字节跳动新算法,直接把1/3的算力砍掉了华尔街日报
过去这两年,大语言模型走得实在太快,尤其在那些需要复杂逻辑推理的任务上,能力已经高到了一个我们以前不太敢想的水平。
我到现在还记得 ChatGPT-3.5 那个时代。那时候的 AI 顶多帮你做点简单数学题,写几行基础代码,稍微绕一点的问题就卡壳。没有联网搜索,更别提什么深度思考,它能回答你每一个问题,靠的全是预训练阶段塞进脑子里的那些“存货”,用完了就没了。
但现在不一样了。模型开始学会自己拆问题,一步一步推,生成超长的思维链,甚至在数学竞赛、编程挑战这种硬核任务里,做出了让人类都瞪大眼睛的成绩。
不过,Scaling Law这东西,带来了“大力出奇迹”的同时,也悄悄埋了一个问题:思考过剩。
你回想一下那两个经典的AI笑话,就特别能说明问题:
一个是美国人拿来测 AI 智商的:“Strawberry”这个单词里有几个字母“r”?这问题学前班小孩都能答出来。但一年前,ChatGPT 答错过,DeepSeek 答错过,豆包也答错过。像 R1 这种推理模型,甚至会翻来覆去想十分钟,自己跟自己辩论,最后慎重其事地告诉你:两个。
等 AI 终于把这个坑填平了,中国人又出了个新题:要去 50 米外洗车,应该开车去还是走路去?
AI 又乱了。有的秒回“走路去”,有的把时间、路程、成本全算了一遍,最后还是得出结论:“走路去”。
而且洗车那个例子也提醒我们,想得久,不代表想得对,有时候反而是因为想太多,自己把自己绕进去了。
所以大家开始问:一个能力已经溢出的模型,真的需要想那么久吗?它自己知不知道,什么时候该停下来?
字节跳动和北航最近发了篇论文,专门回答这个问题。
01 诊断环节:问题出在哪里?
对于AI企业来说,token就是最重要的资源。减少大量token的无用消耗,无异于大大节约了推理成本。
对 AI 企业而言,token 即核心资源。减少大量无谓的 token 消耗,无异于大幅节约推理成本。
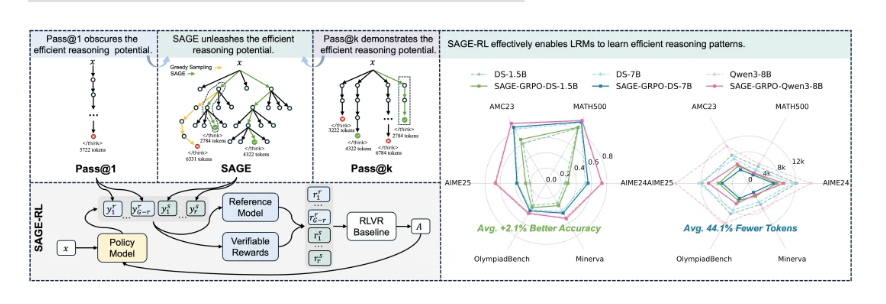
研究团队在观察模型运行过程后发现,问题的关键出在采样策略。在现有采样范式下,模型的高效推理能力难以充分发挥。
一般来说,人们评估模型能力经常采用的是一种名为“Pass@1”的策略,也就是只取模型生成的一次结果,看它是否能够正确通过测试用例。
但在这种采样模式下,我们可以从DeepSeek等模型的显式思维链中明确看到:在得出正确答案后,模型通常不会立刻停止并告诉用户答案,而是会继续生成大量无效的验证或重复步骤。
