OpenAI又出新编程模型,这次速度极快大模型LLM日知录
· OpenAI 推出了 GPT-5.3-Codex-Spark,这是一个专为实时编程设计的紧凑型模型,运行在针对推理优化的 Cerebras 芯片上,每秒可处理超过 1000 个词元。
· 其速度使开发者能够实时打断并调整模型,并立即看到结果。
· 然而,这个较小的模型以牺牲精度来换取速度:在 Terminal-Bench 2.0 基准测试中,Codex-Spark 的准确率为 58.4%,而更大的 GPT-5.3-Codex 准确率为 77.3%。
OpenAI 发布了 GPT-5.3-Codex-Spark,这是其 GPT-5.3 Codex 编程模型的一个更小版本,专为实时编程而构建。该模型运行在 Cerebras 芯片上,每秒处理速度超过 1000 个词元。
Codex-Spark 是 OpenAI 一月份宣布的 Cerebras 合作项目中首个面世的产品。该模型运行在 Cerebras 的晶圆级引擎 3 上,这是一款专为快速推理设计的 AI 加速器。
Cerebras 在拿下 OpenAI 协议后,以 230 亿美元估值完成 10 亿美元融资轮
该研究预览版现已面向 ChatGPT Pro 用户,在 Codex 应用程序、命令行界面和 VS Code 扩展中提供。OpenAI 表示计划在未来几周内扩大访问范围。据该公司称,由于该模型运行在专用硬件上,因此适用单独的速率限制,并且在高需求时期可能会进行调整。
Codex-Spark 优先考虑速度而非自主性
OpenAI 较大的前沿模型,例如新发布的 Codex 5.3(OpenAI新代码模型GPT-5.3-Codex在训练和部署过程中帮助构建了自身),旨在自主运行数分钟或数小时,以处理复杂的编程任务。Codex-Spark 则采用了不同的方法:OpenAI 表示,该模型针对交互式工作进行了优化,在这种场景下,延迟与智能同等重要。开发者可以实时打断并调整模型,并立即看到结果。
据 OpenAI 称,Codex-Spark 在操作方式上有意保持保守。与较大的模型相比,它默认进行最小化、针对性的更改,并且除非用户明确要求,否则不会启动自动测试。该模型拥有 12.8 万的上下文窗口,并且仅处理文本。
精度稍逊,耗时锐减
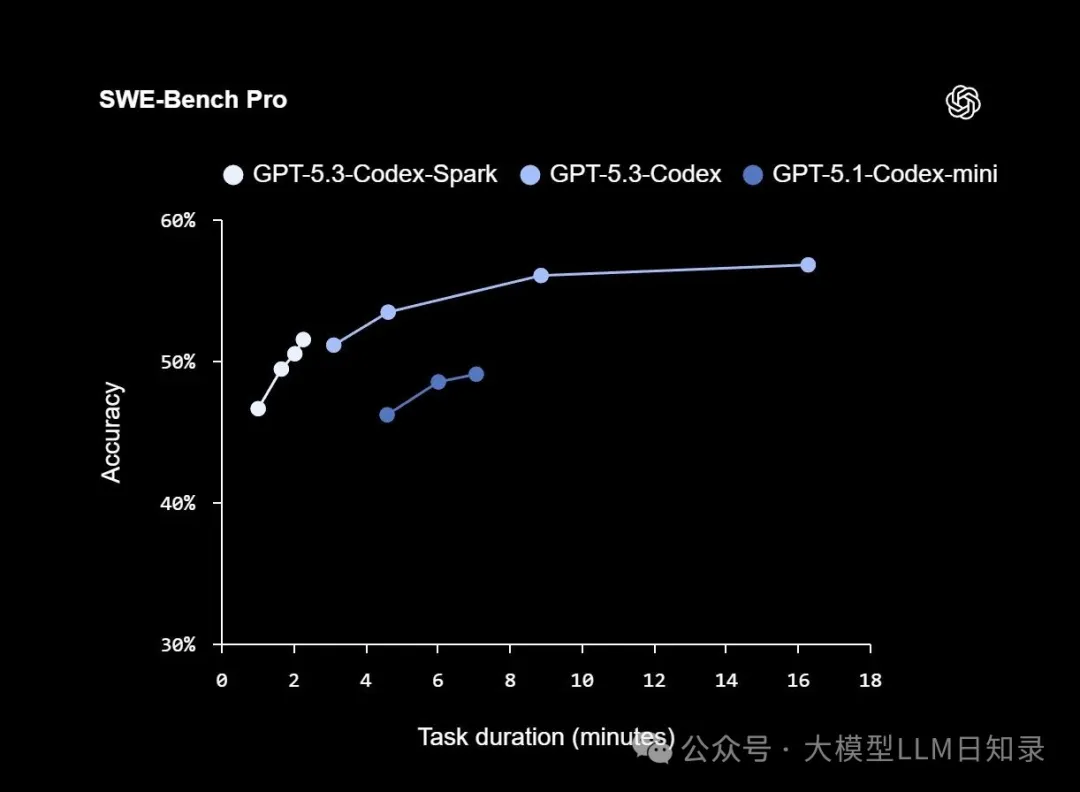
OpenAI 表示,Codex-Spark 在评估基于代理的软件工程能力的 SWE-Bench Pro 和 Terminal-Bench 2.0 基准测试中取得了强劲的成绩,并且完成任务所需的时间仅为 GPT-5.3-Codex 的一小部分。在 SWE-Bench Pro 上,Codex-Spark 大约需要两到三分钟即可达到相近的准确率,而 GPT-5.3-Codex 完成相同任务需要大约 15 到 17 分钟。
在SWE-Bench Pro基准测试中,Codex-Spark仅用两到三分钟就能达到甚至接近更大规模Codex模型的准确率——而GPT-5.3-Codex完成同样任务需要15到17分钟。| 图片:OpenAI
在 Terminal-Bench 2.0 上,Codex-Spark 的准确率达到 58.4%。较大的 GPT-5.3-Codex 准确率为 77.3%,而较旧的 GPT-5.1-Codex-mini 准确率为 46.1%。这两个较小的模型都是以牺牲精度来换取速度。
模型 Terminal-Bench 2.0 (准确率)
GPT-5.3-Codex-Spark 58.4%
GPT-5.3-Codex 77.3%
GPT-5.1-Codex-mini 46.1%
构建 Codex-Spark 迫使 OpenAI 不仅要加速模型本身。为了达到延迟目标,该公司重写了其推理栈的关键部分,精简了客户端与服务器之间的响应流式传输方式,并重新设计了会话启动流程以加速首个词元的显示。OpenAI 表示,其结果是:每轮往返开销降低了 80%,每个词元开销降低了 30%,并且首次词元生成时间缩短了一半。这些改进默认应用于 Codex-Spark,并即将推广到所有模型。
OpenAI 计划未来融合实时与推理模式
OpenAI 表示,Codex-Spark 是计划中的“超快速”模型系列中的第一个。更多功能即将推出,包括更大的模型、更长的上下文窗口和多模态输入支持。
长期来看,该公司正致力于为 Codex 开发两种互补模式:一种用于扩展推理和自主执行,另一种用于实时协作。OpenAI 表示,计划随着时间的推移融合这些模式,让开发者保持在快速交互循环中,同时将耗时较长的任务交由后台的子代理处理,或在多个并行运行的模型之间分配这些任务。