新基准:AI取代程序员还远新智元
AI编程模型在SWE-bench上表现优异,但仅能处理单仓库小修小补。BeyondSWE提出全新评测标准,考验AI跨仓库检索、领域知识理解、依赖升级和从零构建系统的能力,结果发现顶尖模型通过率暴跌至45%以下,暴露其缺乏真实工程思维。
过去两年,SWE-bench几乎是衡量Code Agent能力的唯一标尺。
从最初不到30%的解决率,到如今Gemini 3 Pro、GPT-5.2等前沿模型突破80%,社区似乎已经形成了一个共识:AI正在快速逼近人类程序员的水平。
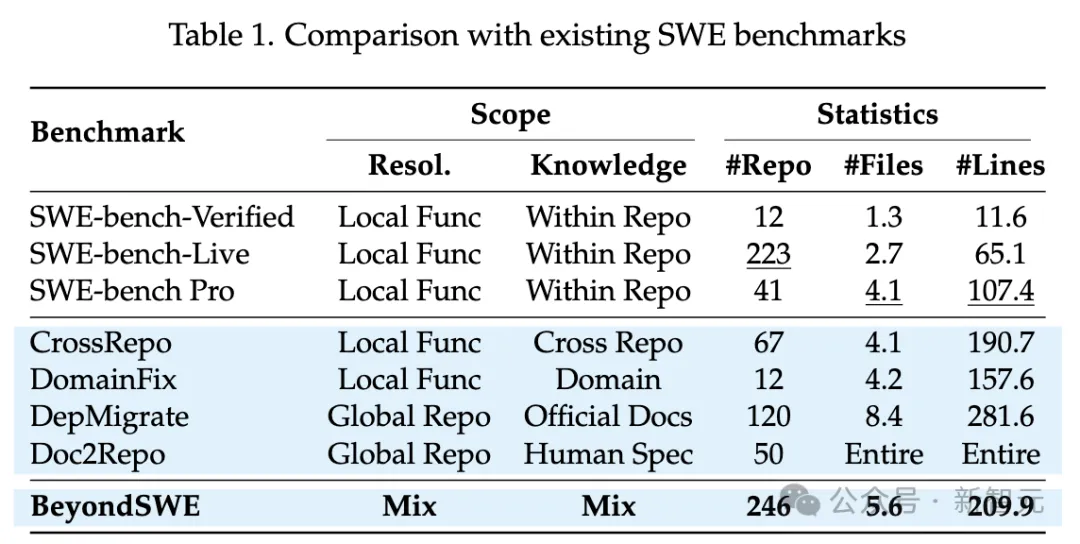
但如果回头审视这张「考卷」本身,一些数字令人不安:SWE-bench Verified仅覆盖12个仓库,每道题平均只需修改1.3个文件、11.6行代码,全部答案都能在仓库内部找到。即便是后续的SWE-bench Pro和SWE-bench Live,虽然扩展了仓库数量和修改规模,但在「知识来源」这个维度上仍然没有走出单一仓库的边界。
这意味着什么?
现有benchmark对Code Agent的考察,相当于让一个学生在开卷考试中做填空题——答案就在手边,只需定位和填写。而真实软件工程的全貌远不止于此。
近日,OpenAI也宣布放弃将SWE-bench Verified作为内部评测标准,直言其已难以区分前沿模型的能力差异。当出卷者都不再信任自己的试卷时,是时候换一张了。
衡量一个Code Agent是否「真的会写代码」,可以从两个维度来看:
解决范围(Resolution Scope):需要改动多大的代码范围?是改一个函数,还是改造整个仓库?
知识来源(Knowledge Scope):需要从哪里获取信息?仓库内部就够了,还是需要外部知识?
