MIT、剑桥、斯坦福:AI Agents的现状与困境夕小瑶科技说
最近 AI 圈最火的一个新词,叫"SaaSpocalypse",SaaS 末日。
这两周,Claude Code 上了个 COBOL 现代化功能,IBM 当天暴跌 13%;又上了个安全扫描功能,一口气翻出 500 多个此前藏了几十年的高危漏洞,网安股集体跳水。彭博社甚至专门做了一期播客讨论“哪些 SaaS 公司能活下来”。
恐慌的核心逻辑只有一句话:Agent 不是 SaaS 的用户,Agent 是 SaaS 的替代者。
传统 SaaS 卖的是什么,把工作流做成界面,让人坐在那里点。收费逻辑是按座位数——你有多少员工用,就收多少钱。
Agent 出来之后,这件事变了:Agent 可以直接调 API,自动完成任务,根本不需要有人打开界面。给人用的界面的价值就压缩了。
市场的恐慌不是空穴来风。
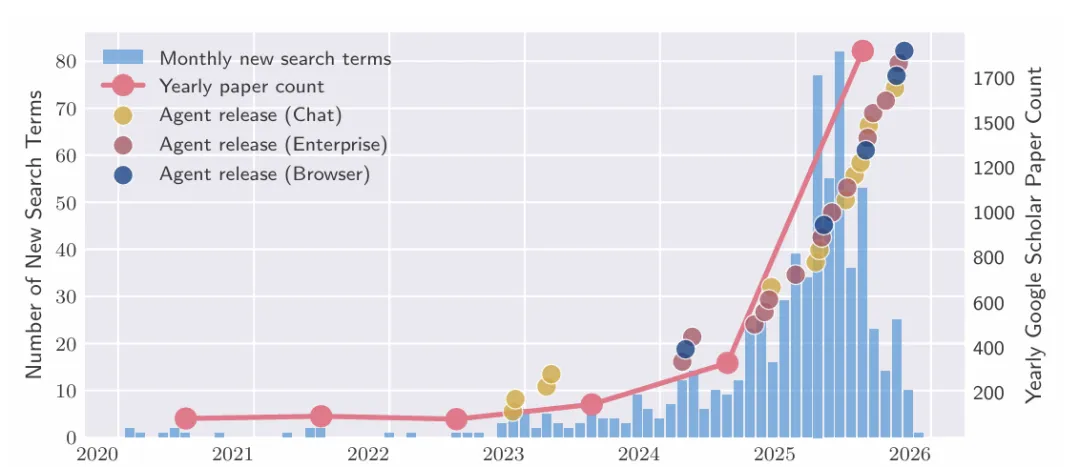
这是一张 AI Agent 领域从 2020 年到 2026 年初的态势统计图。
蓝色柱状图——每月新增的 Agent 相关搜索词数量。从 2023 年逐步上涨,2025 年中达到峰值(单月接近 80 个新词)。
粉色折线——Google Scholar 上每年关于 Agent 的论文数量。从 2024 年开始陡峭上升,到 2025-2026 年已接近每年 1800 篇。。
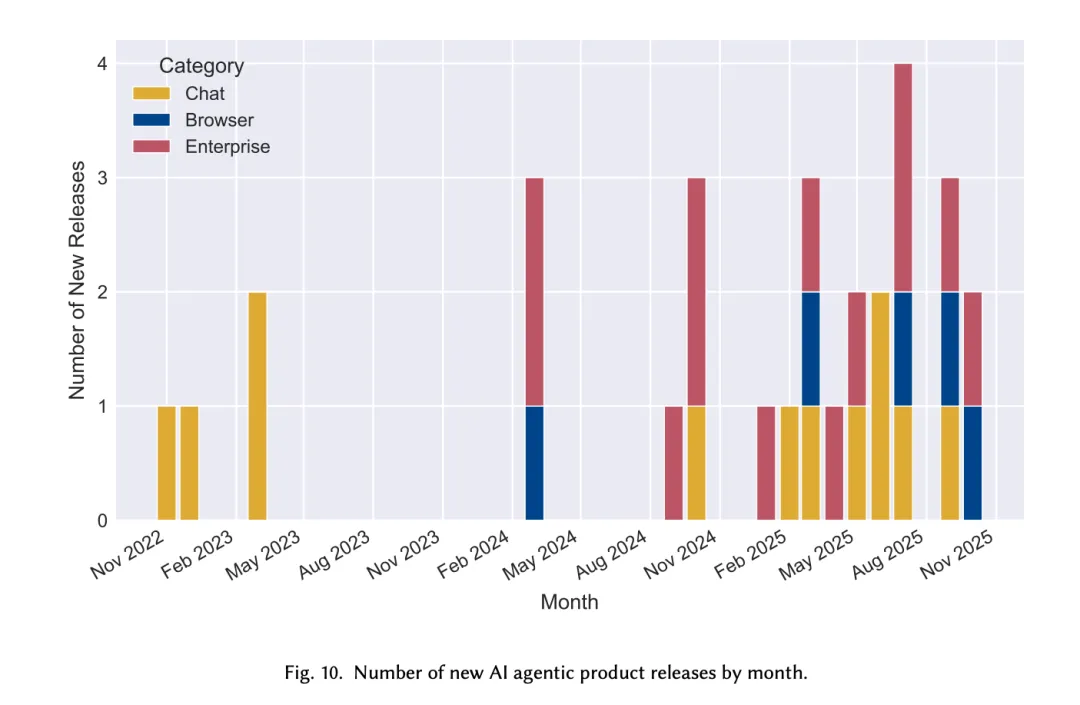
三种圆点——标注了各类 Agent 产品的实际发布节点。可以看到 2024 年下半年到 2025 年是集中爆发期,各类 Agent 产品密集上线。(具体看下面这张图)
从趋势数据看, Agent 赛道在 2024-2025 年进入了爆发期。学术研究、产品发布、市场关注度,三者同步在一路飙升,而且还没有明显见顶的迹象。
Agent 爆发是事实,但是,Agent 现在到底发展到哪一步了?它真正能干什么、有多自主、谁在控制它、出了事谁负责?
