Claude最新Sonnet:性价比王炸量子位
春节才是真正的大模型战场,全世界参与的那种。
大年初二,Anthropic 史上最强 Sonnet——Claude Sonnet 4.6 发布。
不难看出,计算机操作是这次更新的主打卖点。
Anthropic 表示,对填写复杂 Excel、网页清单等任务,Sonnet 4.6 已经接近人类水平。
其他方面也是全方位升级:编码、长上下文推理、Agent 规划、知识型工作、设计……Beta 阶段还支持 1M 上下文。
定价依然跟 Sonnet 4.5 一样,免费用户也能用。
性价比简直高到离谱。
创业者 Alex Finn 体验后表示「难以置信」:
在大多数 Agent 任务上,Sonnet 4.6 的表现跟 Opus 系列差不多好,速度还更快,价格只要 1/5。
还不只一个人这么说。
Anthropic 表示,内测用户对 Sonnet 4.6 的喜爱程度,已经超过了超大杯 Opus 4.5。
史上最强 Sonnet
计算机操作能力,可以说是这次 Sonnet 4.6 最亮眼的部分了,Anthropic 也在这部分花了不少笔墨。
虽然跟最熟练的人类工作者比还有差距,但进步速度真的恐怖。
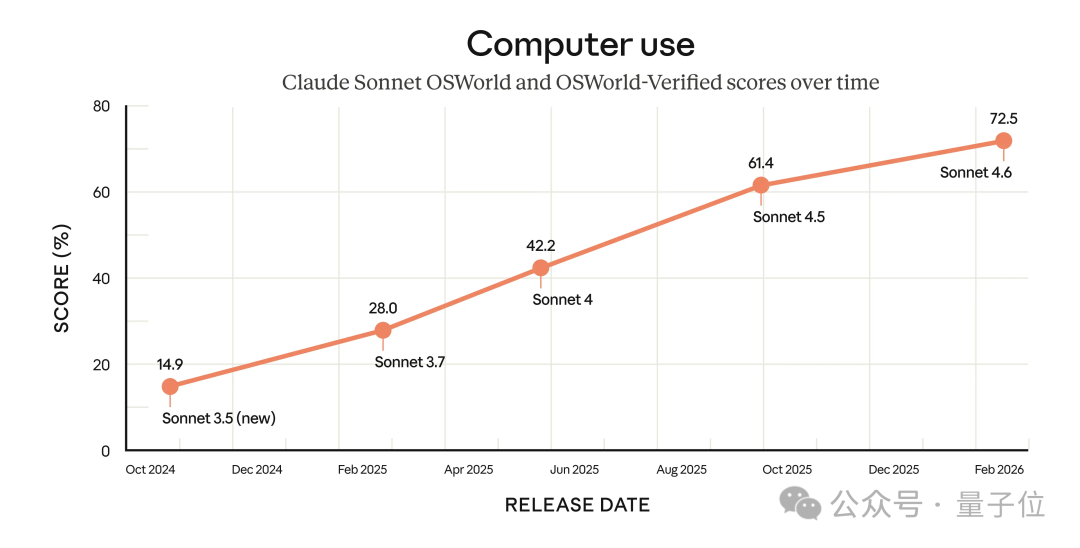
看下面这张图 ——
四个月一次的高频率更新下,性能曲线依然保持着不错的上升势头。
当然,计算机操作能力提升,也意味着如果模型被 prompt injection,风险会更大。
Anthropic 也想到了这一点,专门给用户们塞了颗定心丸:
Sonnet 4.6 的安全等级相比前代 Sonnet 4.5 有显著改进,表现跟 Opus 4.6 差不多。
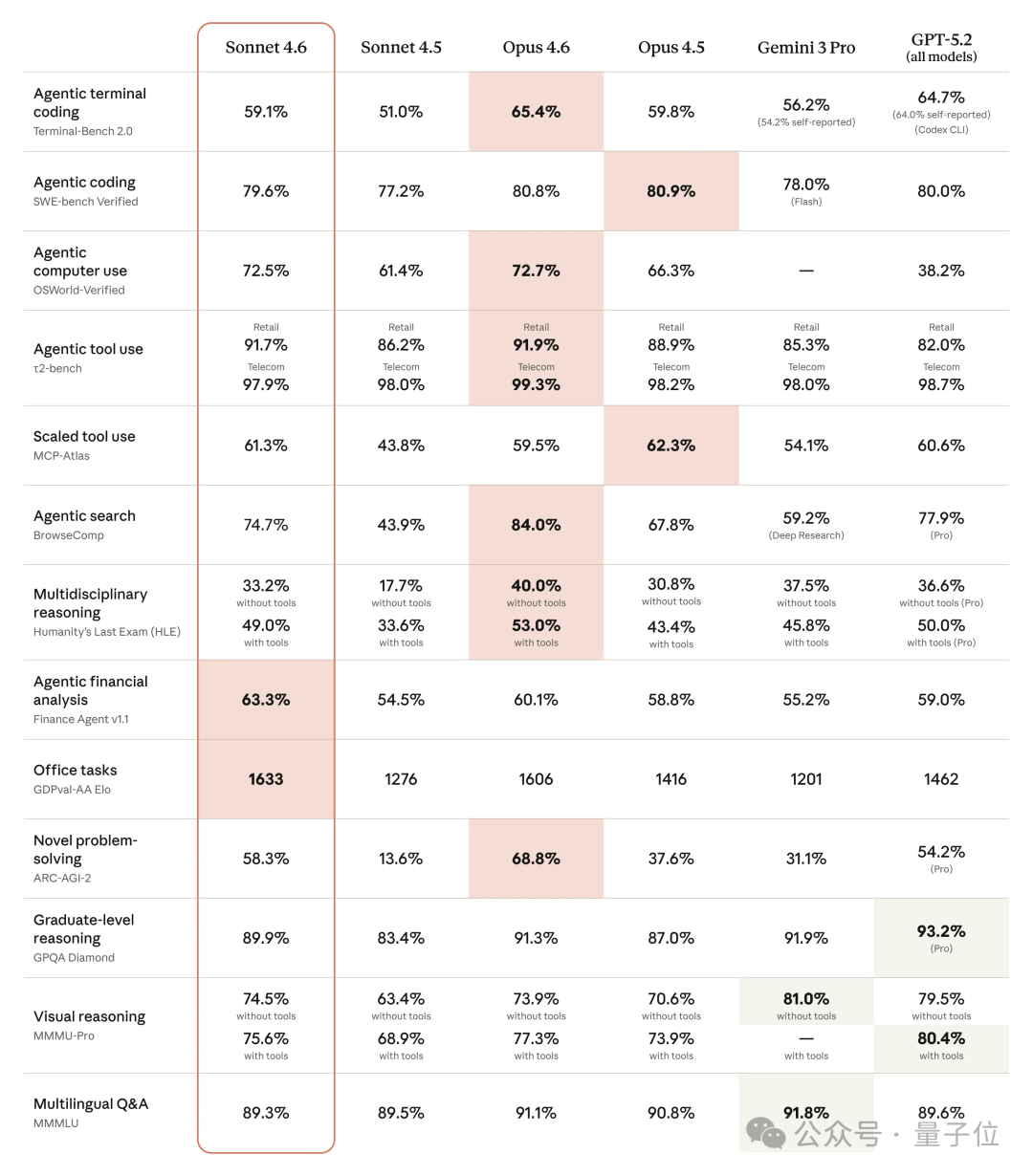
