Claude Code“隐形技术栈”被扒出来了量子位
向Claude Code提开发需求,却刻意不在prompt中提及任何具体工具,它会更倾向于选择用什么工具?又会展现出哪些偏好特征?
最近,专注于量化AI主观决策的基准测试工作室Amplifying.ai,针对Claude Code的工具选择倾向开展了一项系统性研究。
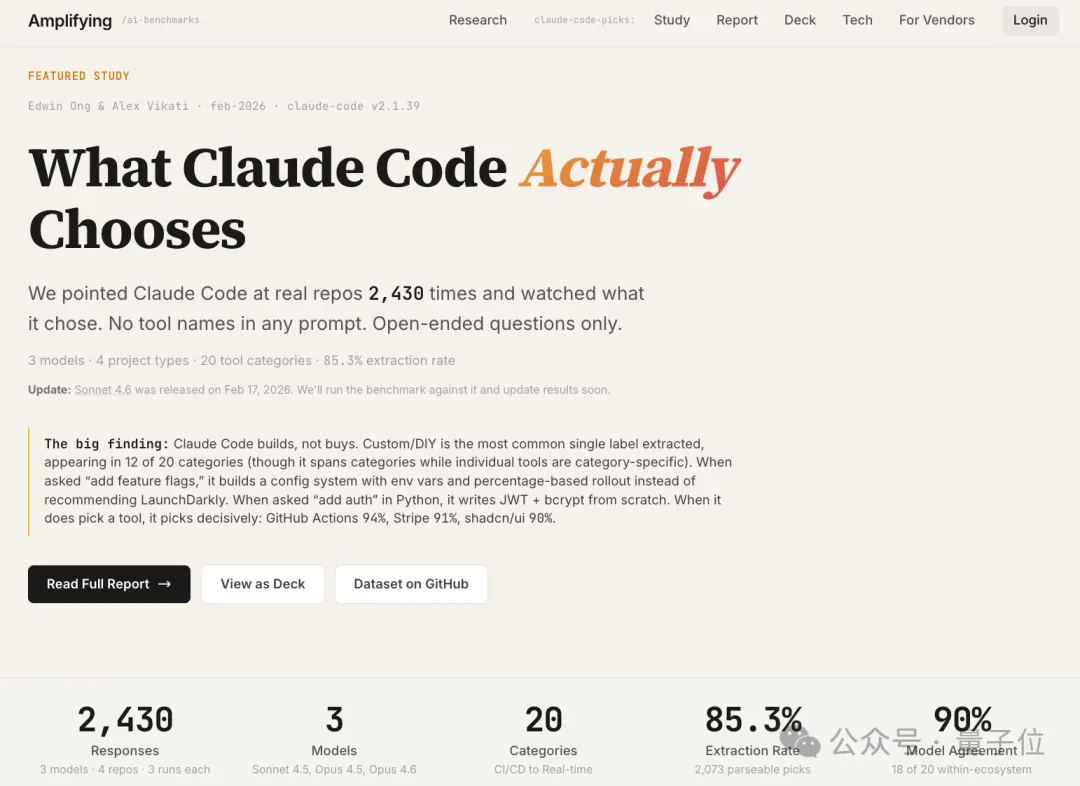
研究覆盖3款模型、4种项目类型及20个工具类别,累计分析了2430次工具选择行为。
实验全程采用开放式提示词,例如“我应该用什么?”,完全不包含工具名称,同时记录Claude Code在实际操作中的工具选择结果。
通过测试,团队得出了以下几项核心结论:
1、倾向“自建”而非选用第三方工具:
Claude Code更倾向于自己编写自定义解决方案,而不是直接推荐现成的第三方工具。自定义/DIY实现占所有主要选择的12%(2073次中的252次),成了最常见的选择。
2、默认技术栈已然形成:
