西湖大学出品:学术插图新神器量子位
你是否也经历过这样的绝望:
论文截稿在即,面对大段的文字你抓耳挠腮,PPT画框画到手抽筋;
尝试用Nano banana生个图,颜值拉满但逻辑全错,甚至还自带“克苏鲁”风格的模糊字符;
^好不容易调好了Prompt,结果想改一个小图标,却发现AI给你的只是一张无从下手的“死图”。
这种“审美与逻辑不可兼得、生成与编辑彻底断层”的痛点,终于要被终结了。
现在,你可以把大段的文字材料直接塞给AutoFigure,西湖大学团队推出的全新智能体绘图框架。
它能够一键读懂上万字的论文、书籍、博客,自动化地吐出高质量的学术插图为你所用。
更重磅的是,其优化版本AutoFigure-Edit实现了从“像素”到“矢量”的跨越:生成的插图不再是死板的图片png,而是细节可编辑的SVG文件(现在你可以在PPT里直接编辑)。
目前,该工作已入选ICLR 2026。代码、数据集、Web交互界面全部开源,并同步上线了可一键使用的在线网站。
背景:为什么AI以前画不好科学插图?
在学术绘图界,一直存在两个极端:
1. End-to-end派(如GPT-Image):审美在线,但逻辑经常“蹦迪”,文字更是重灾区,充满了莫名其妙的幻觉字符。
2. Text-to-code派(如TikZ/SVG生成):逻辑倒是严密,但视觉效果往往丑得像上个世纪的教科书,缺乏现代论文的高级感。
AutoFigure提出了“推理式渲染”(Reasoned Rendering)范式:将“脑子(逻辑布局)”和“手(美化渲染)”彻底分开。
技术方案:模拟大牛设计师的“三步走”策略
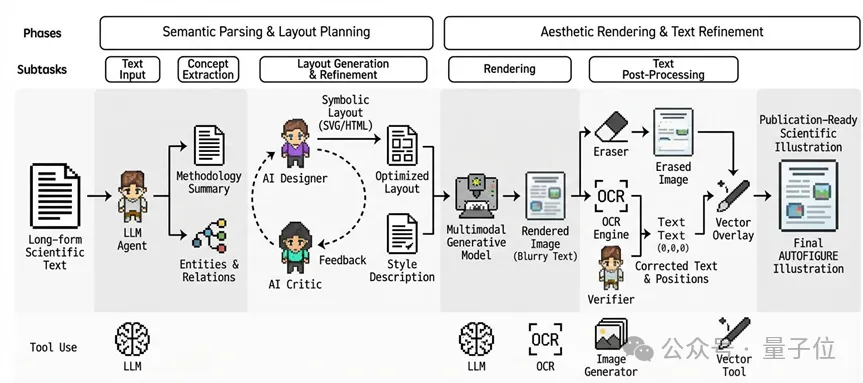
AutoFigure的核心是一个分工明确的多智能体协作系统。
△ AutoFigure架构图(由AutoFigure生成,未经修改)
第一步:Conceptual Grounding(构建逻辑骨架)
