47天30次更新,中国AI最强主场在哪?量子位
2026年的AI开局,没有谁在观望。
硅谷在卷。中国在卷。节奏几乎同步,不分伯仲。
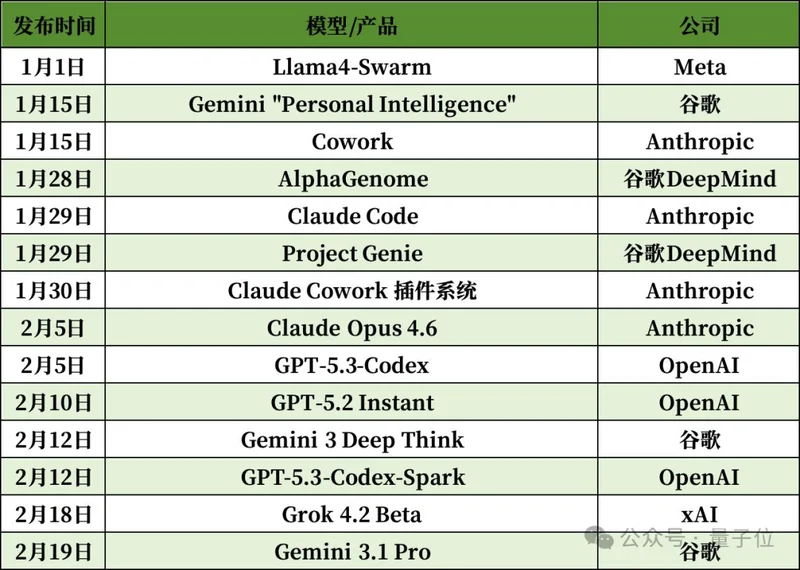
看向硅谷,从1月1日Meta的Llama4 Swarm,到Google最新发布的Gemini 3.1 Pro,高频的技术脉冲平均每2-3天就引发一次行业热烈讨论。
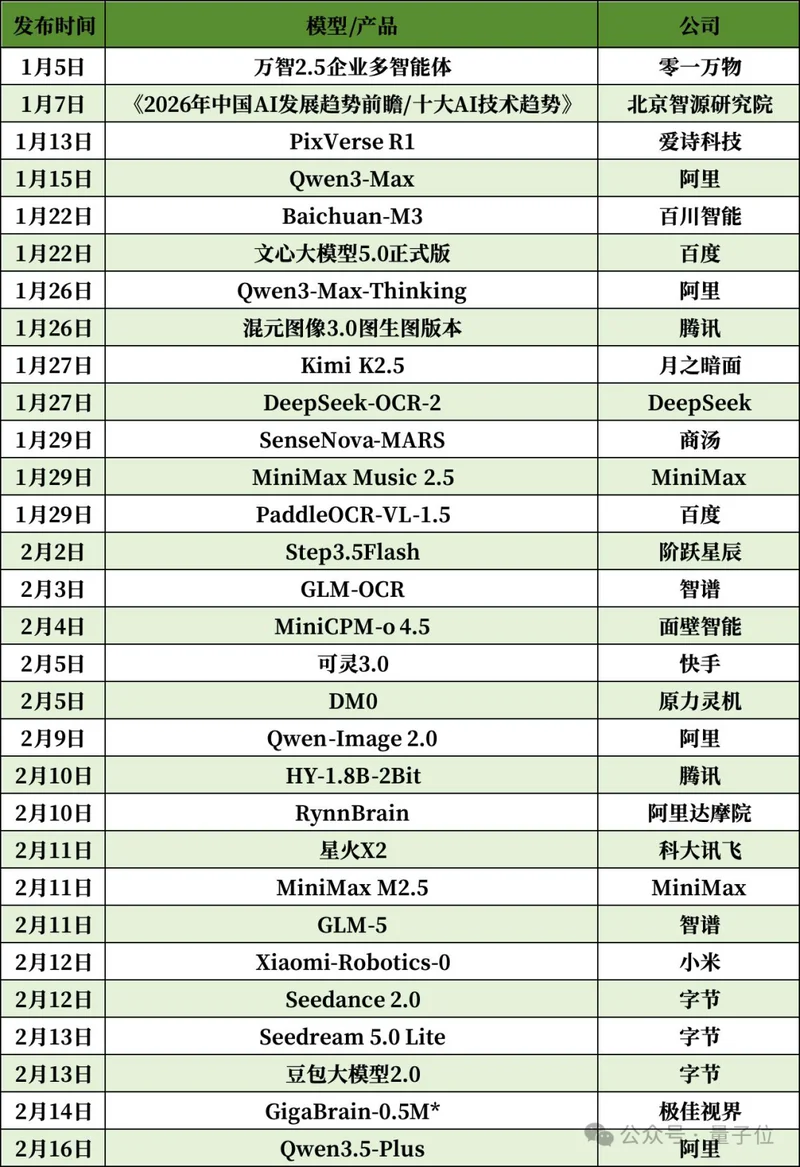
在中国这头,据量子位不完全统计,仅1月1日至除夕,国内公开宣发、具有行业影响力的AI模型技术迭代已超过30起。47天30次重磅发布,意味着平均每1.5天就有一个新模型现世。
在多个全球权威榜单上,中美阵营各有胜负;在开发者社区与应用市场,中国模型也开始获得越来越多海外用户的真实投票。
这已经不是单个企业的高光时刻,而是一场跨越太平洋、几乎同频共振的技术竞速。
大模型竞争已告别单向追随,进入了全赛道、全维度的双极竞速时代。
问题随之浮现:在未来加速到来的中美AI长期竞争中,中国阵营最核心的支点在哪里?
答案并不抽象。
当我们把这47天的发布主体按地域拉通,那个坐标越来越清晰。
2026开年模型混战,是谁卷得最狠?大家都在说,今年春节,国内AI大模型不打烊。
这种高频脉冲式的更新,密度之大、烈度之高,让整个行业产生了一种“进入加速挡”的直观感受。
但其实卷起来的不只是中国。
从元旦钟声敲响的那一刻,这个节奏就已经在太平洋两岸同步埋下伏笔。
1月:Meta率先点燃战火,国内高频脉冲响应1月的战局,由沉寂许久的Meta率先鸣枪。
