直击GTC,老黄就指着你烧token了硅星人
今年显然又是英伟达这家33岁公司又一个关键时刻,人们像期待数码产品一样期待它的芯片更新,对超预期的财报甚至都提不起兴趣,眼看有些江郎才尽的时刻,黄仁勋又带来了新的故事。
3月16日,在2026年英伟达GTC大会上,黄仁勋做了万众期待的主旨演讲。人们看待英伟达,关心和担心的都是它的增长。而今年GTC,一个花20亿美金收购来的Groq,一个突然就改变了一切并看起来解决了“应用普及问题”的OpenClaw,成了增长故事里的绝对主角。
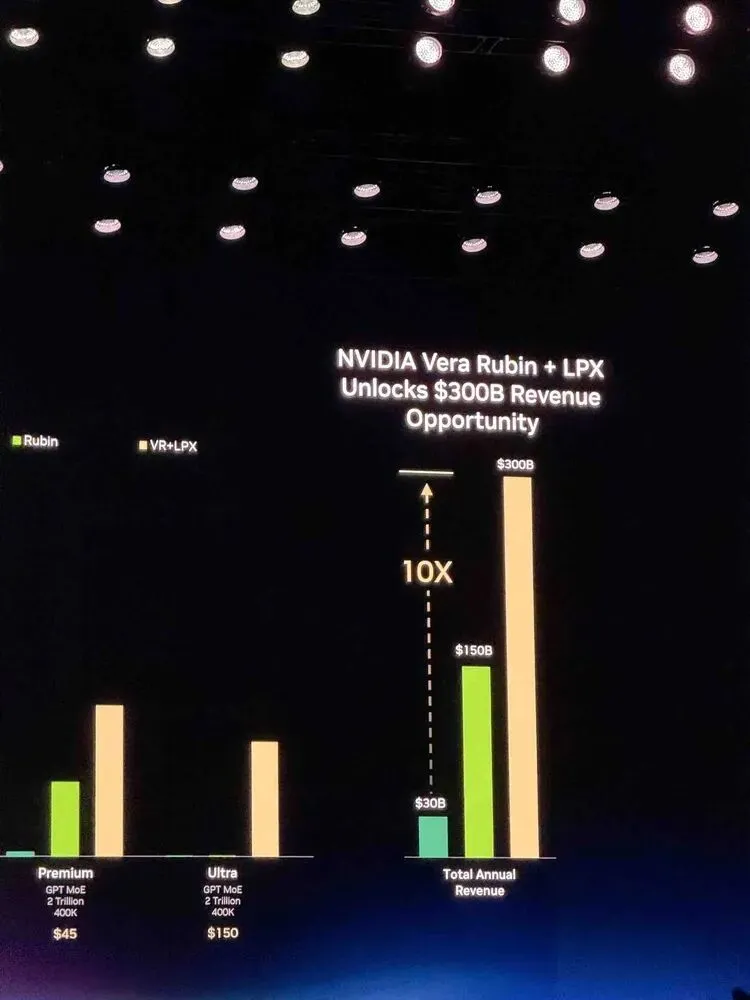
Groq的新芯片融入英伟达体系后,英伟达宣称会给它的客户们解锁一个3000亿美金的增量市场;
同时英伟达也会把Groq更深入融入下一代芯片架构Feynmann 里;
而在他绝对不会迟到的“小龙虾”狂热里,黄仁勋要让英伟达变成OpenClaw们的底层,再次上演一出CUDA同样的戏码。
尽管相比GTC最辉煌的那些发布,今年的整个发布的大多时间显得有点乏善可陈,但这些已经足够让黄仁勋信心满满,他表示:
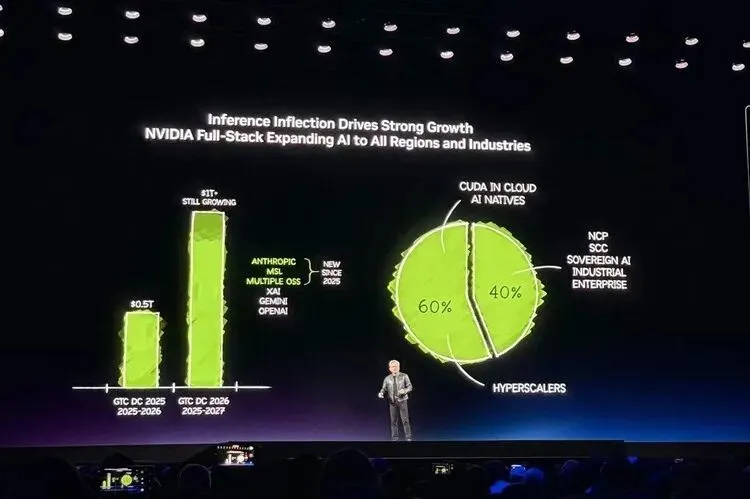
2025年到2027年,英伟达的芯片生意将会继续上涨,涨到1万亿美金。
Vera Rubin + Groq,七颗芯片合体
黄仁勋展示了他形容为全新的AI基础设施层的全貌。
他不再举着一颗芯片说“this is our new GPU”了。他把整个Vera Rubin机架搬上了舞台,说这一次英伟达想的是整套系统,从芯片到软件到互连,端到端垂直整合,作为一台超级计算机来优化。
上一代Blackwell Ultra已经实现了对比Hopper 50倍的吞吐效率提升,而Vera Rubin + Groq在此基础上又把前沿推到了新的区间,这套系统由七颗芯片组成。核心Rubin GPU采用台积电3nm工艺,双芯片封装,336B晶体管,配备288GB HBM4内存和22TB/s带宽,NVFP4推理性能达到50 PFLOPs,比上一代Blackwell提升5倍,训练性能35 PFLOPs,提升3.5倍。配套的Vera CPU是88核定制Arm架构(代号Olympus),176线程,全球首款在数据中心采用LPDDR5的CPU,专门为Agent推理场景下的高单线程性能和数据处理做了优化。黄仁勋说这颗CPU独立卖“肯定会成为数十亿美元的业务”。
