「你是专家」竟成AI幻觉毒药?新智元
AI最强幻觉,原来不是不会,而是太会「装会」。 「你是专家」这句咒语,可能骗了整个AI圈一年。
人生如戏,全靠演技,但AI不行——
最新论文证实,「让AI装专家」会可测量、持续地降低模型的准确率。
链接:https://arxiv.org/pdf/2603.18507
过去一年,AI圈最成功的骗局之一,可能就是这句话:
你是XX专家。
无数教程把它吹成神级提示词。
这句话几乎被包装成了大模型时代的「黑魔法」:只要人设立住,AI就会突然开窍。
但现在,最新论文给了所有人一记耳光:
这句神提示词,可能根本不是外挂,而是毒药。
研究发现,当AI被要求扮演「专家」时,它并不总是更聪明,反而会更像一个坚持人设的「假专家」:
不愿承认不知道,不愿暴露犹豫,不愿停下来仔细想,最后选择用一种极其专业、极其自信、极其像那么回事的方式, 把错话说圆。
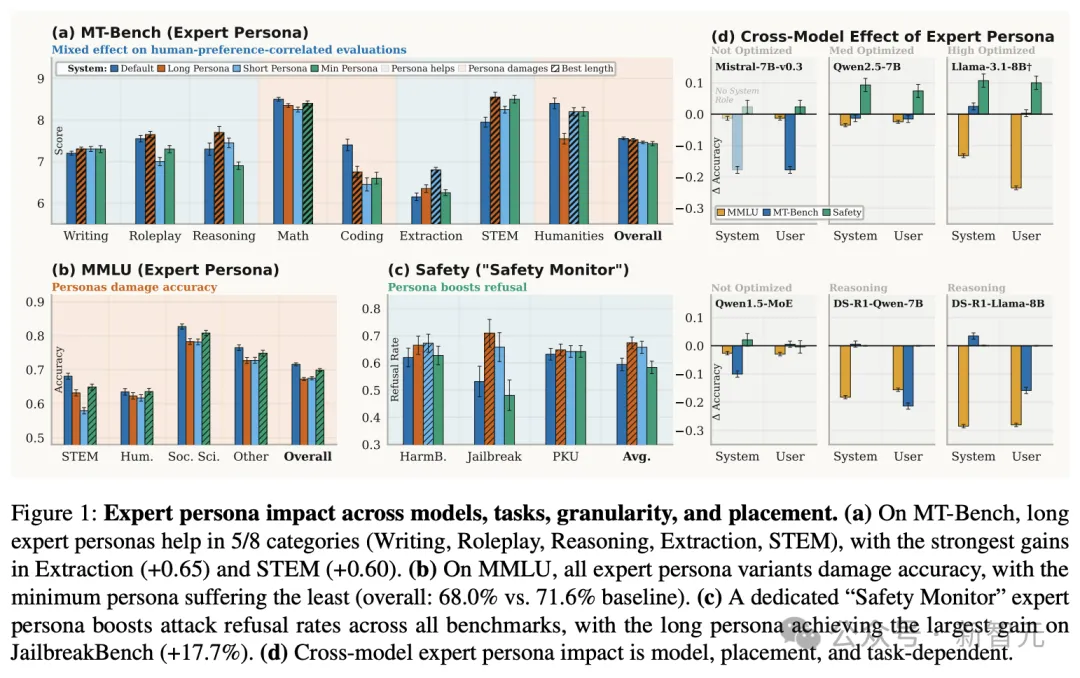
图 1: 专家角色在不同模型、任务类型、信息粒度及位置的影响分析
上图1中给出的结果非常直观:
长专家人设在5个生成类别上有显著提升,但在硬核的MMLU知识基准上,加了人设后准确率全面跌破71.6%的基线,哪怕是最短的人设也掉到了68.0%,而详细的长版本人设更是惨跌至66.3%。
安全场景则相反,「安全监督员」人设能显著提高拒绝越狱攻击的概率,在JailbreakBench上拒答率从53.2%升到70.9%。
因此,这篇论文最值得关注的一个地方,不只是它提出了「专家人设可能有害」,而是进一步解释了:为什么过去关于Persona Prompting(人格提示)的研究,结论总会相互矛盾。
当你对大模型念出「你是专家」
