“Token”发工资,有人慌了VISTA看天下
不到两个月,“Token”这个原本只被AI行业熟知的黑话,就以前所未有的速度席卷了所有人的生活。
Token是AI理解世界、说话干活的最小单位,好比游戏角色的血条。
当“每一句话都有价格”这件事变得可量化,人们也开始意识到另一件事,被消耗的,其实不只有机器的Token。(图源:《轧戏》剧照)
3月16日,阿里巴巴宣布成立Token事业群,并计划向员工提供Token额度,鼓励员工使用先进的AI工具。在大洋彼岸的英伟达GTC 2026大会上,英伟达创始人黄仁勋发表了两个小时的主题演讲,其中至少提到了70次“Token”,认为Token将成为未来工程师薪资的一部分。
黄仁勋在英伟达GTC 2026大会演讲
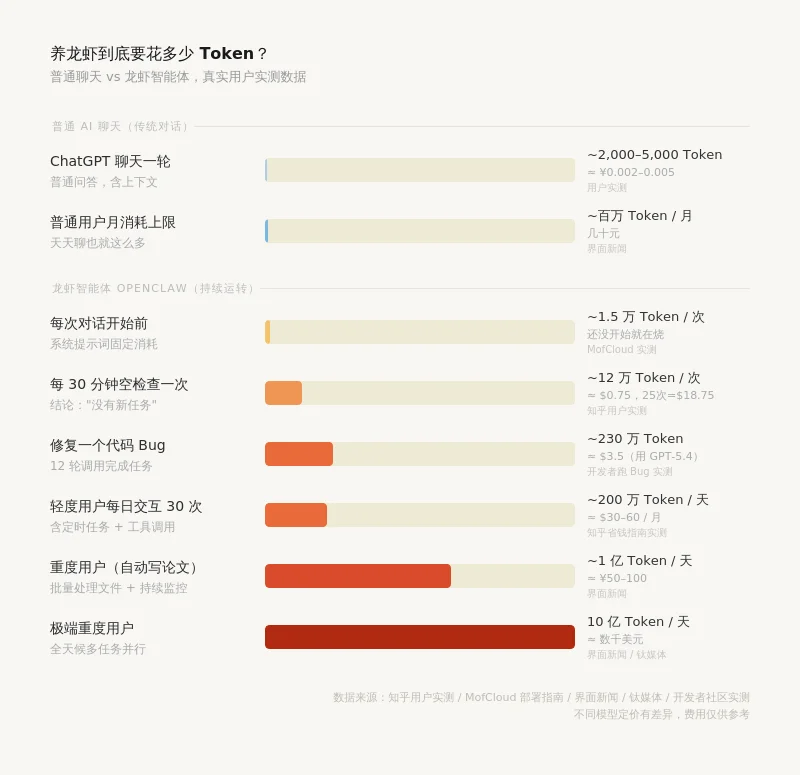
Token还成了年轻人“养龙虾破产”的幕后黑手。
“龙虾”指的是AI智能体OpenClaw,号称“24小时打工神器”。你装上它之后,只要在聊天框里动动嘴,它就能自动帮你写邮件、管日程、刷消息。
但很多尝鲜的年轻人,“龙虾”没养明白,钱包先被榨干了。
一位用户在社交平台上发帖称,周末在电脑上安装了“龙虾”,一晚上就问了几句好,查了一些价格数据,就收到了欠费邮件,账户显示Token的可用额度直接变成负数。一位深圳用户刚装上3天,不仅API(应用程序编程接口)的密钥被盗,还收到了一笔1.2万元的账单。
大厂们纷纷跟风,生怕输在起跑线上,互联网上,媒体和网友也都在为Token取中文名。《人民日报》把Token译作“词元”,网友们脑洞大开,争相整活,有人认为可以叫作“模丸”“智子”,有人认为Token可以叫“偷啃”,因为它是真的在“偷偷啃”用户的真金白银。
随着Token被熟知,有网友开始把人的“精力”“情绪价值”都叫作Token。当AI世界的每一次消耗都被Token量化,大家突然意识到,自己每天的耐心、注意力、表达欲,也相当于一种Token。
当你为了推测领导意图而字斟句酌,把一段话改八百遍,当你与不熟的人寒暄还强颜欢笑,甚至是你无意识地刷短视频时,你都在消耗心力。这样说来,人类这一天的Token消耗量怎么也要千万级起步,但可没人给自己充值。
Token量化的不只是AI算力,也是我们每个人的生活。这个迅速火遍全网的Token到底是啥意思?对普通人又意味着什么?