但今晚真正的新闻是第七颗芯片,Groq 3 LPU。去年圣诞夜英伟达花200亿美元拿下Groq的技术授权和核心团队,今天是首次产品落地,而且已经在量产。
为什么需要Groq?
黄仁勋在台上讲得很清楚,GPU擅长高吞吐的并行计算,做prefill和attention很强,但在超高速token生成这个区间会力不从心。他的原话是NVL72在超过400 tokens/s/user的区间“runs out of steam”(跑不动了)。而Groq的LPU是一种完全不同的处理器,确定性数据流架构,芯片上全是SRAM,没有运行时动态调度,编译器在编译阶段就把每个时钟周期的计算和数据搬运全部排好了。这种架构天然适合低延迟的decode和token生成。
问题在于SRAM虽快但容量极小。单颗Groq 3 LPU只有500MB SRAM,而Rubin GPU是288GB HBM4,差了500多倍,根本存不下万亿参数的模型。英伟达的解法是用一套叫Dynamo的软件把推理过程拆成两半,Rubin负责prefill和attention,处理上下文需要大量算力和大容量内存;Groq负责feed-forward部分的decode和token生成,需要极低延迟和极高带宽。两者通过以太网紧耦合,延迟减半。
黄仁勋管这个叫disaggregated inference(解耦推理),并且总结说高吞吐和低延迟本质上enemies of each other(彼此矛盾),而Groq就是解决这个矛盾的那一半拼图。
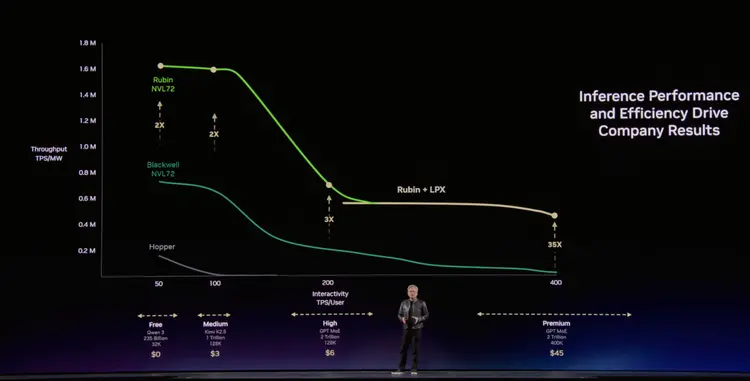
舞台上的那张对比图视觉冲击很强。
左边一颗Rubin GPU,288GB HBM4、22TB/s带宽、50 PFLOPs。
右边一排8颗Groq 3 LPU组成的阵列,4GB SRAM、1,200TB/s SRAM带宽(Rubin的55倍)、9.6 PFLOPs。
