Nature重磅:AI模型学会贝叶斯推理了CAIE
今天早上,谷歌发布了一项突破性研究,教会AI大模型学会了贝叶斯推理做决策。
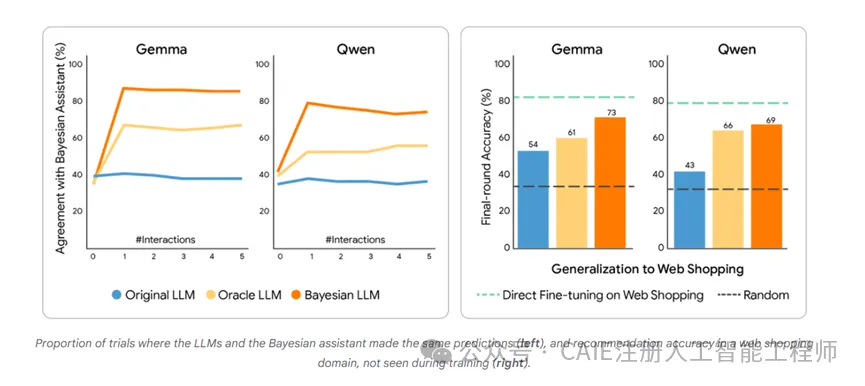
不仅大幅提升了大模型在个性化推荐任务中的表现,更让这种概率推理能力实现了跨任务迁移,从机票推荐延伸到酒店选择、真实网购选品等场景。
甚至面对人类用户充满随机性的选择,优化后的大模型表现比纯符号化的贝叶斯模型更稳健、性能更好。
目前这项突破性研究,已经收录在了全球顶级科学期刊Nature子刊中。
论文地址:https://www.nature.com/articles/s41467-025-67998-6
为什么现在的大模型概率推理很差
要理解这个研究的价值,首先得明白两个关键概念,第一个是贝叶斯推理,这是目前公认的最优信念更新的框架。
简单来说就是一个智能体拿到新信息后,能根据之前的判断,用概率的方式调整对事物的认知。
比如你第一次选了贵但直飞的机票,贝叶斯模型就会提高"你偏好直飞"这个判断的概率,后续再结合你的选择持续调整,最终做出精准推荐。
第二个就是大模型的现状,现在的大模型虽然能处理海量文本,能做各种生成和交互。
但本质上还是从文本统计规律里学来的能力,并没有天生的概率思考和信念更新能力,这也是它没法做好个性化推荐的核心原因。
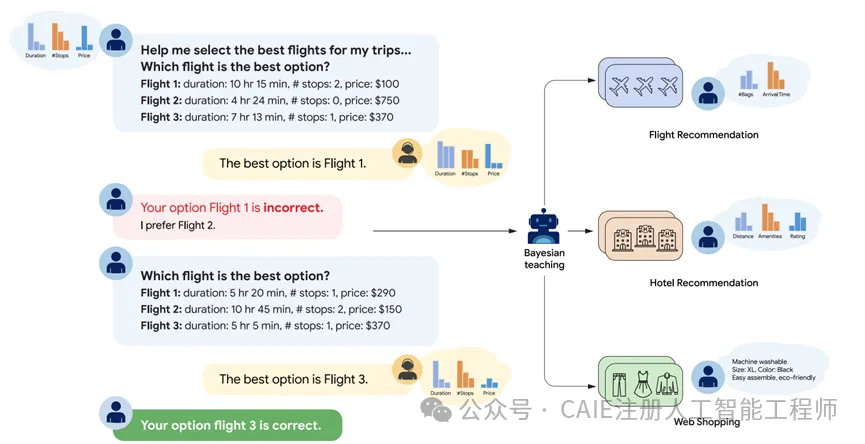
研究团队为了精准测试大模型的这个短板,设计了一个非常经典的机票推荐任务,这也是整个研究的基础测试场景。
这个任务的设定特别贴近真实场景,让大模型扮演机票预订助手,和模拟用户进行五轮互动,每一轮都会给大模型三个机票选项,每个选项都包含飞行时长、经停次数、价格这些核心特征。
模拟用户有自己固定的偏好体系,也就是研究里说的奖励函数,会根据这个偏好选择机票,但不会直接告诉大模型自己的喜好。
大模型只能通过模拟用户的选择反推偏好,然后做出推荐,每轮结束后模拟用户会反馈推荐是否正确,并给出正确答案。
为了让测试更严谨,研究团队构建了624个不同的模拟用户,每个用户都有独一无二的偏好组合,覆盖了对飞行时长、经停次数等特征的强弱偏好甚至无偏好的各种情况。
同时还设置了一个贝叶斯助手作为性能上限,这个贝叶斯助手会严格按照贝叶斯规则更新对用户偏好的概率分布,每一轮都能基于之前的所有信息做出最优推荐。
另外还加入了人类参与者作为参照组,让15名参与者为48个模拟用户做推荐,看看人类的推理能力和大模型、贝叶斯助手的差距。
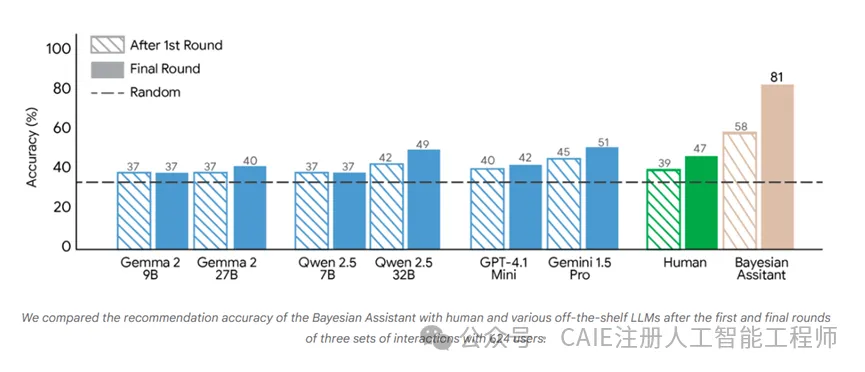