1月1日元旦当天,Meta发布Llama系列最新家族伙伴Llama4-Swarm。
它专为Multi-Agent的复杂协同与自主调度而生,旨在让多个AI像一支训练有素的队伍一样,自主组织、分工协作,解决更宏大的任务。
“Agent协作”的火热赛道就此拉开帷幕。
几天后,中国阵营接棒。
1月5日,零一万物打响头炮,发布面向企业场景的万智2.5多智能体;两天后,北京智源研究院发布行业趋势报告,为全年技术演进定下基调。
但这仅仅是前哨战。进入1月中旬后,全球发布节奏陡然提速,呈现出一种“中国出招、硅谷响应”的奇妙对位。
1月15日,中国市场率先抢跑——阿里发布Qwen3-Max,大模型推理能力进一步升级。
同日,硅谷也开始升温,出现2026年第一次模型对撞。
Google推出Gemini的Personal Intelligence,Anthropic则发布了风靡一时的Cowork,二者分别强化个人助手与协作能力。
全球AI共同的技术路线在此时已经露出端倪:
长推理、协作能力、Agent系统,成为共同关键词。
1月22日,百川智能和百度双发模型;接下来几天,阿里、腾讯、月之暗面、DeepSeek纷纷出招,在一周之内连续释放结构化能力升级。
硅谷阵营同样没有停顿。
1月28日至29日,谷歌DeepMind连续放出AlphaGenome与Project Genie两项重磅,试图在生物科学与游戏生成领域筑起护城河。
Anthropic也祭出了Claude Code,将AI编程的战火烧到了每一个开发者的桌面。
2月:前所未有,全球AI模型进入密集火力期进入2月,节奏不仅没有因中国农历新年的临近而放缓,反而变得更加急促。
就拿热闹的2月5日来说吧!
