AlphaEvolve再进化:「养殖」算法,碾压所有人类新智元
DeepMind最新论文:用AlphaEvolve把算法源代码当基因组,让Gemini充当遗传算子,对博弈论算法进行「自然选择」。进化出的全新算法,采用了人类研究者从未想过的反直觉机制,在几乎所有测试博弈中碾压人类花了几十年设计的最优方案。AI不再只是执行算法——它开始自己发明算法了。
谷歌DeepMind刚刚放了一个大卫星。
他们用AlphaEvolve硬生生「繁殖」出了一批全新的博弈论算法。
这些算法不仅在性能上全面碾压人类花了几十年精心设计的经典方案,更令人头皮发麻的是:
它们使用的底层机制,反直觉到没有任何一个人类研究者会想到去尝试。
代码即基因组。LLM即造物主。
这一次,AI不是在帮人类写代码——它在自己发明数学。
这不是「让ChatGPT写个算法」
首先,框架设定至关重要。
你可能以为这就是对着大模型说「帮我优化一下这个函数」,然后它吐出一段差不多的代码。
把Gemini当基因工程师使的进化式编码智能体
这是AlphaEvolve,谷歌DeepMind构建的进化式编码智能体。
它的工作方式,更接近于达尔文而不是程序员。
它把算法的源代码当作基因组(genome)。
LLM充当遗传算子(genetic operator),对代码进行变异——重写逻辑、注入新的控制流、对符号操作进行变异。
然后,它在一组博弈论基准游戏上评估每个「后代算法」的适应度——谁的可利用度(exploitability)降得最低,谁就活下来。
活下来的算法进入下一代,继续被变异、评估、筛选。
这不是提示工程。这是代码的自然选择。
目标:博弈论的两大基石算法家族
AlphaEvolve瞄准的目标,是多智能体强化学习(MARL)中两个最核心的算法家族:
反事实遗憾最小化(Counterfactual Regret Minimization, CFR) 和 策略空间响应预言(Policy Space Response Oracles, PSRO)。
如果你玩过德扑AI、或者听说过Libratus和Pluribus那些碾压人类扑克高手的AI——没错,它们的核心就是这两样东西。
它们的任务是在不完全信息博弈中找到纳什均衡——也就是让每个玩家都无法通过单方面改变策略来获得更好结果的那个「完美平衡点」。
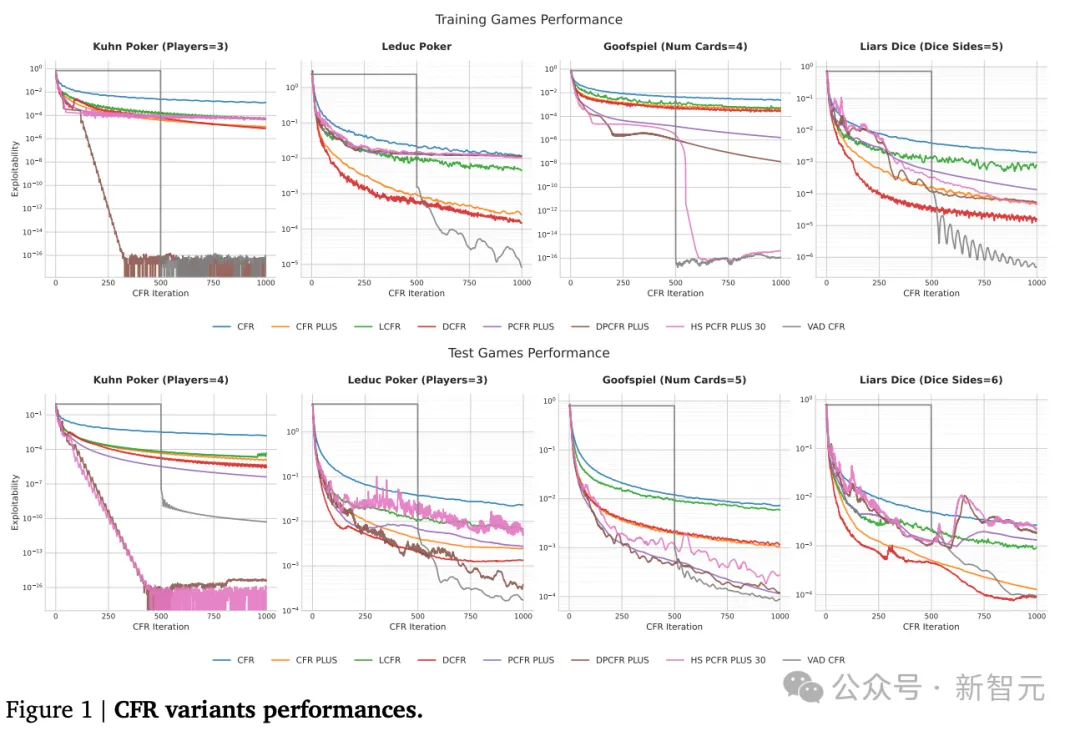
过去几十年,研究者们一直在手动调参、凭直觉设计这些算法的变体:CFR+、DCFR、PCFR+、LCFR……每一个变体都是某个聪明绝顶的博弈论研究者灵光一闪的产物。
但AlphaEvolve说:让我来。
为什么博弈论算法的设计这么难?