将这两把尺子摆在现有benchmark面前,差距一目了然——所有SWE-bench变体都集中在同一个象限:局部函数级别的解决范围,仓库内部的知识来源。真实软件工程中最常见、最棘手的那些场景,恰恰是评测的空白地带。
中国人民大学高瓴人工智能学院提出BeyondSWE,首次在这两个维度上同时突破,通过四类任务系统性地覆盖了真实软件工程的多个象限。
项目主页:https://aweai-team.github.io/BeyondSWE/
论文链接:http://arxiv.org/abs/2603.03194
代码链接:https://github.com/AweAI-Team/BeyondSWE
Scaffold链接:https://github.com/AweAI-Team/AweAgent
Leadboarder链接:https://aweai-team.github.io/BeyondSWE_leaderboard/
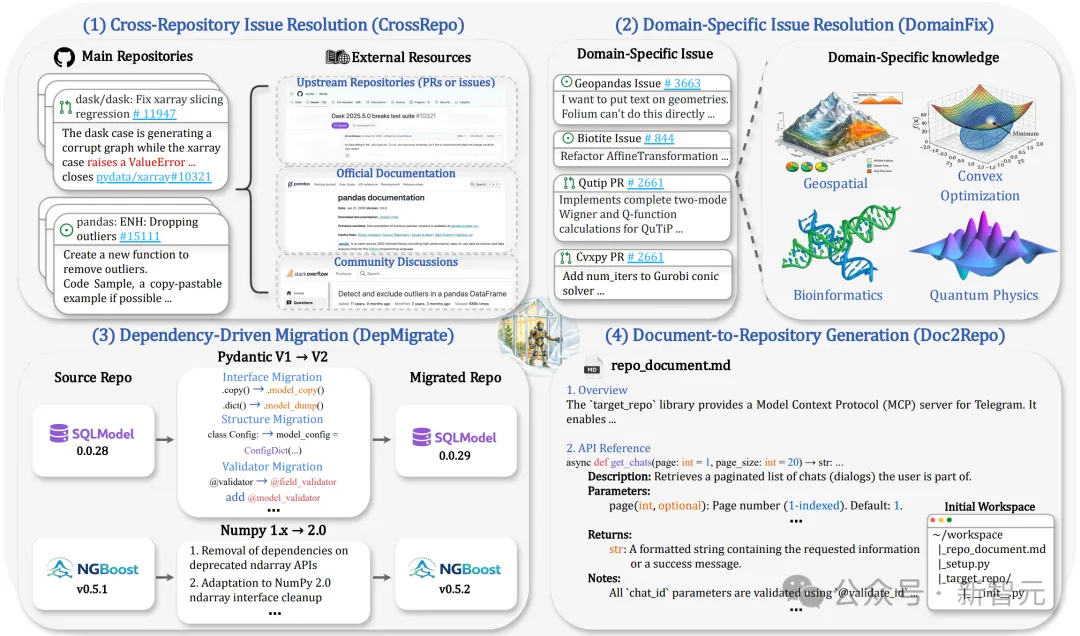
CrossRepo:答案不在这个仓库里(200条)
实际开发中,大量Bug的根因或修复思路并不在当前仓库内——开发者经常需要去翻阅上游仓库的issue、Stack Overflow的讨论帖、甚至去读另一个项目的源码才能定位问题。
BeyondSWE从3000个包含外部链接的GitHub PR中层层筛选,最终得到来自67个仓库、平均包含1.3个外部链接的200条高质量样例。
Agent仍然只在单一仓库中修改代码,但修复所需的关键信息存在于外部。这考察的不是「多仓库协同开发」的能力,而是对开源生态的广泛认知——这种认知既可以来自模型自身对生态的深度理解,也可以通过搜索外部资源来获取。
DomainFix:代码之外的知识壁垒(72条)
