刚刚,DeepSeek V4基准测试泄露新智元
DeepSeek V4,据说明天就要上线了?这是首个匹敌顶尖闭源模型的开源模型,被网友评为「一鲸落万物生」。泄露的基准测试显示,它在SWE-bench Verified上取得了83.7%,已经超越Opus 4.5和GPT-5.2!
就在刚刚,一张图在全网疯狂刷屏了!
据说,DeepSeek V4的基准测试已经泄露,整个AI圈都震了。
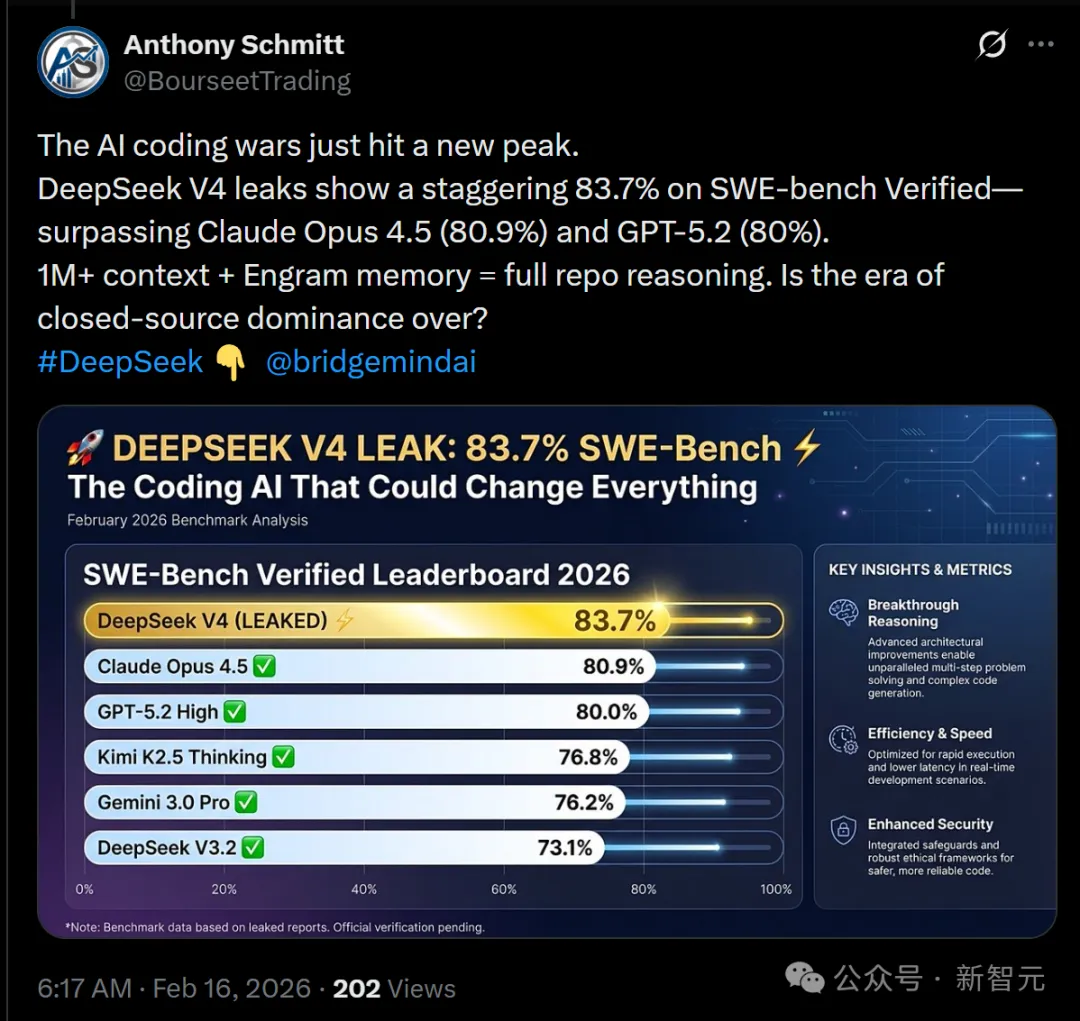
有大V总结道:AI编程大战,已经达到了新的高峰。
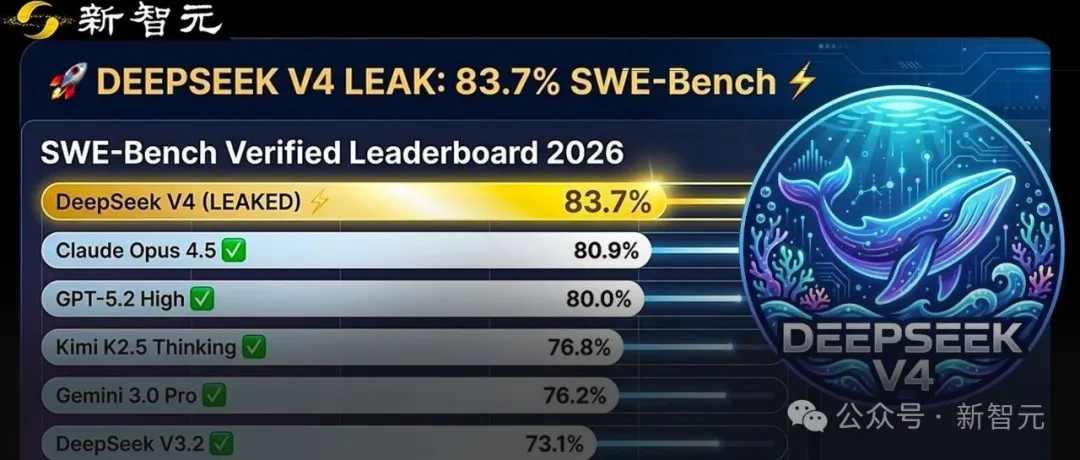
泄露信息显示,DeepSeek V4在SWE-bench Verified上取得了惊人的83.7%,超过了Claude Opus 4.5(80.9%)和GPT-5.2(80%)。
可以说,100万+上下文长度+Engram记忆机制=真正的全仓库级推理能力。
他惊呼:闭源模型占据主导的时代,是否正在走向终结?