AI读入你长达万词的文字材料,自动提取实体和关系,生成一个粗糙但结构正确的布局(SVG/HTML代码)
第二步:Critique-and-Refine(Agent闭环迭代)
模拟人类设计师与甲方的反复拉锯,对图片布局进行反复修改:
AI Designer负责根据反馈修改布局。
AI Critic则负责挑毛病(例如“这里箭头重叠了”、“布局重心不稳”),直到得到满意的绘图质量。
第三步:Aesthetic Rendering & “Erase-and-Correct”
在最终美化阶段,AutoFigure首先将布局渲染为一张精美的图片。随后,为了解决现在AIGC生图文字变形的问题,保证图片中文字的正确性,AutoFigure引入了专门的“擦除-修正”策略:用OCR识别模糊字符,把它们“抠掉”,再重新覆盖上清晰的矢量文本。
AutoFigure-Edit:把AI生成图装进PPT
△ AutoFigure-Edit流程图(由AutoFigure-Edit生成)
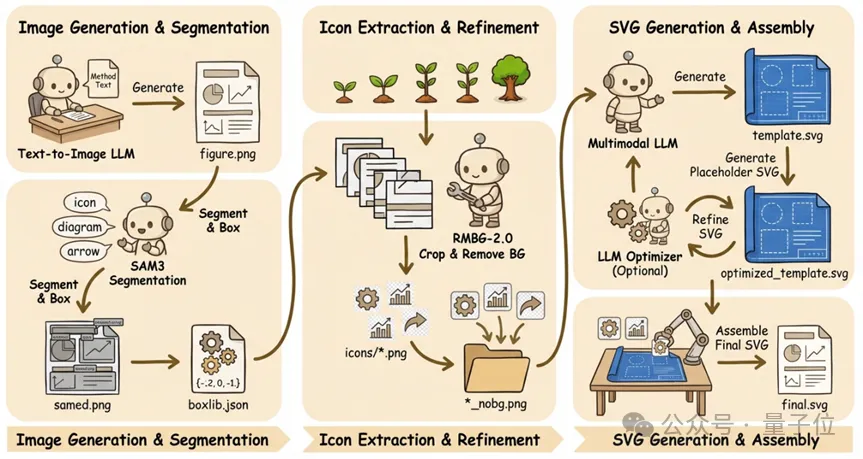
在最新版本AutoFigure-Edit中,西湖大学团队更进一步,引入了SAM3自动抠图技术,包括:
利用Meta最新的SAM3技术识别图中的Icon。
配合RMBG-2.0自动去除背景。
矢量重组:将这些干净的图标重新塞进生成的SVG模板中。
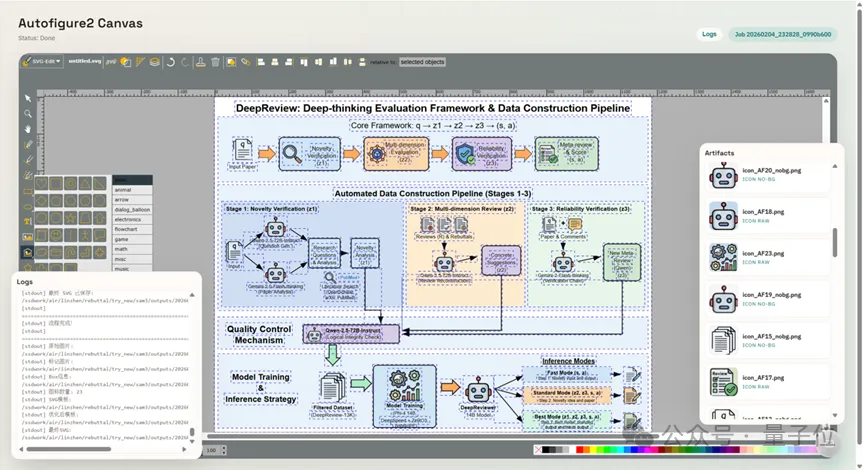
最终,你得到的是一个可以在浏览器内置编辑器里直接拖拽、改字、换色的动态画布,能够按照你的想法对图片细节进行更改。
△ 基于AutoFigure-Edit的在线画布
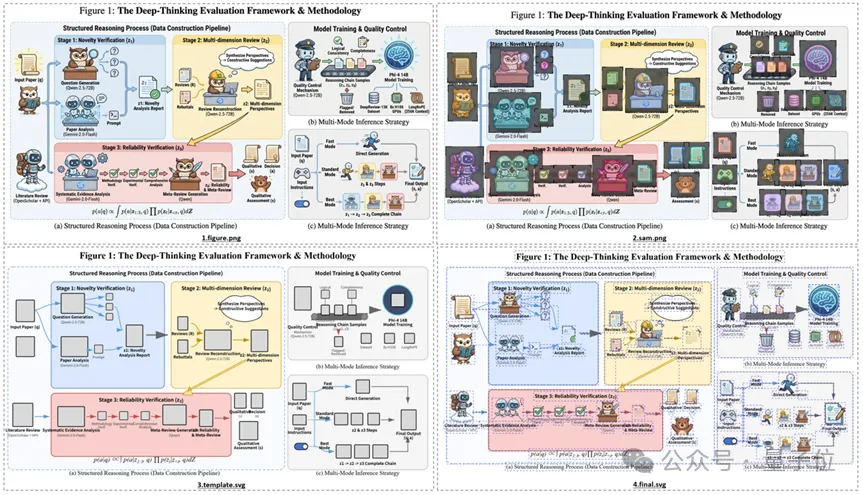
△ AutoFigure-Edit渲染过程示例图
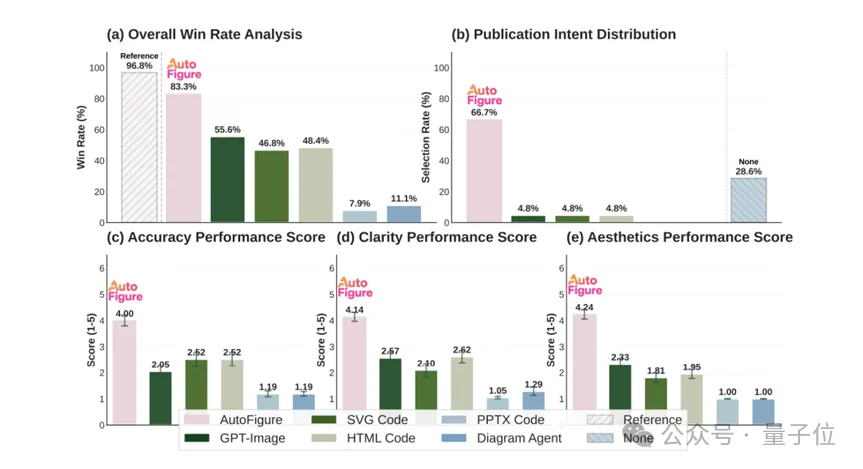
人类实验结果:66.7%的专家觉得它达到了Camera-ready标准!