事实上,计算机操作只是冰山一角,Claude Sonnet 4.6 在各类 Benchmark 上都有提升。
具体细节都在下面这张表,一个大杯模型,智能却直逼超大杯 Opus 系列。
从 Benchmark 上还可以看到 Claude 这边出现了「倒反天罡」的情况。
在金融分析和办公室任务这两项测试中,Sonnet 4.6 用一骑绝尘的数值,拿下了 SOTA,力压历代 Opus。
用户的反馈更能说明问题。
在 Claude Code 的早期内测中,Anthropic 发现,在 59% 的场景下,用户更倾向于选择 Sonnet 4.6(而不是 Opus 4.5)。
大家评价说,Sonnet 4.6 明显更少出现过度设计和「偷懒」,指令遵循方面表现更好。
同时,虚假成功声明更少,幻觉更少,多步骤任务的执行也更加稳定。
对了,这次 Sonnet 4.6 还提供 100 万 token 的上下文,能装下几十篇研究论文。最重要的是,在这么大规模的上下文中,Sonnet 4.6 依然保持了相当领先的推理水平。
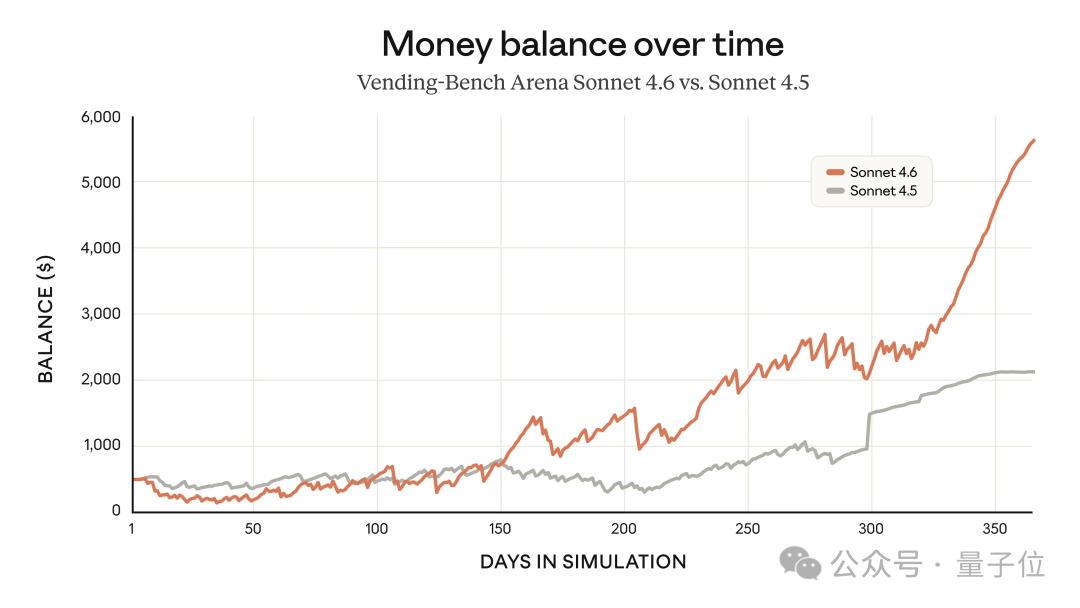
这一点在 Vending-Bench Arena 上特别明显。
这是个测试模型在长时间跨度内模拟运营一家企业能力的 Benchmark,引入了竞争机制,不同模型需要相互对抗,争取更高利润。
在这个测试中,Sonnet 4.6 采用了一种新策略:前 10 个模拟月份大幅投入产能建设,支出明显高于竞争对手,但在后期迅速开始想办法盈利。
这种转向时机的把握,帮助它在最终成绩上明显领先。
除此之外,用户还反馈称前端代码生成能力有提升。
Sonnet 4.6 生成的视觉输出更加精致,布局、动画和设计感都比之前的模型好,达到可用于生产环境的质量所需的迭代轮次也减少了。