这两天,看到 MIT 发了一篇系统性的报告,正好能对这个问题带来一些更深的理解。
所以本文的目的是在满屏讲 Agent 的信息流里,给大家对抗一下噪声。不聊哪个 Agent 更强、跑分更高,用这个报告里的数据,带你认清 Agent 存在什么问题,而不是只停留在它能帮我干活这一层。
首先,这篇报告是 MIT 联合剑桥、斯坦福、哈佛法学院等机构,发布的一份 2025 AI Agent Index 报告,对 30 个当前最主流的顶级 AI Agent 做了全面分析。
在进入数据之前,有一个认知基础要先建立——「Agent」这个词现在被滥用得厉害,凡是能调工具的 AI 都敢叫自己 Agent。
MIT 这份报告给出了目前最严格也最清晰的入选门槛,四个条件缺一不可:
自主性:能在没有持续人工干预的情况下运行,自己做有实质影响的决策。
目标复杂度:能拆解高层级目标,做长链路规划,至少能连续自主调用 3 次以上工具,不需要你手把手给步骤。
环境交互:有写权限,能真正改变外部世界——不是只说话,是真的动手。
通用性:能处理模糊指令,适应新任务,不是只会一招的窄域工具。
满足这四条,还要有足够的市场影响力(搜索量、估值、或签署了前沿 AI 安全承诺),才能进入这份名单。
从 95 个候选系统里,最终筛出 30 个。
研究团队把 30 个 Agent 分成三类,每类的技术架构和风险特征都完全不同。团队对全部 Agent 设计了 45 个维度,一共统计了 1350 个数据字段,划分成六个大维度。
维度一:Agent 分类——能做什么?
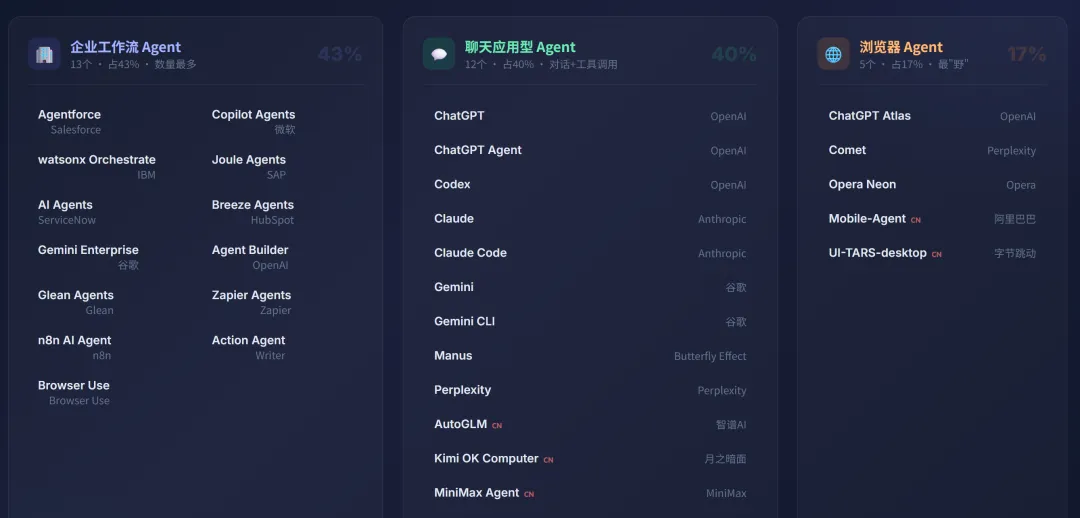
Chat 类(12 个)——对话界面 + 工具调用
Anthropic Claude、Claude Code、Google Gemini、Gemini CLI、Kimi OK Computer、Manus AI、MiniMax Agent、OpenAI ChatGPT、ChatGPT Agent、OpenAI Codex、Perplexity、Z.ai AutoGLM 2.0
浏览器类(5 个)——直接控制电脑和网页
Alibaba MobileAgent、ByteDance Agent TARS、OpenAI ChatGPT Atlas、Opera Neon、Perplexity Comet
企业工作流类(13 个)——自动化业务流程
Browser Use、Glean Agents、Google Gemini Enterprise、HubSpot Breeze Studio、IBM watsonx Orchestrate、Microsoft Copilot Studio、OpenAI AgentKit、SAP Joule Studio、Salesforce Agentforce、ServiceNow AI Agents、WRITER Action Agent、Zapier AI Agents、n8n Agents