让一个后端工程师去修量子计算库的Bug,但他从没学过量子力学——这就是当前Code Agent在领域专业任务上面临的窘境。
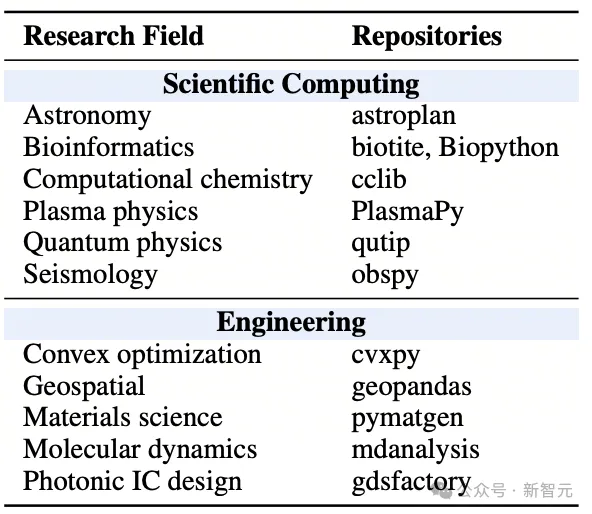
该任务与来自11个学科方向的领域专家合作构建,覆盖量子物理(QuTiP)、生物信息学(Biotite)、凸优化(cvxpy)、天文学(astroplan)、等离子体物理(PlasmaPy)等高门槛领域。
每道题经过三位领域专家独立审核,只有同时满足环境正确性、领域知识必要性和解法非平凡性的样例才能入选。Bug的正确修复不仅需要读懂代码,更需要理解背后的物理公式、数学概念或生物学原理——写对了语法,算错了物理,照样零分。
DepMigrate:整个仓库的系统性改造(178条)
NumPy 1.x升级到2.0、Pydantic v1到v2、Django 4.x到5.0——现代软件生态中,破坏性的依赖升级不是小概率事件,而是每个项目维护者都会反复面对的日常。这类任务的改动量和思维复杂度远超普通Bug修复,需要Agent精确掌握新旧API的差异,并在可能横跨数十个文件的代码库中完成一致、正确的全局迁移。
BeyondSWE识别了23个包含重大版本更新的核心依赖包,从7000个候选项中筛选出178条样例,覆盖120个仓库。每个样例的Docker环境已配置为依赖更新后的版本,而仓库代码仍停留在升级前——Agent面对的正是一个"依赖已升级、代码未适配"的真实困境。
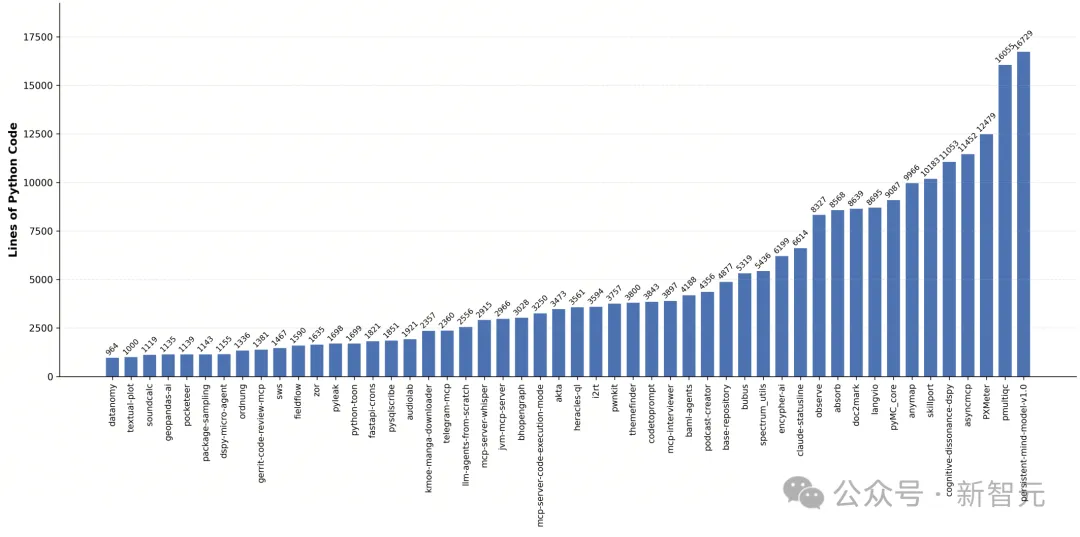
Doc2Repo:从白纸到系统(50条)
真实的软件工程往往不是从Bug开始,而是从一份设计文档或PRD开始。Agent面对的不再是「修什么」,而是「造什么」——架构怎么设计?模块怎么拆分?接口怎么实现?这是一种与Bug修复截然不同的工程能力。
50条样例全部收集自2025年新建的高质量仓库(持续活跃、至少3位贡献者、Star超过20),代码量从1000行到超过16000行不等,近四成样例超过4000行。
为防止Agent「背出」已有仓库的代码,评测中刻意隐去了仓库名称和目录结构——Agent只拿到一份纯文字的功能说明文档和一个空目录,一切从零开始。
数据质量:多轮校验保底线
BeyondSWE总计涵盖246个真实GitHub仓库、500条样例,平均每题涉及5.6个文件、209.9行代码。
在数据构建上,每条样例经过三个阶段的严格筛选:候选爬取、基于Agent的自动化Docker环境构建、以及严格的环境一致性验证(每条样例5次独立运行,P2P和F2P测试结果必须完全一致)。
此外,3位领域专家、5位资深软件工程师和5位专注Code Agent研究的博士生参与了全流程的人工校验。
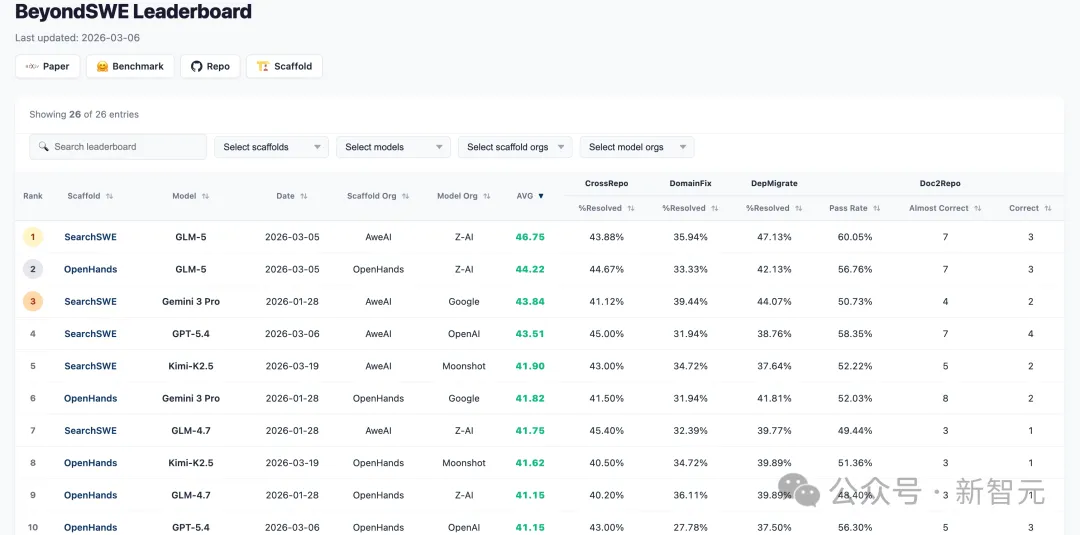
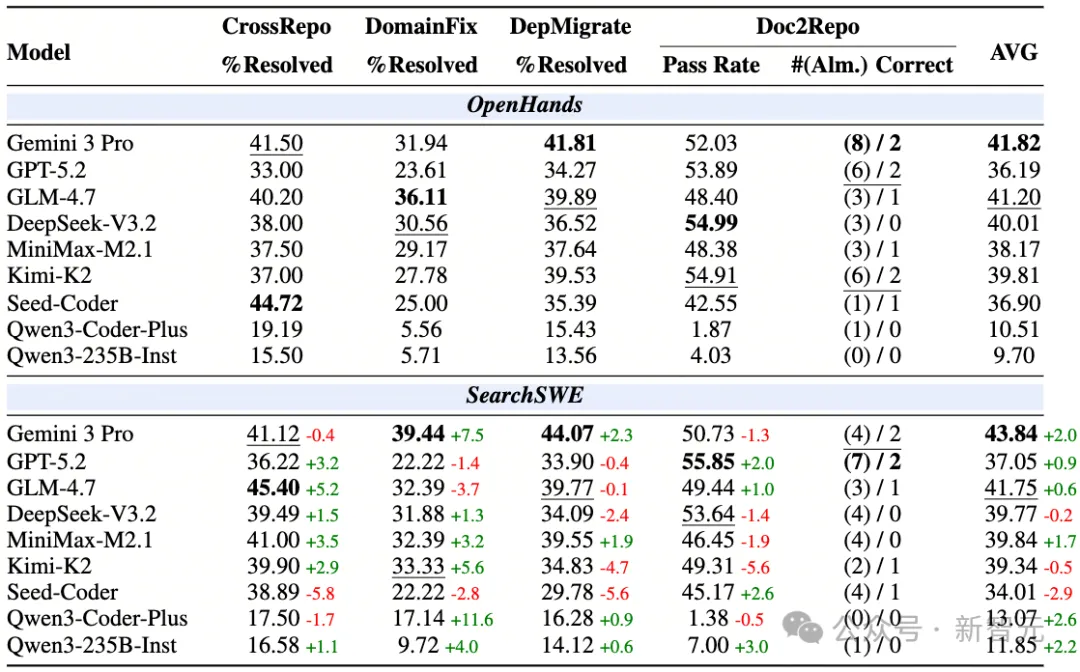
基于OpenHands框架,BeyondSWE对Gemini 3 Pro、GPT-5.2、DeepSeek-V3.2、GLM-4.7、Kimi-K2、Seed-Coder等一批前沿模型进行了全面测试。核心发现干脆利落:
没有任何模型的整体表现突破45%。 从SWE-bench的80%到BeyondSWE的45%,差距不是小幅波动,而是近乎腰斩。
深入各任务来看,失败模式各不相同:
没有全能选手:Seed-Coder领跑CrossRepo(44.72%),DeepSeek-V3.2拿下Doc2Repo最高通过率(54.99%),Gemini 3 Pro在DepMigrate最强(41.81%)。没有一个模型能在所有维度上同时称王,四类任务考察的确实是不同的能力。