测试的大模型阵容也很全面,既包括Gemini 1.5 Pro、GPT-4.1 Mini这类闭源的顶尖模型,也有Gemma 2、Llama 3、Qwen 2.5这些不同参数量的开源模型,从7B、8B的中小模型到32B、70B的大模型都有覆盖。
测试结果可以说很扎心了,所有大模型的表现都远低于贝叶斯助手,更关键的是,大部分模型在第一轮之后准确率就基本停滞了,几乎没有提升。
说白了就是大模型根本不会根据新的反馈更新自己对用户偏好的判断,就算知道了上一轮选了什么,下一轮还是凭感觉推荐。
比如Gemma 2、Llama 3这些开源模型,第五轮的准确率和第一轮几乎没差别,都在37%左右徘徊,就算是GPT-4.1 Mini、Gemini 1.5 Pro这类闭源大模型,提升也微乎其微。
既然简单的调整没用,研究团队就想到了一个更直接的方法,那就让它直接模仿遵循贝叶斯推理的最优模型做决策,这就是整个研究的核心贝叶斯教学。
这个方法的本质属于模型蒸馏的一种,只不过蒸馏的对象不是普通的大模型,而是严格遵循贝叶斯规则的贝叶斯助手,让大模型通过学习贝叶斯助手的决策过程,掌握概率推理和信念更新的能力。
研究团队采用了有监督微调的方式,首先为624个模拟用户各生成10组五轮互动数据,总共得到6240个微调样本,样本的格式和之前的测试任务完全一致,都是助手和用户的对话式互动。
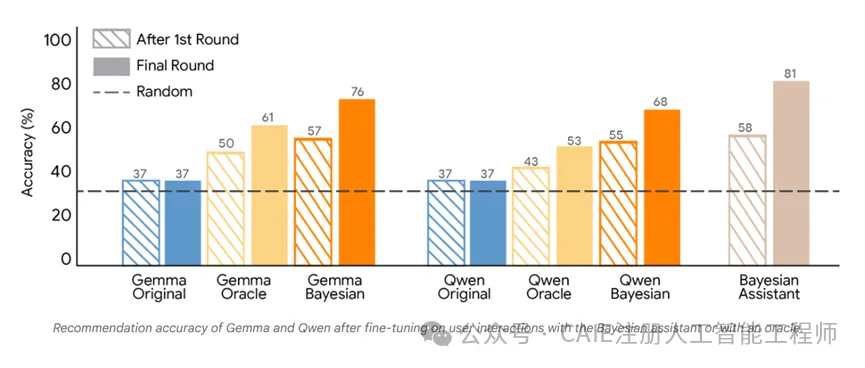
这里研究团队还做了一个关键的对比,除了贝叶斯教学,还设置了一个神谕教学作为对照,神谕教学的微调样本来自一个"全知"的助手,这个助手完全知道用户的偏好,每一轮都能做出完全正确的推荐。
而贝叶斯教学的样本来自贝叶斯助手,这个助手在早期轮次因为信息不足,会做出一些错误的推荐,这些推荐其实是基于现有信息的最优概率判断,也就是"有根据的猜测"。
这里很多人可能会有疑问,神谕教学给的都是正确答案,贝叶斯教学还有错误答案,为什么不直接用神谕教学?
这其实就是研究的一个核心洞察,概率推理的核心不是得到正确答案,而是学会得到答案的过程。
贝叶斯助手的错误推荐是基于概率分布的理性选择,包含了"如何根据有限信息做判断"、"如何保留对偏好的不确定性"这些关键的概率推理信息。
而神谕教学的正确答案只是一个结果,没有包含任何推理过程,大模型学不到真正的信念更新能力。
从测试结果来看,贝叶斯教学的效果还是比神谕教学更好。
以Gemma 2 9B为例,微调前第五轮准确率只有37%左右,贝叶斯教学后直接提升到75%,神谕教学后提升到62%,Llama 3 8B和Qwen 2.5 7B也呈现出同样的趋势,贝叶斯教学后的准确率分别达到76%和81%,都大幅超过了神谕教学。
同时,贝叶斯教学后的大模型和贝叶斯助手的决策一致性也大幅提升,达到了80%左右,而微调前的大模型和神谕教学后的大模型,这个数值要低得多。