30 个 Agent 里,21 个来自美国,5 个来自中国,剩下 4 个分布在德国、挪威和开曼群岛。
中国产品上榜 5 个——Kimi、MiniMax、Z.ai、Alibaba MobileAgent、ByteDance TARS。Manus 注册在开曼群岛,但团队和产品来自中国。如果算上,国产占比 20%。
23 个完全闭源。
只有前沿实验室和中国开发者在跑自研模型,其余全部依赖 GPT、Claude、Gemini 御三家。
30 个 Agent 的宣传用途高度集中在三件事上:
12 个在做研究与信息整合,从消费者聊天助手到企业知识平台都有;11 个在做业务流程自动化(HR、销售、客服、IT),主要集中在企业类产品;7 个在做 GUI 操作,替你填表、下单、订票
这三个方向叠加在一起,基本覆盖了一个普通知识工作者一天的大部分工作内容。
值得注意的是,中国的 GUI 类 Agent 有一个明显特点:更多针对手机端和电脑端的操作(3/5),而不是纯网页浏览。Alibaba MobileAgent、Kimi OK Computer、ByteDance TARS 都走这条路线,和美国产品侧重网页浏览有所不同。
企业类最多(13 个),但存在感最弱——因为这些产品不直接面向消费者,搜索量低,但实际部署规模和商业影响力远超前两类。像 Microsoft Copilot Studio、Salesforce Agentforce、ServiceNow 背后是真实的企业合同和数据。
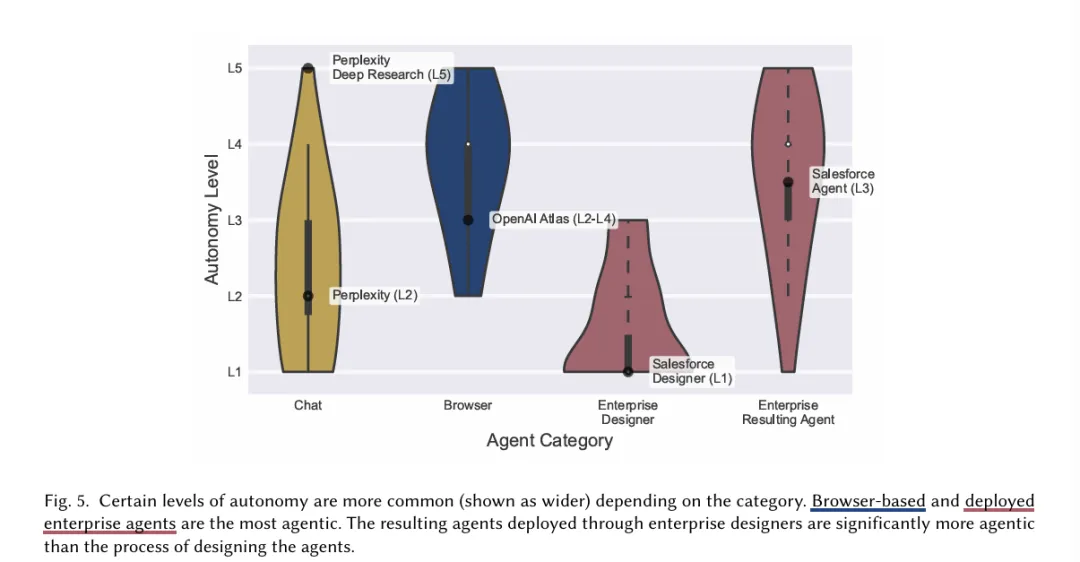
维度二:自主程度——五级框架
这份报告里用了一个目前最清晰的 Agent 自主度分级框架,五个等级:
L1:人主导,Agent 只负责执行具体指令
L2:人与 Agent 协作规划,共同执行
L3:Agent 主导执行,人在关键节点审批
L4:Agent 自主执行大部分,人只作为审批者
L5:Agent 完全自主,人只是旁观者
结论是:浏览器类 Agent 普遍在 L4-L5。
L4-L5 意味着什么?意味着你启动任务之后,中间基本没有干预机会。Agent 会自己决策、自己执行、自己处理异常,你能做的只是等结果,或者在某些系统里点一个"确认"按钮。
但是,就是因为如此,经常会有 Agent 删库跑路的事件。比如最近 Meta 的安全总监被 Openclaw 删光了邮件。
虽然很多企业级 Agent 在产品宣传材料里普遍强调 L1-L2,但真正部署到企业环境运行时,实际自主度就失控飙到 L3-L5。。。
以为买进来一个辅助工具,实际上在运行一个自主决策者。
维度三:谁在给 Agent 当地基?
技术架构层面,这份报告提到了一个高度集中的底层依赖结构。