“知心姐姐”只是在切割你的话
“我觉得自己特别失败,好像做什么都不对。”凌晨,小静刚结束工作,满腹委屈无法诉说,于是打开了AI对话框,敲下了自己的烦恼。
“这不是你的错。在这个快节奏的世界里,感到疲惫是正常的。你刚才提到的那件事,其实恰恰证明了你的责任心强……”不出1秒,AI就用一段温暖治愈的文字,稳稳地接住了要碎掉的小静。AI似乎总能听懂并回应打工人的需求,有时,它甚至能理解情绪。
然而,残酷的真相是,这个倾听者并不具备“温柔的灵魂”。AI从头到尾只在做一件事,切割语言。
当小静输入“我觉得自己特别失败”时,AI并没有像人类朋友那样心头一紧。它只是迅速将这句话拆解成了几个独立的编号“我”“觉得”“自己”“特别”“失”“败”。在它眼里,这不是一句伤心的倾诉,而是一串待处理的数学序列。
AI分词成Token的示例(AI生成)
它之所以能回应得如此贴心,不是因为它懂你,而是因为它在海量的数据库里,计算出了在“失败”这个编号后面,接上“安慰”类编号的概率最高。
这种被切割后的最小语言单元,就是Token。
Token就像AI的积木,组合在一起可以成为任何东西。AI会把我们输入的一句话,拆成一个个Token,再逐个预测下一个Token,最终拼成完整回答。而拼这些“积木”,靠的就是AI公司天天挂在嘴边的“算力”,算力越足,拼得越快、越准,烧的Token也越多。
“龙虾”在前台卖力打工时,哪怕是最简单的指令,燃烧的Token也不少。根据澎湃新闻,“龙虾”每完成一次分析任务,一般需要消耗300万左右的Token。你让它一晚上自动处理微信消息,哪怕只是回几个“嗯嗯、好的、晚安、哈哈”,可能都要花几万Token。有网友表示:“和‘龙虾’说一次‘你好’就要花200多Token。”
Token的天花板,就是AI能记住多少事情、做多复杂事情的天花板。这在一项叫作“大海捞针”的测试中尤为明显。“大海捞针”专门用于大语言模型性能评测。想象一下,你给AI一本几百页厚的书(这就是“大海”),然后在书的随机某一页里,悄悄插入一句毫不相关的话,比如“秘密代码是蓝色大象”(这就是“针”)。
表面上看,所有模型都读过这本书,结果却截然不同。
一些Token较小的模型,往往在开头和结尾表现良好,却很难找回中间那句关键信息,就像翻书时只记住了目录和结尾,却把最重要的内容遗漏。而Token更大的模型,则更有可能在整段文本中精准定位,甚至还能指出这句话大概出现在什么位置。
在相关测试图中,红色区域代表模型“没找到那根针”的位置。红色越多,说明模型越容易在长文本中“看过却没记住”。
Claude-2.1的“大海捞针”测试,红色越多,代表AI犯的错越多。(图源 知乎@xyjz)
这也解释了为什么Token的大小,决定的不只是AI能读多长,而是在长上下文环境下的信息提取和记忆能力。
早期的AI模型只支持4K Token的上下文窗口,约等于一篇几千字的文章。这意味着,AI一旦处理长文本,就会出现断片的情况,甚至让用户产生“它是不是在偷懒”的错觉。如今,顶级AI模型的Token容量已经突破百万,能一口气读完《红楼梦》全文,已经能完成复杂的长文本处理、多任务联动。
Token在硅谷已经成了一种新型货币。OpenAI内部已经出现了Token消耗量排行榜,而位居榜首的员工一周之内就能消耗2100亿Token,足够把整个维基百科填满33遍。
图源 英伟达官网