美一周挖走4名中国顶尖人才淡墨绘江南
普通程序员大多月薪两万左右,还天天被脱发、加班折磨,可顶尖的AI人才完全是另一个世界,Meta短短一周就从OpenAI挖走四位华裔精英,开出的总薪酬高达一亿美元。
美国一面搞技术封锁,一面疯狂收割中国培养的精英,这种前后矛盾的做法,这种极度矛盾的行径正撕开其内心深处深不见底的技术焦虑。
一亿美元到底是什么概念?
按这个体量,在北京核心区域买下一整栋像样的商业楼都不算离谱,,放到个人收入上,更是绝大多数高级技术人员一辈子都碰不到的数字。
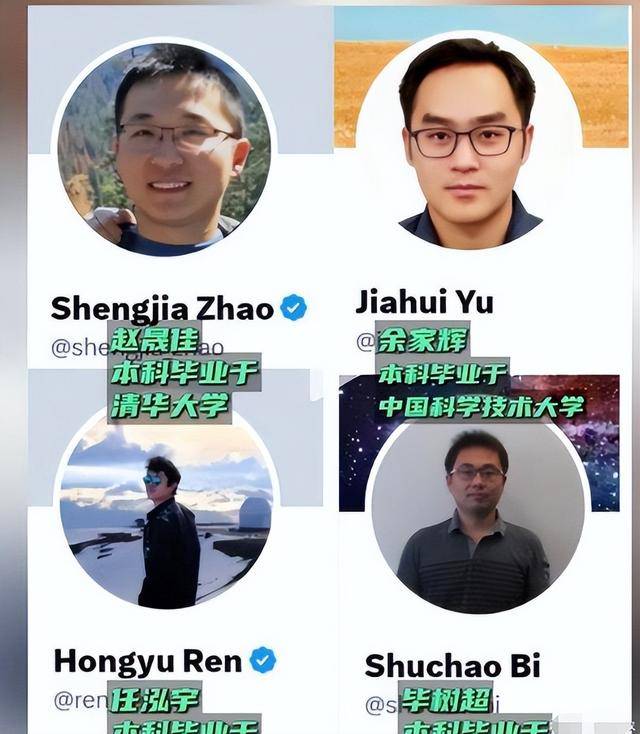
可Meta出手就是这种级别,而且动作很猛:据称在短短一周内,把这笔天价待遇连着砸向四位华人专家,赵晟佳、余家辉、毕树超、任泓宇。
他们被看重的点不是“会写代码”这么简单,而是能把大模型从底层机制、训练路径、到产品化落地一条链路打通的那类稀缺型人才。
赵晟佳从 ChatGPT和 GPT‑4 刚起步就加入研发,一路跟着做到成熟落地,摸透了模型升级里最容易卡壳的环节、风险最高的参数设置,也清楚常见问题怎么避开,有很强的实战把控。
余家辉长期做多模态方向,核心能力是让模型在面对图像、文本、音频等混杂信息时仍能保持稳定判断与识别效果。
毕树超同时懂互联网产品和AI工程,擅长把实验室里的模型更快推到真实业务里去,让技术更快产生商业结果,任泓宇主攻后训练与对齐等工作,负责把“能跑的模型”进一步打磨成“好用、可控、能卖”的系统。
把这四块能力拼起来,等于直接凑齐一支成熟大模型团队的关键部件,Meta的目的也很明确:不仅是招到人,还要得到他们在OpenAI时期沉淀下来的经验和手感。
那些经历过反复失败、调参、推翻重做后形成的判断力,很多并不会写进论文或文档,却往往最值钱,对Meta来说,这类“带不走但记得住”的经验,才是它愿意烧钱的原因。
一旦这些经验被带进Meta体系,Llama后续的研发和产品节奏就可能少走很多弯路,甚至直接把试错时间压缩一大截。
这些不可言说的技术秘辛,足以让Meta的Llama系列在全球博弈中强行缩短至少两年的摸索周期。
Meta之所以在这个时间点用重金挖人,被外界看成“很野”,根本原因是它感到了被淘汰的压力。
现在AI竞争已经进入硬碰硬阶段:OpenAI的GPT体系仍然领先;中国这边像DeepSeek等模型也迅速追上来,按一些中美顶级模型的实测对比,差距已经被压到约0.3%这种几乎可以忽略的水平。
领先不再稳固,掉队的代价却变得更大,在这种环境下,Meta过去靠开源Llama攒下的口碑,开始顶不住新一轮核心能力对抗。
外界对Llama 4的反馈没有达到预期,尤其在多模态交互、实时语音、复杂推理这些关键战场,表现被对手压了一头。
更要命的是行业节奏变了:以前可能18个月做一代更新,现在很多能力半年就要拉开一次差距,慢一步就会被甩开,甚至直接失去存在感。
扎克伯格也清楚,算力和机房这些东西,只要肯花钱、肯扩建,总能追一段;但真正决定模型上限的,是懂架构、训练、对齐、产品化全流程的顶级人才。