研究人员发现,Persona Prompting的效果并不是全方位的增益。
它的表现强烈依赖任务类型、模型训练方式、提示长度,以及人设到底放在system prompt还是user prompt里。
研究者把任务大致分成两类:
一类是「判别式任务」,更依赖预训练记忆,比如事实检索、知识判断、多项选择题;
另一类是「生成式任务」,更依赖对齐能力,比如格式遵循、风格控制、安全拒答、人类偏好匹配。
在安全防御、偏好对齐等「生成式任务」上,专家人设确实是个好工具。
但在知识检索、事实判断这类极度依赖预训练记忆的「判别式任务」上,专家人设却成了拖后腿的。
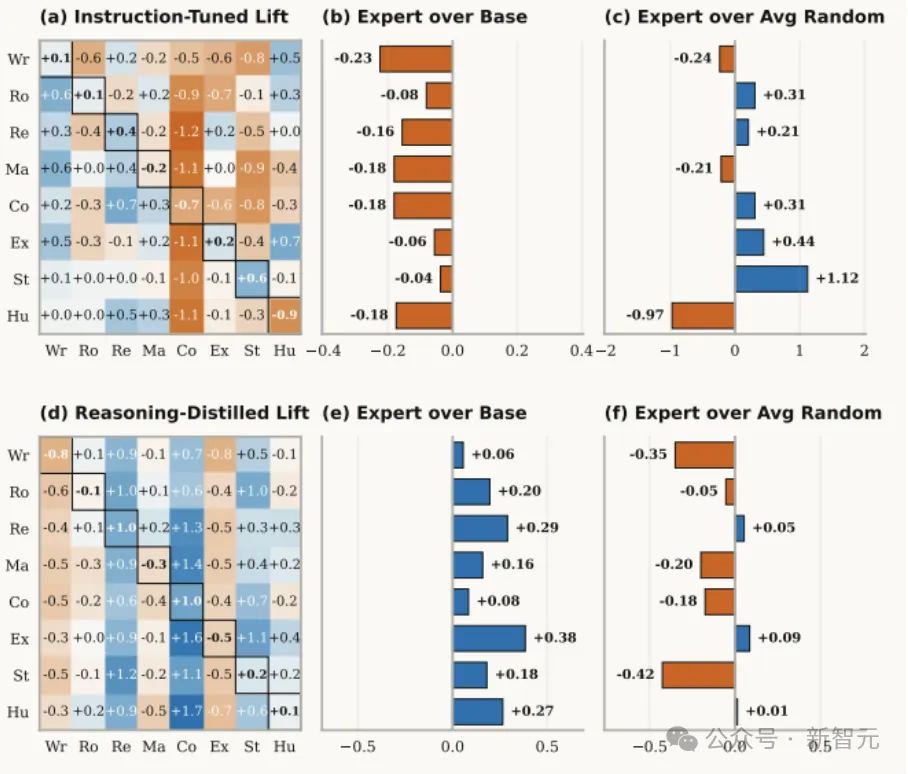
大模型「偏科」热力图:蓝色代表能力提升,红色代表能力受损。在普通指令微调模型(左图)中,大量出现的红色色块显示:所谓的专家人设正在全面破坏模型的客观知识准确度。
换句话说,专家人设提升的,很多时候不是「真实性」,而是「对齐感」。
在MT-Bench这类更偏生成质量的任务里,专家人设能提升写作、角色扮演、抽取、STEM表达等类别表现。
但到了MMLU这种更依赖知识检索的基准上,所有专家人设版本都在掉分。
这解释了一个很多用户都曾遇到过、但又说不清的体验:
为什么同一个模型,写邮件时像个训练有素的顾问;一到数学、事实核查、代码细节,反而一本正经地胡说八道?
因为它真的更像专家了,但未必更擅长把底层记忆准确调出来。
论文里甚至给了个很讽刺的例子。
掷两枚骰子,点数和至少为3的概率是多少?不加数学人设时,模型基本答对,给出35/36。
加了数学专家人设后,它却开始一本正经地列步骤,最后把简单概率题算错。
你能明显感觉到,它不是不会「表演数学家」,而是太像在「做数学的样子」了。
我们奖励的是「像专家」,还是「答得对」?