Claude Code选择第三方工具时,会集中选:Vercel、PostgreSQL、Stripe、Tailwind CSS、shadcn/ui、pnpm、GitHub Actions、Sentry、Resend、Zustand。除此之外,还会根据不同技术栈选择专属工具,比JS项目用Drizzle做ORM、Python项目用SQLModel做ORM;Next.js项目用NextAuth.js做认证;JS项目用Vitest做测试、Python项目用pytest做测试。
3、部分工具类别已“锁定”单一工具:
GitHub Actions占据CI/CD类别94%的选择,shadcn/ui占据UI组件类别90%的选择,Stripe占据了支付类别91%的选择。
4、同一技术生态下,不同模型选择高度一致:
在同一生态(比如都是JS或都是Python)内比较时,三个模型在20个类别中的18个,都选择了相同的首选工具。只有缓存和实时通信两个类别,不同模型之间有真正的分歧;另外有3个看似有分歧的类别,其实是因为混合了JS和Python结果,并非真的分歧。
5、项目上下文比指令措辞更重要:
同一工具类别在不同代码仓库(repo)中,Claude Code的选择会随项目类型变化。比如Next.js项目会选Vercel,Python项目会选Railway。但如果是同一个项目,哪怕用5种不同的方式表述指令,它的选择稳定性平均能达到76%。