我们做个测试,让AI计算20260226的平方,并强调直接输出结果,DeepSeek思考了38秒才给出了正确答案:
这还只是显式思维链中截取的一部分。事实上,在这38秒的思考过程中,模型在得出正确答案后还经过了检查位数、检查进位错误、检查末位数字等多个毫无用处的验证环节。
事实上,这不是DeepSeek独有的情况。根据现有的研究,人们已经注意到了这个反直觉的现象:
思维链长度的延伸与答案的正确性并非正相关关系,有时思维链更短反而准确率更高。
例如,在AIME 2025基准测试中,DeepSeek-R1的回复长度足足是Claude 3.7 Sonnet的5倍,但准确率却相差无几。
而对于同一个模型在同一个问题上分别生成正确和错误的答案,有72%的概率是更长的回复出错。
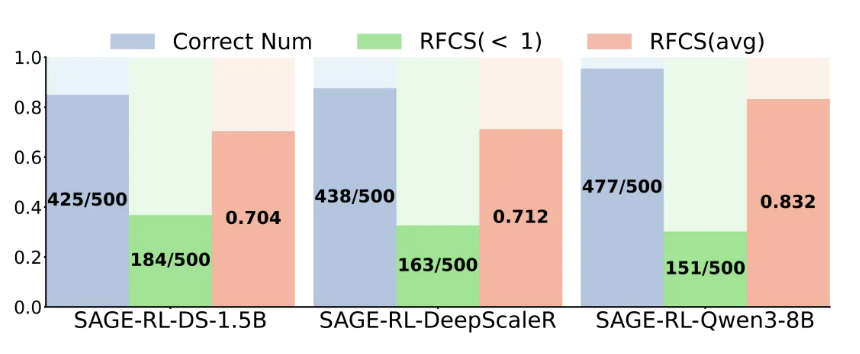
为了系统性地量化模型这种“过度思考”的现象,字节和北航的研究团队定义了一个新指标:
首次正确步骤比率(RFCS)=正确答案首次出现的步骤索引/总推理步骤数。
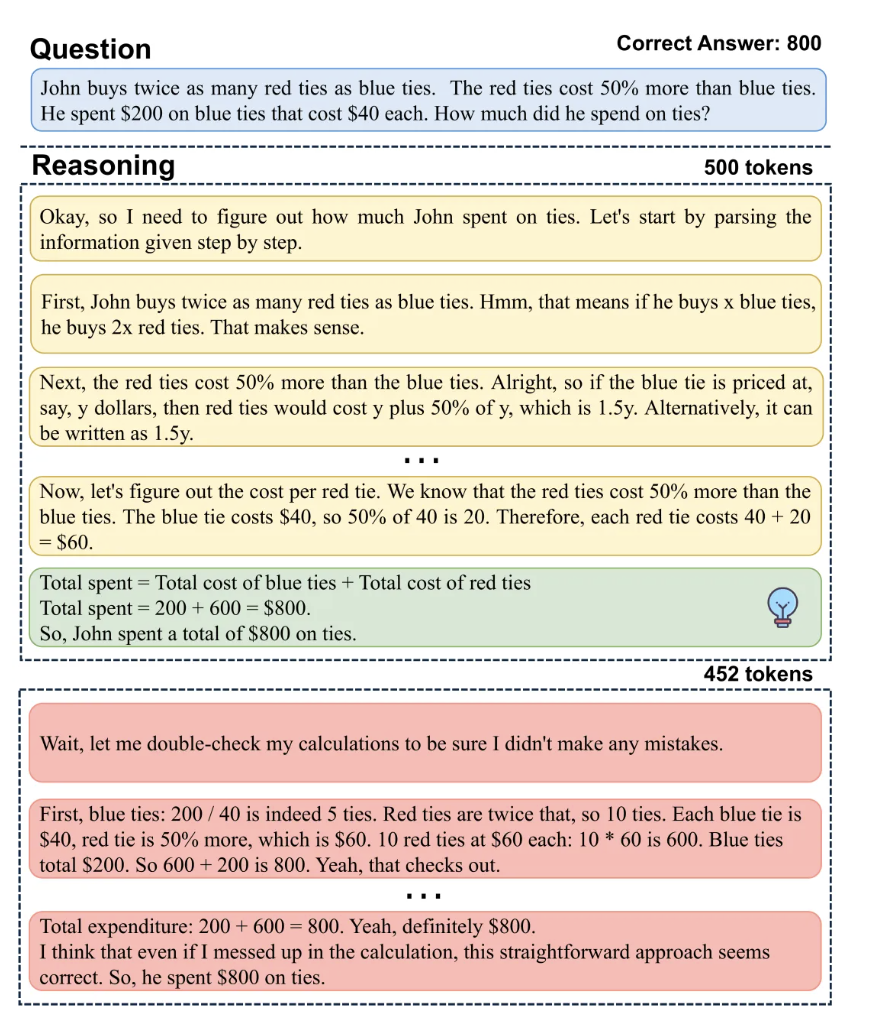
例如,DeepSeek的1.5B轻量级模型在某些问题上只需花费500个token即可得出正确答案,但受限于现有的采样策略,它要继续生成452个冗余token才能结束思考。
看起来,在现有的采样范式下,模型并不知道自己应该何时停止。
02 惊人发现:模型心里有数!
然而,研究团队却发现了一个反直觉的事实:
若是扩大采样空间至“Pass@K”,也就是让模型生成K个思维链,看其中是否有一个生成的答案能够正确通过测试用例,结果就截然不同。
为此,论文定义了两个指标和一个符号:
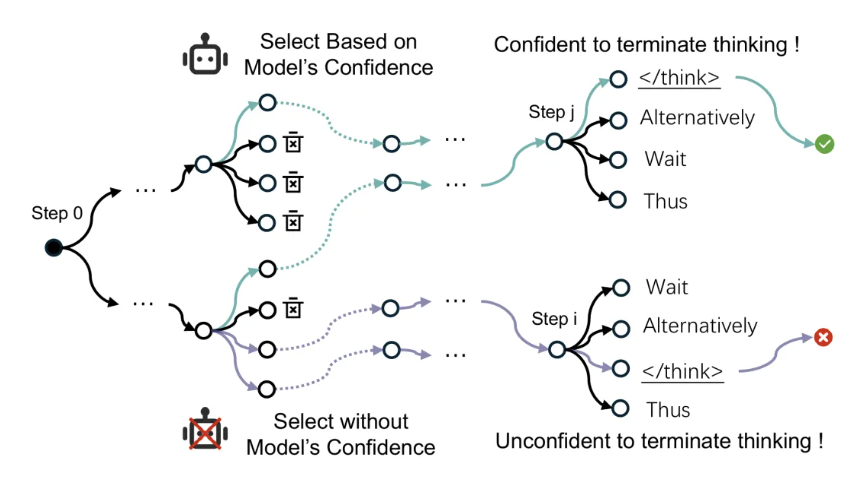
局部置信度(Next-token Probability):模型生成下一个词的概率;
路径置信度(Cumulative Log-Probability,即Φ):模型从头到尾生成这条思维链的平均累计概率;
:思维链的结束标识。
如果模型只根据局部置信度来决定是否该在下一个词输出“”来停止思考,它总是没什么信心,因为每次输出下一个词的概率都比输出结束标识的概率要高。
因此,思维链的长度就这样不断的延伸下去。
但若是根据路径置信度来判断是否该停止思考,则情况完全相反: