今天,硅谷正在回归“AlphaGo模式”51CTO技术栈
这两天,硅谷的 AI Lab 圈正在达成一个新共识:
“AlphaGo 模式”已回归!
就在今天,Google DeepMind 的 Demis Hassabis 、OpenAI 的o1系列核心人物 Noam Brown 同时认可了AlphaGo的深远影响:LLM 现在的处境就像当年的 AlphaGo,已经学完了“人类棋谱”(互联网数据),下一步是通过“自我博弈”和“模拟推演”来超越人类。
Google和OpenAI顶尖大神盛赞“AlphaGo模式”
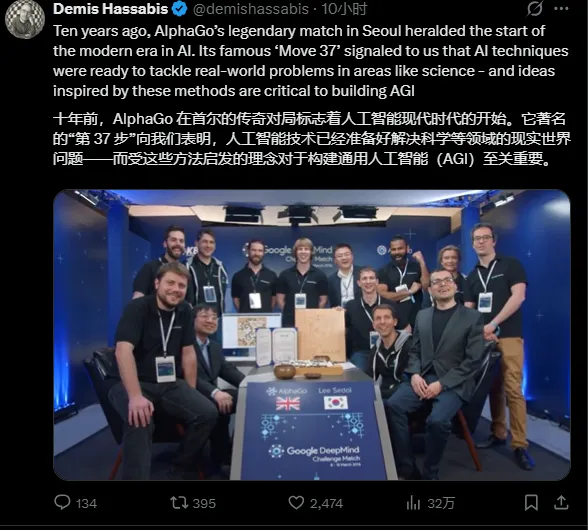
时值“AlphaGo 战胜李世石”十周年,Demis 在 X 上发推表示:十年前,AlphaGo 的 “第 37 步” 向人们表明,AI技术已经准备好解决科学等领域的现实问题,而这些方法启发的理念对于构建 AGI 至关重要。
Demis 今天还发表了一篇纪念AlphaGo十周年的博文:《从游戏到生物学及更多领域:AlphaGo 影响力的十年》,文中他提到:
通过证明自己可以驾驭围棋盘上巨大的搜索空间,AlphaGo 展示了 AI 帮助我们更好理解物理世界复杂性的潜力。
而另一位在AI“搜索与博弈”的 OpenAI 顶级大神 Noam Brown,是打造出 o1 系列模型的关键人物,同样感慨:如今的推理模型与AlphaGo 在底层逻辑高度相似!
他转发了上面 Demis 发的帖子,并颇有总结意味的表示:
当前前沿推理模型背后的原理竟然与 AlphaGo 惊人相似:
模拟人类数据→扩展推理计算规模(以前是蒙特卡洛树,现在是思维链)→利用强化学习超越模仿。
不得不提的是,10 年后的今天,李世石同样发表了类似的感言:
“我相信 AlphaGo 留给我们最大的启示,是对 AI 时代的一次确定性预演——它证明了 AI 并非某种遥远、模糊的未来,而是已经来到我们门前的现实。”
斯坦福教授更进一步:
模拟就是人工智能的下一个前沿
除了以上两位 AI 大神,斯坦福教授、simile 联合创始人 Percy Liang 在今天则更进一步的指出了一点:
很明显,模拟(simulation)就是AI的下一个前沿领域。
就像 AlphaGo 击败李世石、赢得国际数学奥林匹克金牌一样,所有的令人印象深刻的AI成就都发生在有明确的环境和奖励机制。
Percy Liang认为,同样地,AI 一样能在虚拟“Docker容器”中处理现实世界中模糊奖励和高风险的社会场景,实现未来预测和假设优化。
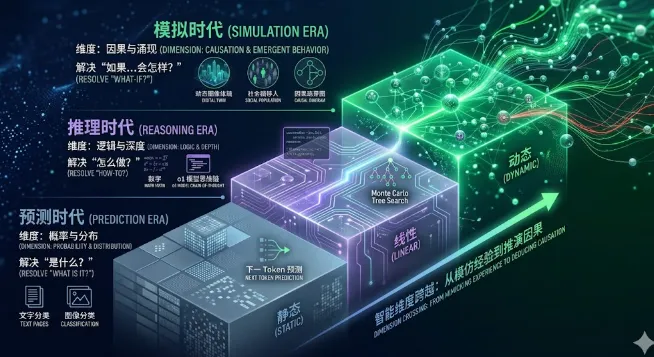
他给出了一个新的时代:模拟时代。
在预测时代,我们实现了训练通用模型以高精度对文本和图像进行分类。
在推理时代,我们正让模型能够解决具有挑战性的数学、编程以及其他复杂的多步骤问题。
而在模拟时代,AI的研究核心则变成了如何足够深刻地理解我们自身及其所处环境,以至于能够推演任何可以想象的“如果……会怎样?”(what if?)的场景。
注:图片由Gemini生成
为什么“模拟”是通往 AGI 的必经之路?