同时泄露的,还有下面这一张图。
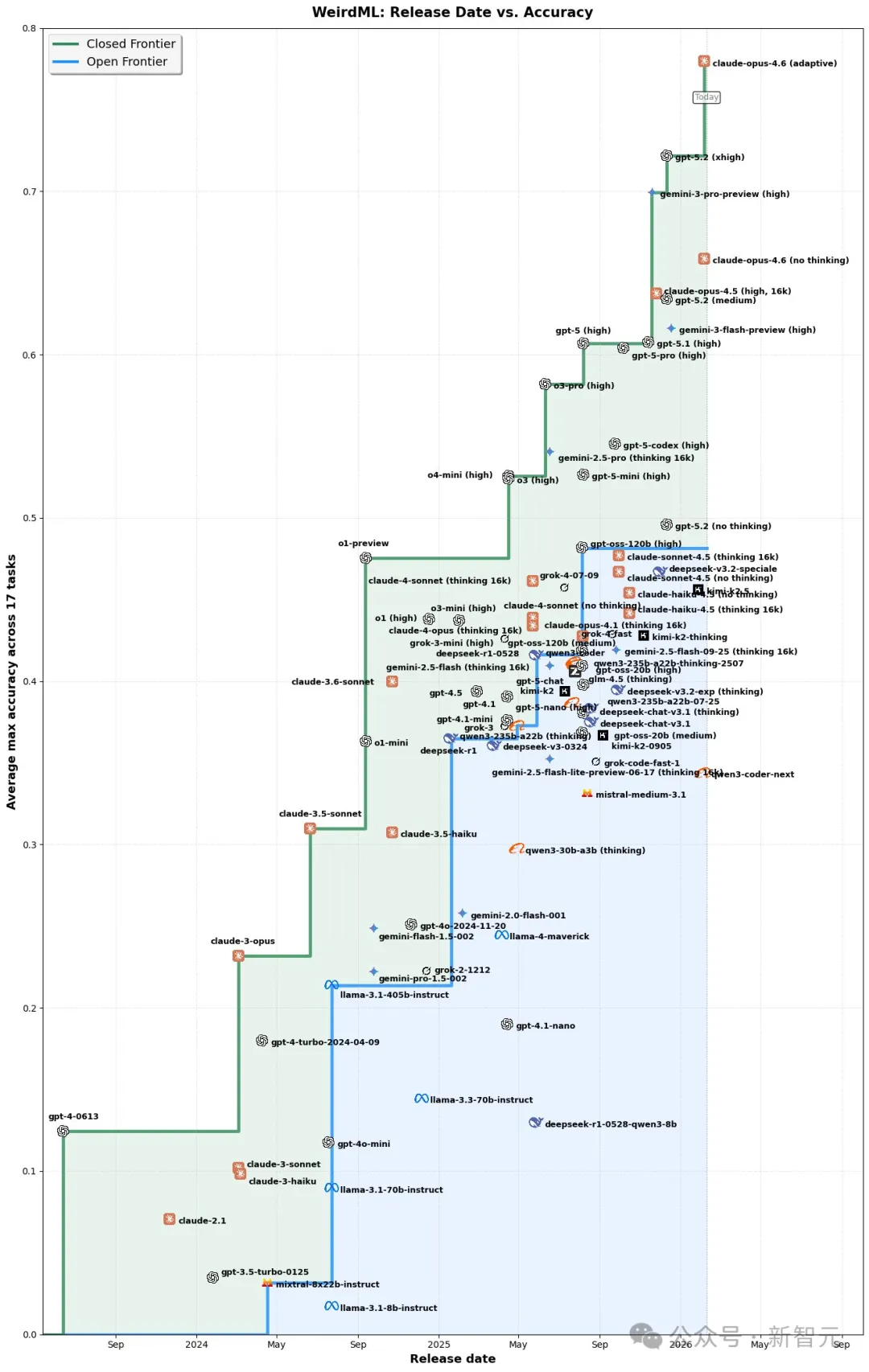
其中,它的SWE-Bench Verified得分,达到了83.7%。如果这个数字最终被确认,将直接改写当前「最强代码模型」排名!
