一夜之间,AI终获「永久记忆」新智元
AI终于有了「永久记忆」!今天,超级记忆系统ASMR重磅登场,在业界公认最难AI记忆考试中,刷爆SOTA拿下99%成绩。全网直呼太疯狂。
AI记忆难题,已彻底被解决?
今天,一个Supermemory团队爆火出圈,向全世界扔出了一颗核弹——
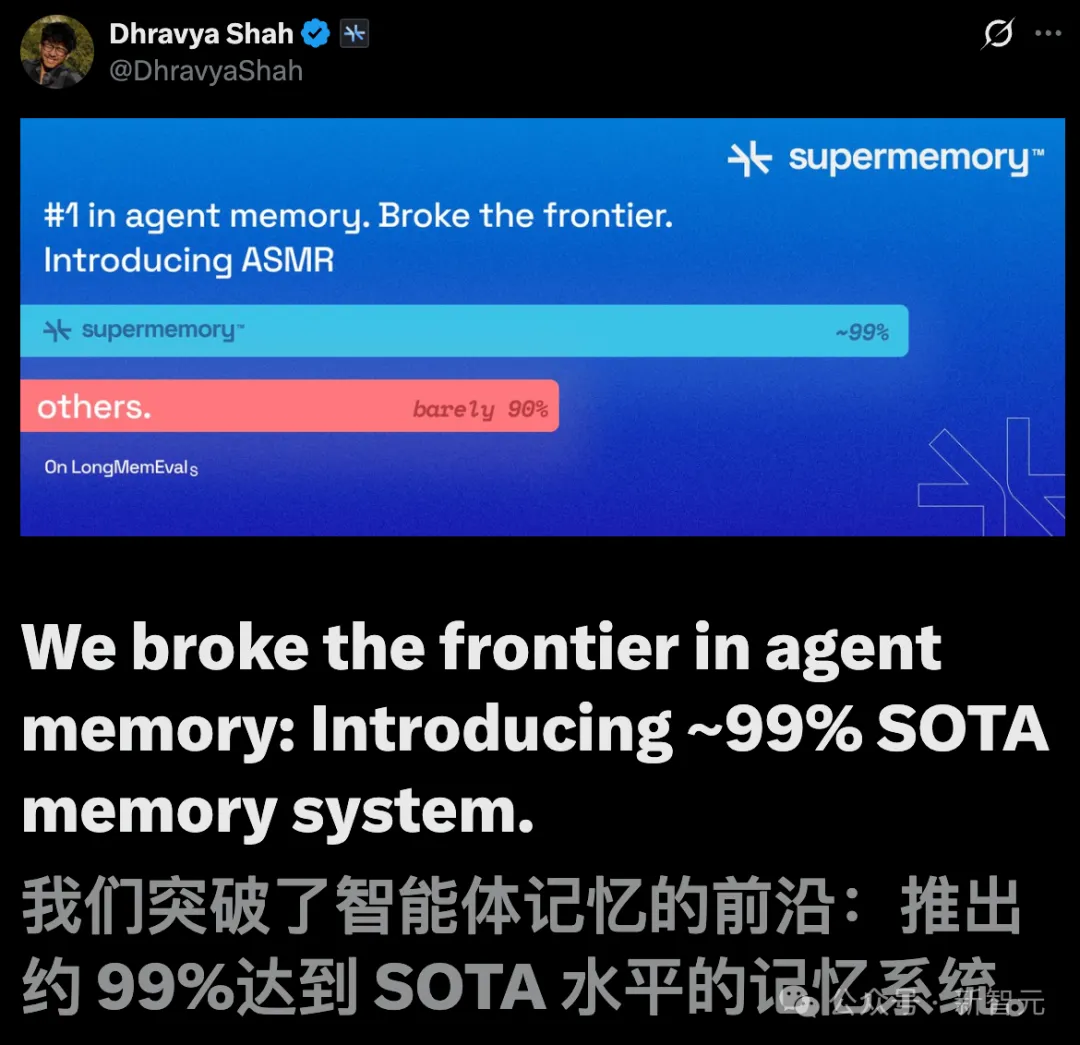
超级记忆系统「ASMR」问世,把AI记忆界最难考试LongMemEval,刷到了99%准确率。
全球数十亿Agent都需要记忆,而如今,AI「健忘症」几乎被攻克了。
是的,你没有听错!