这一天,中西方AI大模型鞭炮齐鸣:这一边,快手携可灵3.0视频模型杀入战场,原力灵机发布DM0具身原生大模型;那一边,Anthropic发布Claude Opus 4.6,OpenAI推出GPT-5.3-Codex,编程能力与企业级推理再度升级。
次日,面壁智能推出MiniCPM-o 4.5,强化端侧部署能力。
到了2月10日前后,AI大模型的发布节奏达到第一轮高峰,让人应接不暇。
2月10日,OpenAI发布GPT-5.2 Instant。
2月11日,智谱GLM-5登场。这款在硅谷匿名测试期间便引发轰动的模型,被证实正是海淀原生的“全球大模型第一股”作品。
因为能力强劲,GLM-5被视为国内阵营在推理能力上的一次关键迭代。
同一天,MiniMax更新M2.5版本,继续强化音乐与生成能力的商业化落地路径;科大讯飞则发布星火X2,主打多场景综合能力升级。
而2月12日是进入2月以来的又一个超级发布日,全球AI版图迎来了开年以来的最高潮——
这一天,Google发布Gemini 3 Deep Think,OpenAI上线GPT-5.3-Codex-Spark。
同日,字节发布了视频生成模型Seedance 2.0,小米的具身智能模型Xiaomi-Robotics-0也闪亮登场。
中美四大模型厂商在24小时内密集亮剑,分别在视频生成、深度推理与具身智能三大黄金赛道上展开了跨洋对决。
11日、12日连续两天高密度发布,让行业明显感受到节奏变化。
但更新并未停在这里。
2月13日,字节再次加码,推出豆包大模型2.0。
与Seedance面向创作不同,豆包2.0强调对话与生产力能力升级,面向更广泛用户场景。这种连续发布,体现了AI大模型产品线级别的整体推进。
至此,短短三天时间内,中国阵营完成了一轮覆盖推理、视频、具身、对话产品的全维度更新。
最后,2月16日除夕当天,在中国的万家灯火中,阿里以Qwen3.5-Plus放出了农历蛇年最后一枪,为这场为期一个半月的密集发布潮,画上了极具竞争张力的暂止符。
卷王半壁江山,在海淀开启“集群式突破”在这场跨越太平洋的开年竞速中,硅谷和中国双方已经不再是简单的“追随与被追随”关系,而是在全球多个权威排行榜上展开了激烈的拉锯战。
当这种“各有胜负”的竞争进入深水区,一个问题变得愈发清晰:
在未来的全球AI博弈中,中国阵营最核心、最稳固的底牌究竟压在哪里?
当我们把这47天内密集发布的30余起技术迭代按地域拉通一看,答案不再是模糊的“中国”,而是一个精准的地理坐标。
更准确点说,是北京海淀。
字节、百度、智谱、月之暗面、面壁智能、快手、小米、银河通用……过去40几天里,这些让全球开发者“催上线”的名字,几乎全部集中在海淀区的版图之内。
不管是发布数量、技术覆盖面,还是行业话题度,海淀对比其他地区拉开了清晰的身位。
而这种领先,在今年春节档两个最出圈的案例中,得到了最硬核的检验。
先看春节档全球好评的当红炸子鸡模型。
2月12日发布的视频生成模型Seedance 2.0,其刷屏之势,比去年横空出世的DeepSeek-R1有过之而无不及。
Seedance 2.0支持图像、视频、音频、文本四种模态的混合输入。在技术表现上,它有效改善了AI视频中常见的画面变形、可用率低以及音画不同步等长期痛点,分镜叙事与运镜控制已初步具备“导演级”水准 。