相比之下,其他模型的得分都比较落后——
DeepSeek V3.2 Thinking:73.1%
GPT-5.2 High:80.0%
Kimi K2.5 Thinking:76.8%
Gemini 3.0 Pro:76.2%
这不是小幅领先,而是直接跃升到第一梯队顶端!
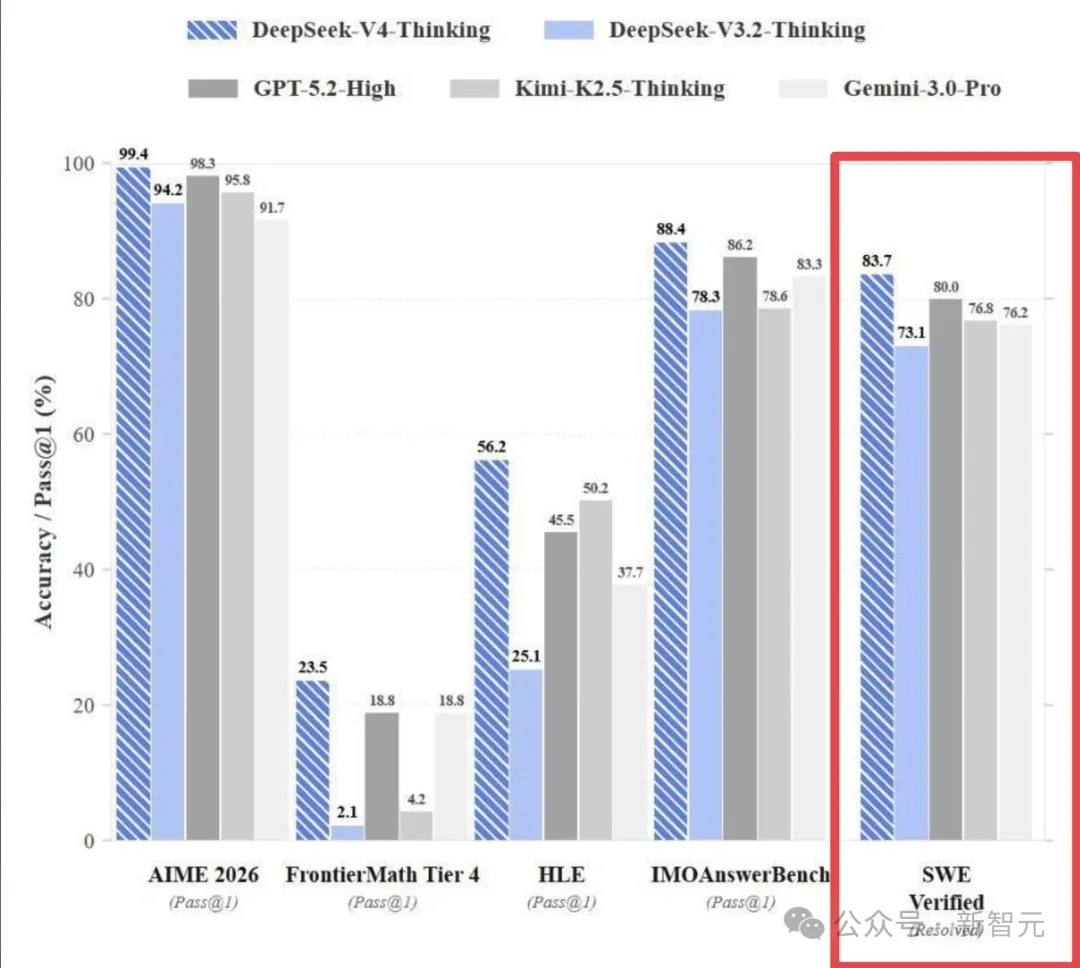
不仅如此,真正令人警惕的,并不只有编程能力,V4的其他分数也很惊人。
AIME 2026:99.4%
IMO Answer Bench:88.4%
FrontierMath Tier 4:23.5% (直接达到GPT-5.2的11倍)
这意味着什么?
如果这些数据属实,DeepSeek V4不是「又一个强模型」,而是一次能力曲线的陡峭抬升!