ASMR以近乎无敌的姿态刷爆SOTA,一时间登上了今天X的热榜。
它抛弃了传统的「向量数据库」,抛弃了嵌入(embedding)模式,完全在内存中运行。
这一次,ASMR全程采用「多Agent并行推理」的流水线,具体分工如下:
3个「观察者Agent」并行读取原始数据,提取个人信息、偏好、时间线等六大维度信息;
当用户提问时,再派出3个「搜索Agent」进行主动推理检索。
如今,全网被「太疯狂了」刷屏了。
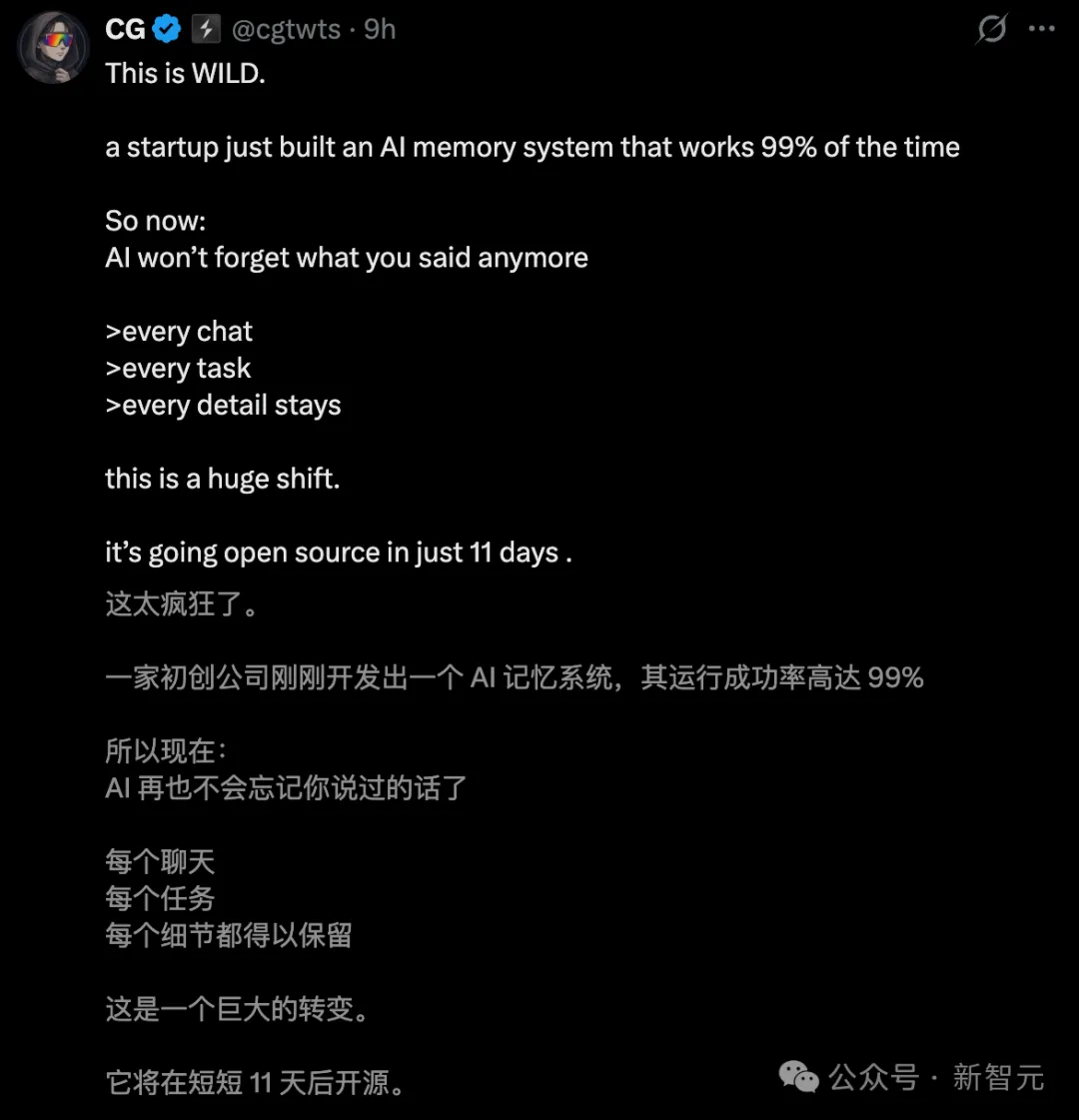
值得一提的是,ASMR将于4月初开源全部代码,AI记忆的「大航海时代」正式开启!
一夜之间,AI有了「永久记忆」
首先,还是要mark下这篇博客第一句话——
AI Agent的记忆问题现在可能已经完全解决了。
几个月前,Supermemory祭出首份研究报告,便在LongMemEval-s测试中拿下了85%的成绩。
这一分数,早就领先于当时所有公开的记忆系统。
而今天,超级记忆系统「ASMR」(智能体搜索与记忆检索)的出世,再一次刷新了纪录。
它的技术实现,非常简单。
不需要向量数据库、嵌入(embeddings),直接完全在内存中运行。
这意味着,它可以被内嵌到其他系统中,甚至是机器人等硬件中。
那么,ASMR具体是如何被打造出来的?
