匿名时代终结:大模型学会“人肉搜索”知识分子
1993年,《纽约客》杂志刊登了一幅著名漫画:一只狗坐在电脑前,对另一只狗说,在互联网上,没人知道你是一条狗[1]。
图源:Seedance生成
这幅漫画精准地捕捉了早期互联网的精神内核:匿名性赋予每个人平等的发言权,身份、地位、外貌都被暂时悬置,唯有思想和文字在流动。
图源:纽约客截图
三十多年后的今天,这个美好的假设正在被一种新技术悄然瓦解。
2026年2月,苏黎世联邦理工学院与人工智能公司Anthropic联合发表了一篇论文,标题直白得令人不安:Large-scale online deanonymization with LLMs(基于大语言模型的大规模在线去匿名化)[2]。研究团队展示了一个令人震惊的事实:在AI面前,互联网匿名正在以肉眼可见的速度崩塌。
当人肉搜索成为流水线作业
让我们从一个假设开始。
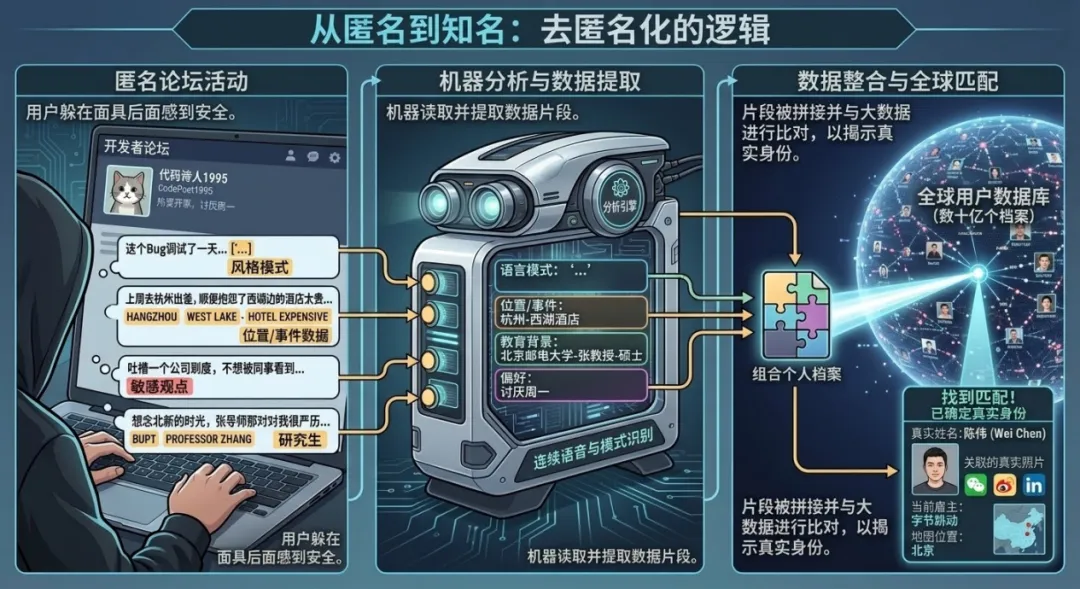
假设你在某个技术论坛注册了一个小号,ID是代码诗人1995。你从未透露真实姓名,头像是一只猫,简介里只写着热爱开源,讨厌周一。你在论坛上讨论编程问题、吐槽公司制度、偶尔发表一些不想被同事看到的观点。你觉得很安全,毕竟这只是个马甲。
但现在,有一台机器正在阅读你所有的发言。
它注意到你喜欢用特定的标点符号组合是三个句号加空格;它发现你提到上周去杭州出差时顺便抱怨了西湖边的酒店太贵;它记得你说过研究生是在北邮读的,导师姓张。它把这些碎片拼接起来,然后在一个拥有数十亿用户数据的互联网上进行匹配。
90%的精度,68%的召回率,这是论文中报告的数字[2]。换句话说,这台机器有接近七成的概率,能从茫茫人海中把你代码诗人1995的真实身份找出来。
这不是科幻小说的情节。研究团队用三个真实场景验证了这一攻击的有效性:将Hacker News用户与LinkedIn档案匹配、跨Reddit不同社区识别同一用户、甚至仅凭一个用户在不同时间段的发言就将其分身关联起来。在每一项测试中,基于大语言模型的方法都碾压了传统算法,后者的成功率几乎为零。
从神话到科学:去匿名化的技术跃迁
要理解这场变革的意义,我们需要回溯历史。
2006年,Netflix举办了一场著名的算法竞赛:公开一亿条电影评分数据,悬赏100万美元给能最好地预测用户评分的团队。然而,研究者很快发现,即使数据经过匿名化处理,用户ID被随机替换,仍然可以通过交叉比对其他公开数据库(如IMDb)重新识别出具体个人。一位德克萨斯大学的研究生甚至成功识别出了Netflix数据集中包括她自己在内的多位用户[3]。
这就是传统去匿名化的困境:它依赖于结构化数据,需要精心设计的交叉比对,本质上是一种手工艺术。门槛高、规模小、成本昂贵,只有具备相当资源的机构才能实施。
但大语言模型改变了这一切。
论文中描述的攻击流程看似简单,却蕴含着深刻的范式转变。整个系统分为三个核心模块:
第一步是特征提取。传统方法需要人工定义什么是身份特征,比如姓名、地址、电话号码。但大语言模型可以直接阅读原始文本,自动发现那些人类难以形式化的线索。比如你习惯在句尾加上哈哈哈,你提到周末总是去五道口那家书店,你对某个技术框架有特定的称呼方式。这些看似琐碎的细节,在模型眼中构成了独特的身份指纹。