它可能会同时在代码、竞赛数学、前沿数学推理三个高难度维度上,刷新现有天花板。
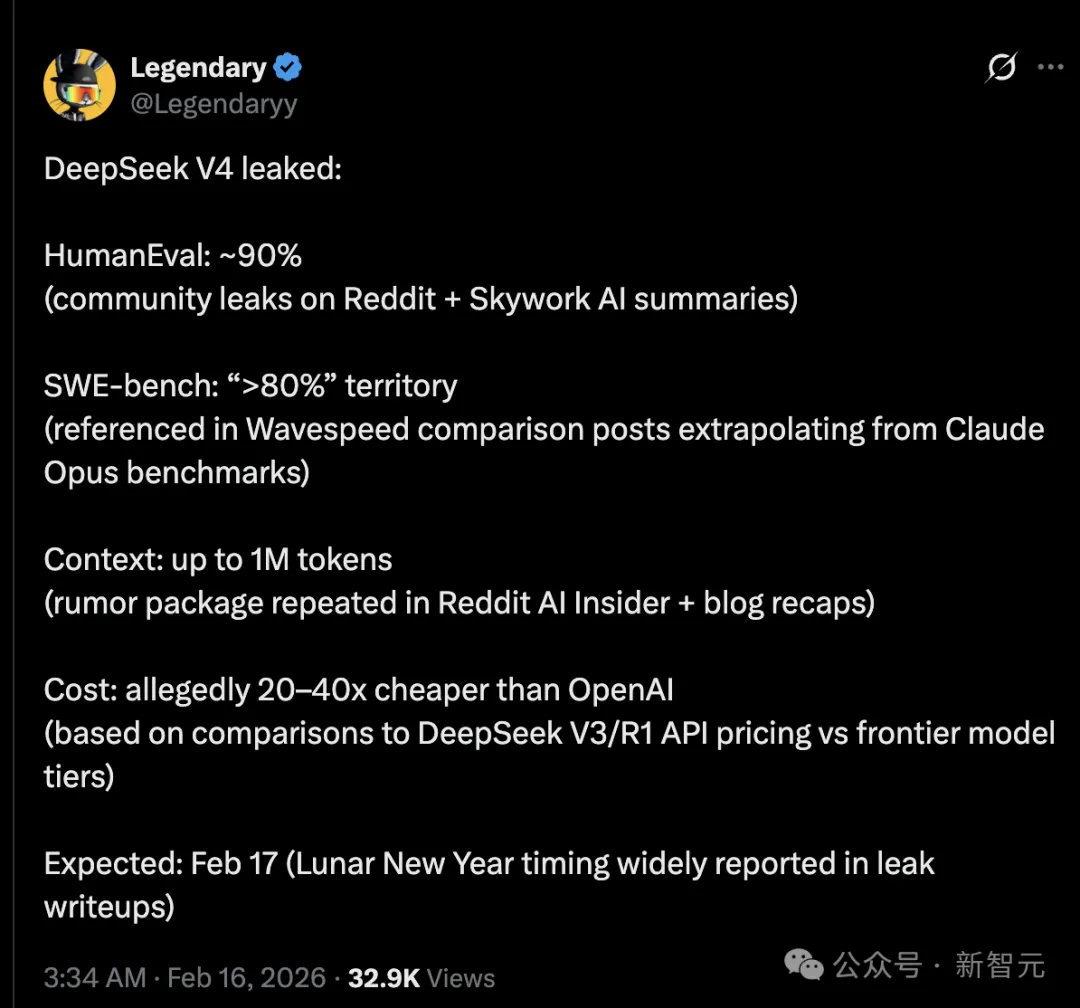
还有网友综合了全网DeepSeek V4消息,不仅在HumanEval、SWE_bench、上下文和成本上刷新成绩,而且发布时间预计在春节,也就是明天!
HumanEval:约90%(来自Reddit社区泄露 + Skywork AI总结)
SWE-bench:进入「>80%」区间(在Wavespeed对比帖中引用,根据 Claude Opus 基准推测得出)
上下文长度:高达 100 万 token(在Reddit AI Insider和博客总结帖中反复出现的传闻)
成本:据称比OpenAI便宜20到40倍(根据DeepSeek V3/R1 API 定价与前沿模型层级的对比推算)
预计发布时间:2月17日(农历新年期间,泄露文章中广泛报道)
如果是真的,DeepSeek将又一次改变游戏规则。
总之,DeepSeek V4的发布时间,很可能是周一。据说,这是首个不落后于闭源顶尖模型,甚至能与之匹敌甚至超越的模型。
有人说,以DeeepSeek-V4为代表的开源模型需要跨越的差距越来越大了!
很期待,当V4等中国开源模型发布后,这一差距会如何随着时间演变。