其实关于“simulation 成为下一个前沿”这种趋势,尤其今年以来,已经初见端倪。
前不久,AI教母、斯坦福教授李飞飞在 Cisco AI 峰会上就曾透露,目前正在研究的世界模型 Marble,其训练数据构建策略就来自一种混合策略:真实+仿真多模态数据的混合叠加。
另外注意,特斯拉的自动驾驶模型也是更早采用这一策略的前沿玩家。
为什么 simulation 会被这些顶尖Lab、企业所押注呢?
Percy 教授解释了一个重要的原因。
现在的预测和推理模型无法解决“那些错综复杂、关乎现实世界的问题”,因为问题的答案取决于“众多人类长期互动所产生的最终结果”。
预测模型可以生成最优行动方案,但却无法解释其背后的原因。
推理模型可以讲述故事,但这些故事未必基于现实。
模拟为世界上最复杂的问题提供了完整且可审计的追踪记录。
“模拟将会发生什么”比“预测该做什么”更难。
所以,Percy 教授认为,接下来模型圈要攻克的是一个可以弥补“因果之梯”的模拟模型时代!
而这类模型有三点前沿挑战和方向:
其一,目前的语言模型无法捕捉人类行为的细微差别,如何开发高保真度的人类及其环境模型?方向:研究新的数据收集策略来捕捉这些潜在知识,并训练能够外推至新情境的基础模型。
其二,如何高效地进行大规模模拟。方向:开发多尺度模型,以便模拟整个人口随时间推移的宏观和微观层面的动态变化。
其三,如何为“simulation”建立信任?方向:模型必须针对可能的结果分布生成经过校准的概率估计。
AI的所有战线,都汇聚到 AlphaGo模式上!
虽然业界对于“Scaling Laws撞墙”的争议一直没有定论。但至少在“更大参数规模”方面,“大力出奇迹”的故事显然已经按下了暂停键。
但显然,AI领域依旧在快速地取得进步。经历了 GPT 模型疯狂的三年之后,我们愈发看到三条战线都似乎已经汇聚到十年前的“AlphaGo模式”。
目前,全球最顶级的 AI Lab 或研究者,都在沿着这条路径布局,只是侧重点有所不同:
OpenAI 的 Noam Brown:侧重于“推理时计算”。让模型在回答前通过自我对弈(Self-play)寻找最优解,就像人在考试前先在脑子里草拟答案。
DeepMind 的 Demis Hassabis:侧重于“科学发现”。将模拟作为科学实验的加速器。从 AlphaFold(蛋白质)到 AlphaProof(数学),通过构建高保真的物理模型,寻找新材料、新蛋白质,破解疾病谜题。
斯坦福大学、Simile 联合创始人Percy Liang :侧重于“高保真模拟器”。目标是构建高保真智能体,在“what if”的虚拟世界实验室中,预演复杂的社会问题:裁员对士气的影响、三年后公司文化的演变、甚至模拟新税法对底层消费的长期冲击。