnowinBrain实时评估物理状态、自主修正策略,形成完整的 “感知-决策-执行-反馈” 闭环。
支撑这套架构的核心是KnowinDream生成式数据引擎,它从有限真实数据中学习场景规律,合成海量覆盖极端光照、复杂材质的机械臂操作视频,解决了行业真实数据匮乏的痛点。
而动态扩容的Action Token Space,能让机器人的物理执行能力随场景拓展持续进化。
最主要的是,这条路线已经被诺因跑通了。
先来看看该公司官方视频,直观感受一下带来的效果:
下面这个视频里,机器人站在一台正在播放画面的电视机前叠衣服。
电视屏幕播放着色彩繁杂的视频内容,周围还有迪斯科灯球带来的复杂光源干扰。
虽然背景和光照始终在动态变化(比较接近真实家庭环境),但机器人依旧能稳稳完成任意形态衣物的折叠操作。
在模型层面,这条路线也得到了更直接的验证。
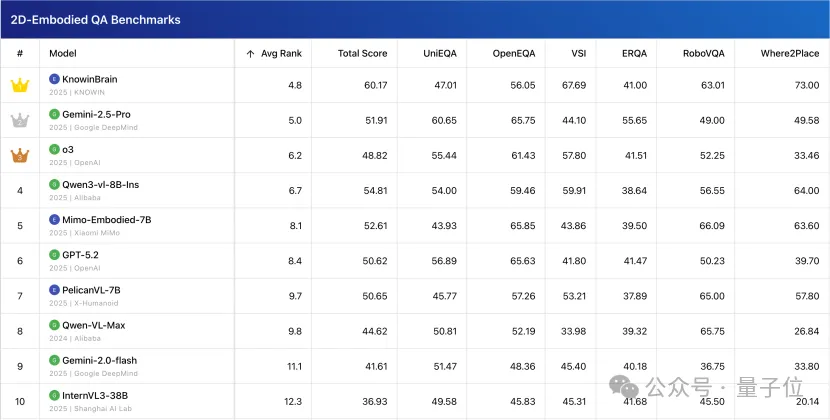
最近在具身智能评测榜单Embodied Arena中,诺因的模型KnowinBrain拿下了总榜第一。
Embodied Arena是一个由国内外10余家院校和科研机构联合研发推出的具身智能评测平台,核心研发成员来自天津大学、上海交通大学、伦敦大学学院、北京大学、清华大学等全球知名机构的研究人员。