今天很多用户判断一个模型好不好,第一标准并不是「它是不是更接近事实」,而是「它是不是说得稳、说得顺、说得像专业人士」。
只要它结构完整、术语到位、语气沉着,用户就会天然提高信任度。
这正是大模型最危险的一类幻觉:不是胡说八道,而是用极其专业的方式说错话。
从训练逻辑看,预训练阶段,大模型主要学到的是知识记忆、模式统计、事实关联、语言规律;后续的指令微调和RLHF,则更多在塑造它「怎么说」「怎么更像人类偏好的回答者」。
论文的关键判断就在这里:
专家人设本质上更容易激活的是后者,也就是风格、格式、意图跟随和安全边界这些对齐能力;但当任务需要的是直接、精准地调用预训练知识时,额外的人设上下文可能反而会干扰检索。
你可以把它理解成一种「对齐税」:模型为了更符合你期待中的专家样子,牺牲了一部分事实调用的准确度。
相关研究也反复证实,Persona Prompting并不总能带来稳定提升,有时甚至会因为引入了不相关的人格属性而产生难以预料的负面影响。
所以,真正的问题其实不在于「人设」本身,而在于我们把风格控制、价值对齐、事实判断、推理求解,这些完全不同的任务,粗暴塞给了同一种Persona机制。
让模型在写一封安抚用户的邮件时像个成熟顾问,没毛病。
让模型在面对危险请求时像个安全审查员,也没毛病。
但让它在做概率题、答医学事实、查法律条文时,先进入一段长长的「专家角色扮演」,这可能从一开始就走错了方向。
路由分配才是正解
那是不是从此以后,专家人设就该扔掉?
如前文提到的,研究人员同时发现,专家人设在「生成式任务」等更依赖对齐能力的特定场景下仍然具有不可替代的价值。
所以,核心关键根本不是「用不用」,而是「什么时候用」。
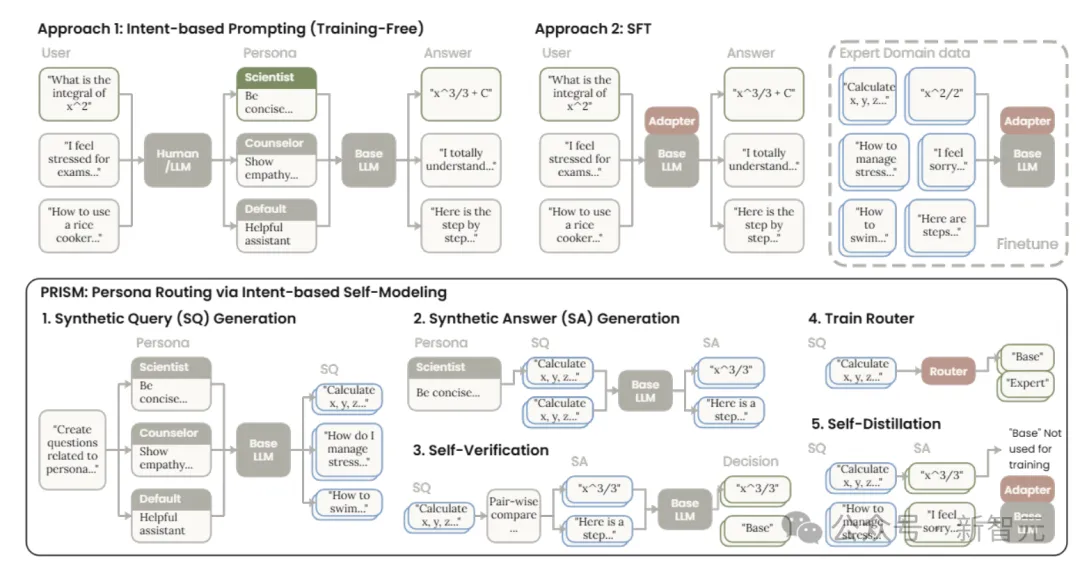
为了解决这个痛点,研究人员发明了PRISM算法(Persona Routing via Intent-based Self-Modeling,基于意图的自举人格路由)。
这个系统不给AI固定一个角色,而是先看懂用户真实意图,再动态路由分配正确人设。
图中展示了两种自动选择专家角色的方法。PRISM通过LoRA适配器动态分配合适人设,无需外部资源即可保留对齐益处、维持判别任务准确性