两种极端的处理器,统一成一个推理系统。Groq 3 LPX整机把256颗LPU装进一个机架,提供128GB SRAM、40PB/s带宽、315 PFLOPS推理算力和640TB/s互连带宽。
整套NVL72系统100%液冷,用45度热水冷却,把原来花在空调上的能耗省回来给计算用。安装时间从两天压缩到两小时。第六代NVLink提供3.6TB/s全互连带宽。首款CPO(共封装光学)交换机Spectrum X已经量产。
目前,微软Azure已经跑起了第一套Vera Rubin机架,Satya Nadella在演讲期间直接发消息确认。
黄仁勋还给了一个极其直观的对比,同一个1GW数据中心,两年内token生成速率从2200万提升到7亿,350倍。他说这就是极致协同设计的力量。
1万亿GPU,和新的商业模式可能
在演讲里,黄仁勋再次给出数据的指引。
去年GTC他给出的关于英伟达产品的需求估算是5000亿美元(覆盖Blackwell和Rubin到2026年),而今年直接翻倍,他说现在看到的是:
到2027年至少1万亿美元。
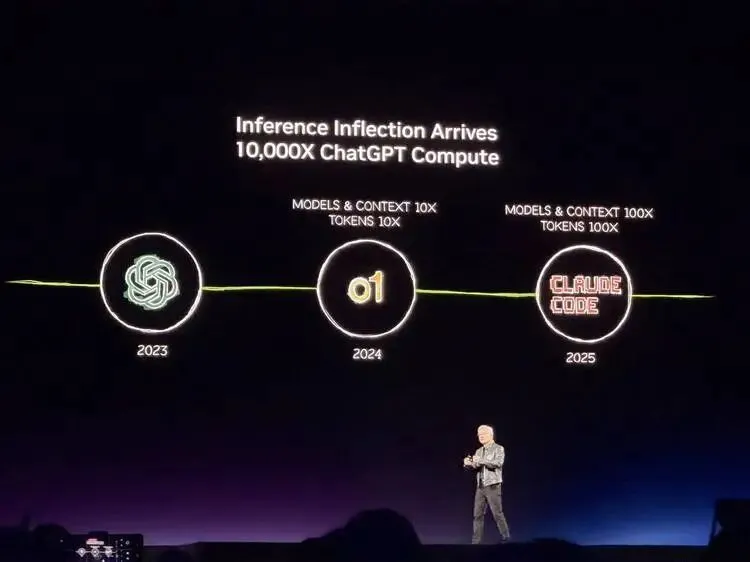
驱动力是他反复提到的“推理拐点”,从ChatGPT到o1再到Claude Code,AI从能聊天变成能推理再变成能干活,每一步跳跃都让单次推理需要的算力暴增,而使用量也在同步起飞。黄仁勋说Claude Code是第一个agentic model,英伟达100%的软件工程师都在用。
然后他用一张图把这个宏观判断翻译成了具体的商业逻辑。
整场演讲最值得反复看的就是这张,标题叫inference Performance and Efficiency Drive Company Results。
纵轴是吞吐量(TPS/MW,每兆瓦每秒生成的token数),横轴是交互速度(TPS/User,每用户每秒拿到的token数)。横轴越往右意味着AI越“聪明”,模型更大、上下文更长、思考链更深,但吞吐量会下降,因为资源被单个用户的推理任务占用了更多。高吞吐和低延迟本质上矛盾。