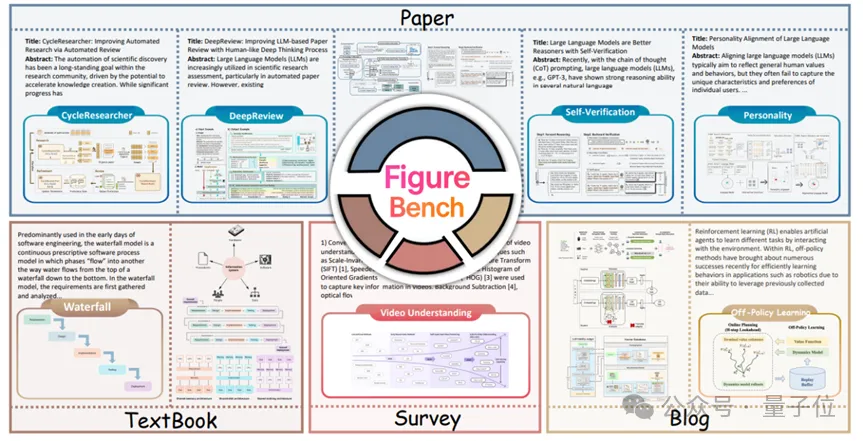
为了验证AutoFigure的效果,团队构建了全球首个大规模科学插图基准——FigureBench。
规模宏大:涵盖3,300高质量文本-图片对,跨越论文、综述、技术博客、教科书等四种科学文本。
△ FigureBench数据集介绍
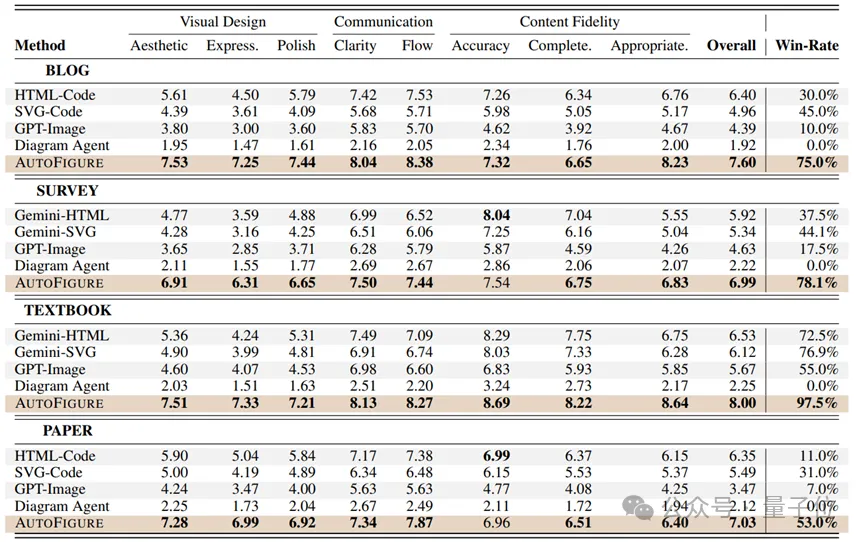
降维打击:在逻辑清晰度和准确度上,AutoFigure的优势极大,在教科书类任务中胜率甚至高达97.5%。
△ 在FigureBench上的实验结果
更具说服力的是人类专家盲测:10位论文一作对生成的图片进行评审,结果显示66.7%的专家认为AutoFigure生成的图已经达到了Camera-ready(出版级)标准。
△ 人类专家评价结果