ASMR:多Agent并行干活
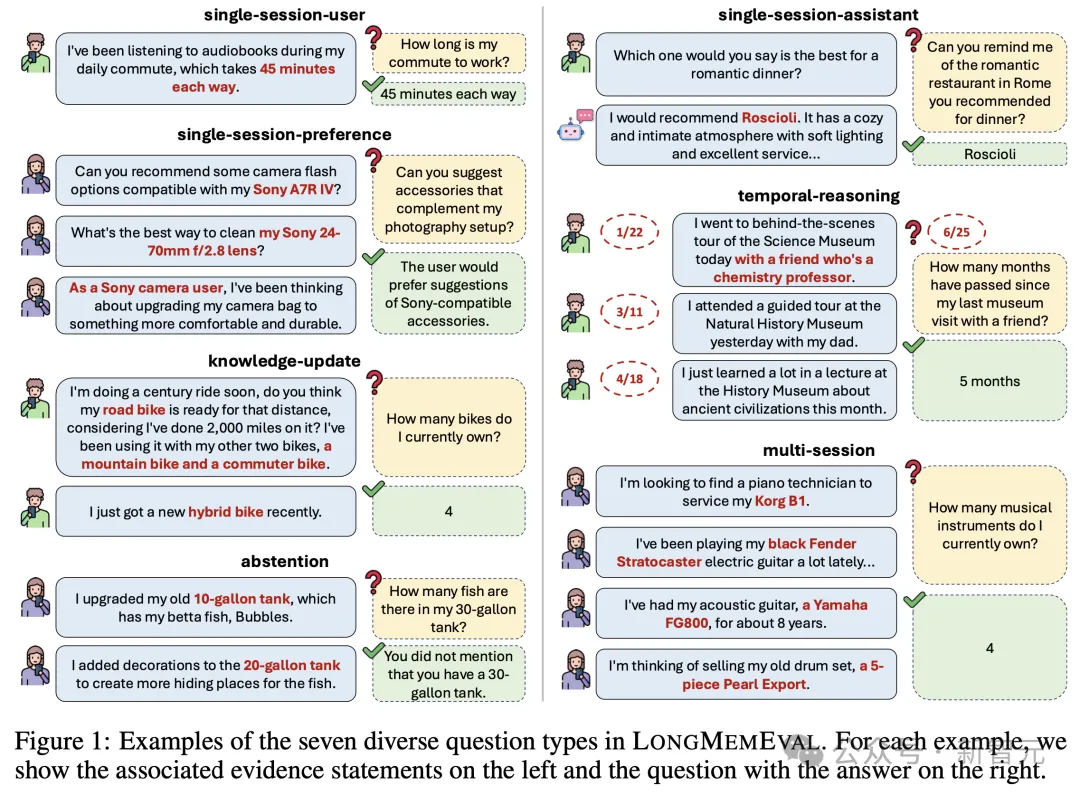
要知道,LongMemEval是目前公开可见的、最严苛的长期记忆基准测试之一。
很多基准测试只考量短上下文中的简单检索,但LongMemEval不同,它旨在模拟真实生产环境中的各种混乱情况:
在超11.5万智元(Token)的对话历史、相互矛盾的信息、跨越多个会话的零散事件,还需进行时间推理的复杂问题。
大多数记忆系统表现不佳,问题往往出在「检索」上,而不是推理上。
即便召回率很高,如果检索过程中伴随着大量噪音,LLM同样很难利用这些信息。
首要难题在于,如何只将正确的信息放入上下文窗口;更困难的是——如何判断检索到的事实已经过时,并已经被更新的版本所取代。
不仅如此,标准的向量搜索在多数情况下都很好用。
但在处理信息密度高、跨越多会话的时序数据细节时,它就力不从心了。语义相似度匹配无法可靠地区分某个事实是「旧信息」还是「新修正」。
为了应对LongMemEval的复杂性,必须从头开始重新构思信息摄取与检索管道,用主动的Agent推理来取代向量数学计算。
由此,团队跳出了传统RAG框架,构建了一个「多Agent协同编排」的管道。
3+3 Agent,各有分工
就像ASMR一样,这项技术简单直白,且让人极度舒适。
观察者Agent:并行摄取
首先,部署一个由3个并行读取器——观察者Agent,组成的智能体编排器。
它们背后由Gemini 2.0 Flash加持,不用针对用户对话进行分块和嵌入就能执行任务。