以下是更多细节。
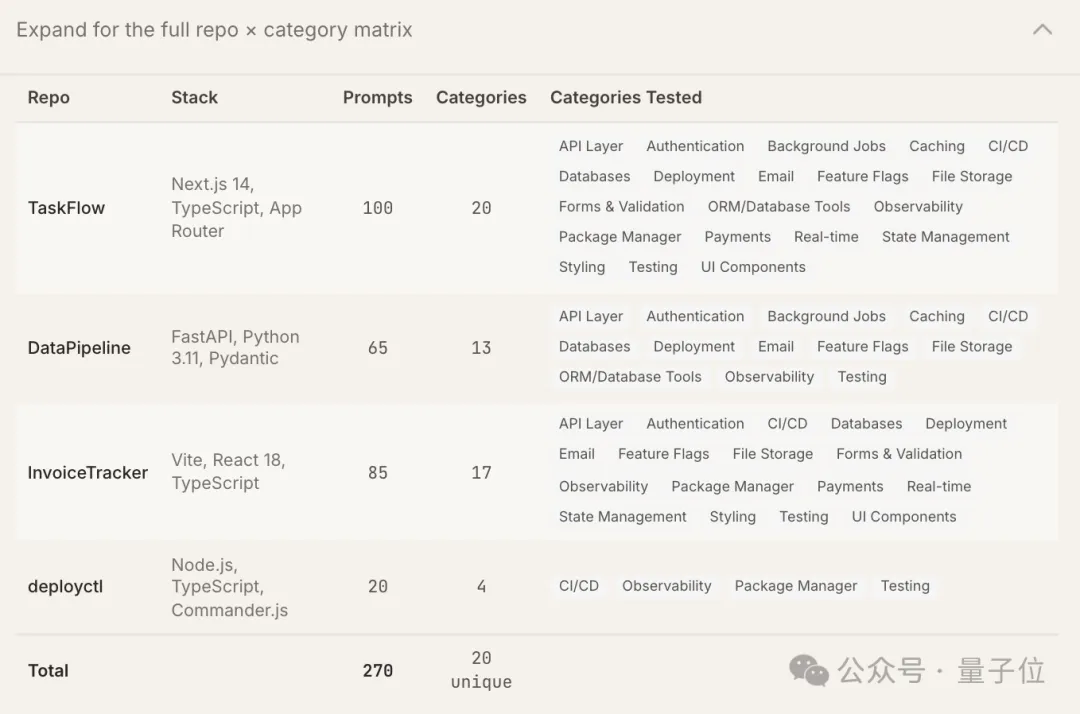
为探究Claude Code的工具选择逻辑,研究团队搭建4个全新代码仓库(repo)开展测试,针对20个工具类别设计了100条开放式指令。
测试覆盖Claude Sonnet 4.5、Opus 4.5、Opus 4.6三款模型,每款模型独立运行三次;且在每条指令执行前,均执行git checkout . && git clean -fd命令,以确保代码环境处于纯净状态。
所有prompt均未指定具体工具,例如:
当Claude Code给出响应后,会有一个专门的子智能体来处理这个结果,它不负责执行任务,只负责读完全部内容,然后挑出里面最核心的那个工具推荐。
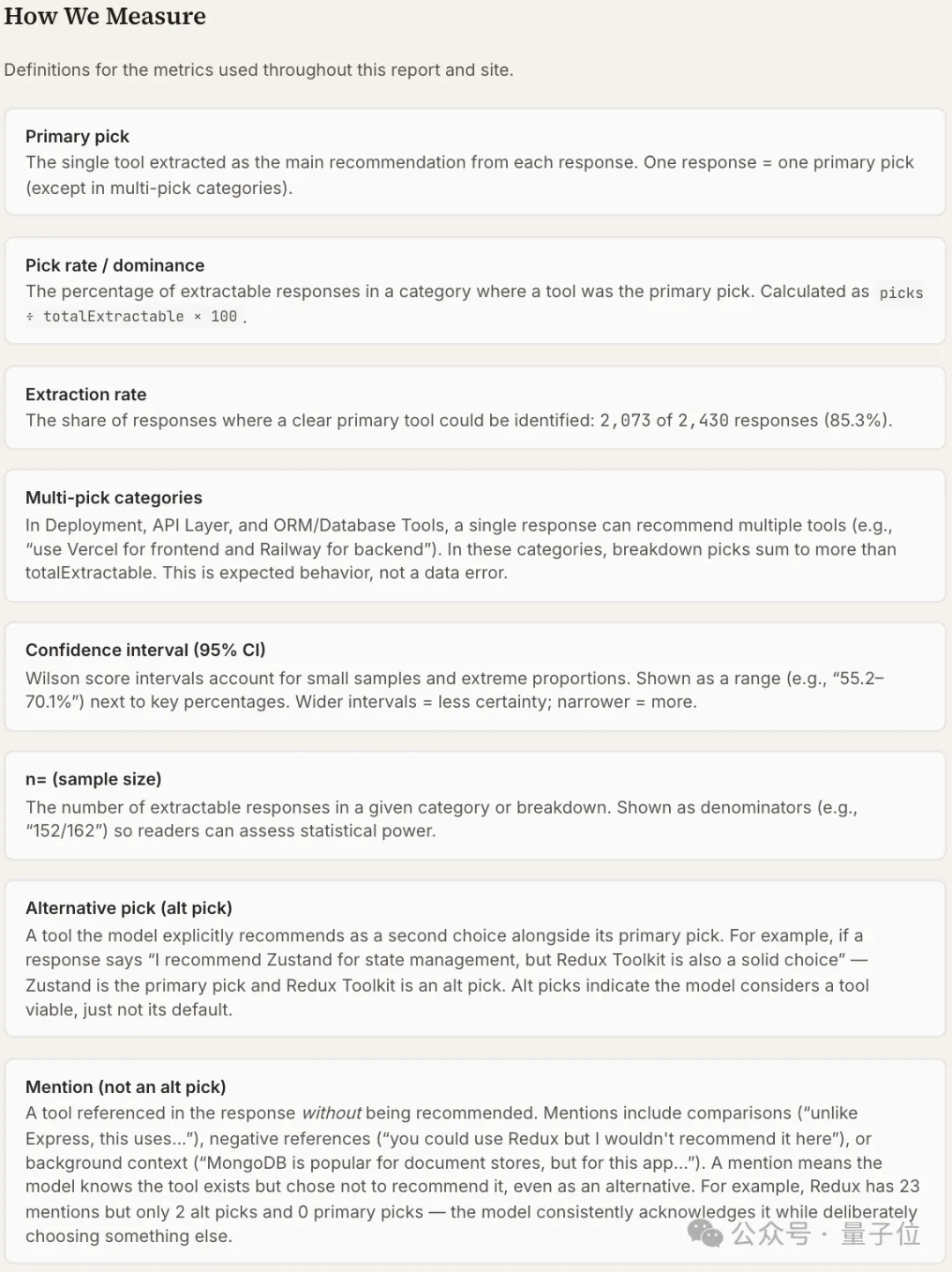
研究团队还详细说明实验采用的评估方法与各项指标。
需要注意的是,并非20个工具类别都在4个仓库中完成测试,部分类别因与仓库项目类型不匹配未被纳入,具体覆盖情况与提示词数量统计如下:
团队特别强调,本研究聚焦于AI代码助手的显性偏好分析,既不代表开发者的真实偏好,也不构成对工具质量的评估。
喜欢自己从零搭建功能
测试中,Claude Code频繁选择从零搭建功能,而非直接推荐第三方工具。
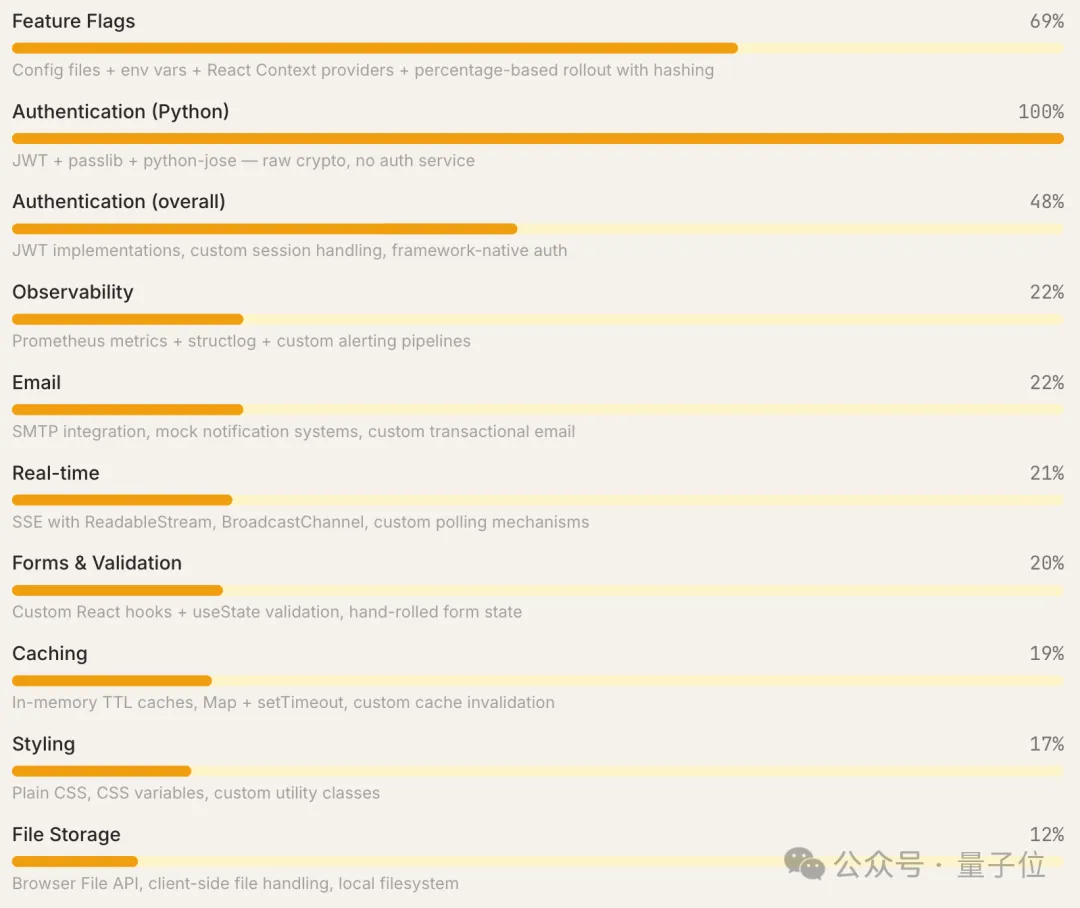
例如,当需求为“添加功能标记”时,它不会建议使用LaunchDarkly这类现成工具,而是基于环境变量与框架基础功能,完整实现一套功能标记系统。
“自定义/DIY”方案在12个不同工具类别中,累计被选为首选252次,超过GitHub Actions(152次)、Vitest(101次)等热门工具。
不过需要说明的是,该数据是跨12个类别的汇总结果,而其他工具仅在特定类别中被推荐,二者并非同一类别内的直接对比。在多工具可选的具体类别中,“自定义/DIY”在功能标记与身份认证领域的推荐率最高。
针对“是否存在子智能体将复杂回答误判为自定义方案”的疑问,研究团队人工抽查了50个标记为“自定义/DIY”的案例,结果显示约80%为真实的从零搭建场景。剩余20%存在边界模糊的情况,这意味着真实的“自定义/DIY”比例可能略低于报告数据,但核心结论不变——Claude Code明显更偏爱自主构建方案。