32k微调处理百万Token:实现恒定内存消耗量子位
当大模型试图处理一段包含100万token的超长文档时,会发生什么?答案是:内存爆炸,计算崩溃。
无论是分析整个代码库、处理万字研报,还是进行超长多轮对话,LLM的“长文本能力”都是其走向更高阶智能的关键。然而,Transformer架构的固有瓶颈──与上下文长度成平方关系的计算复杂度和线性增长的KV Cache,使其在面对超长序列时力不从心,变成了一个既“算不动”也“存不下”的“吞金巨兽”。
为了“续命”,现有方案要么选择上下文压缩,但这本质上是有损的,信息丢失不可避免;要么采用循环机制,但这类模型又常常“健忘”,难以保留贯穿全文的关键信息,也记不清刚刚发生的细节。
来自阿里巴巴未来生活实验室的研究团队洞察出问题的核心在于:模型缺乏一套能同时兼顾“远距离核心记忆”和“近距离高清细节”的协同系统。基于此,他们推出了一种全新的即插即用架构──协同记忆Transformer(CoMeT),让LLM拥有了高效处理无限长上下文的能力。
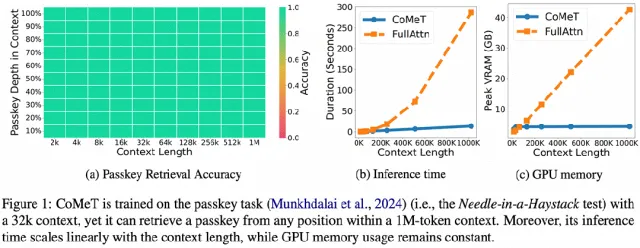
CoMeT令人意外的表现是:一个仅在32k上下文上微调的模型,竟能在100万token的文本中,精准无误地找到任何位置的“密码”,真正实现了“大海捞针”!并且,整个过程的推理时间和内存占用都得到了显著的优化。
△ CoMeT在32k上下文训练后,可在1M token中精准大海捞针,且推理速度和内存占用远优于全注意力模型
鱼与熊掌兼得:“协同记忆”架构
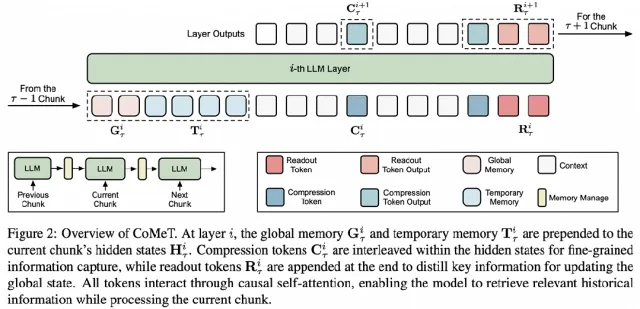
CoMeT的巧妙之处在于,它没有试图用单一机制解决所有问题,而是设计了一套双轨并行的协同记忆系统,让模型既能“记得牢”,又能“看得清”。
1. 全局记忆(Global Memory):一个带“门禁”的记忆保险箱
为了解决长期遗忘问题,CoMeT引入了一个固定大小的全局记忆。它的核心是一个精巧的门控更新机制(Gated Update)。当模型处理新的文本块时,这个“门禁”会智能判断新信息的重要性:如果信息至关重要,门控打开,将其写入长期记忆;如果信息不那么重要,门控保持关闭,保护已有的关键记忆不被冲刷。这套机制就像一个记忆的“保险箱”,确保那些贯穿全文的核心线索能够被长期、稳定地保存下来。
2. 临时记忆(Temporary Memory):一条高保真的“事件流”
为了保留近期细节,CoMeT引入了由先进先出(FIFO)队列管理的临时记忆。它像一条流动的传送带,持续将最近处理过的文本块信息进行高保真压缩并暂存。这保证了模型在做决策时,能随时访问到最临近、最详细的上下文信息,避免因信息丢失而导致的“断片”。这种设计优雅地平衡了长期记忆的稳定性与近期记忆的鲜活性。
△ CoMeT架构概览:全局记忆与临时记忆协同工作
通过全局和临时记忆的协同,CoMeT在处理每个文本块时,都能同时“回顾”长期核心信息和“审视”近期详细内容,最终实现了恒定的内存占用和线性的时间复杂度,从根本上打破了Transformer的性能瓶颈。
实践出真知:SOTA性能与惊人效率
CoMeT的强大不仅仅停留在理论上,实验结果更是令人印象深刻。
1. 权威基准全面超越,登顶SOTA
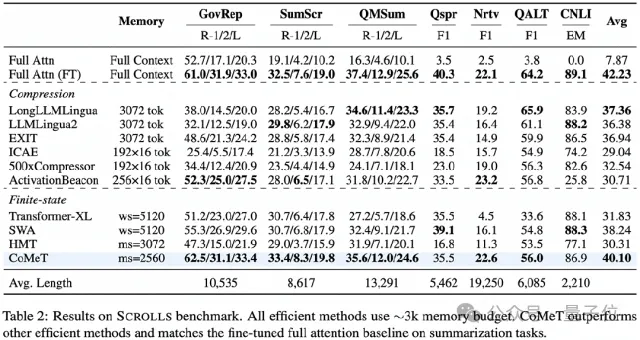
在公认的长文本评测基准SCROLLS上,CoMeT在同等内存预算下,平均性能超越了所有主流的高效长文本方法(如上下文压缩、其他循环机制模型),并在需要全局理解的摘要任务上,达到了与全注意力基线(Full Attention)相媲美的性能。
△ CoMeT在SCROLLS基准上超越其他高效方法
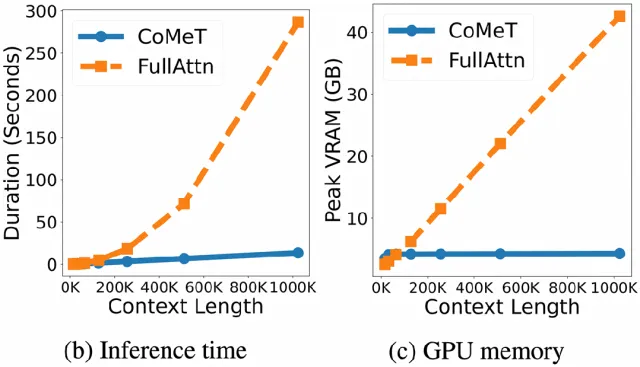
2. 效率革命:21倍加速,10倍显存节省
相较于标准的Full Attention模型,CoMeT在处理1M长度的文本时,实现了21倍的推理加速和10倍的峰值显存节省。这意味着,原本需要顶级算力才能勉强运行的任务,现在在普通硬件上也能高效完成,为长文本应用的落地扫清了障碍。
△ CoMeT在推理时间和内存占用上展现出巨大优势
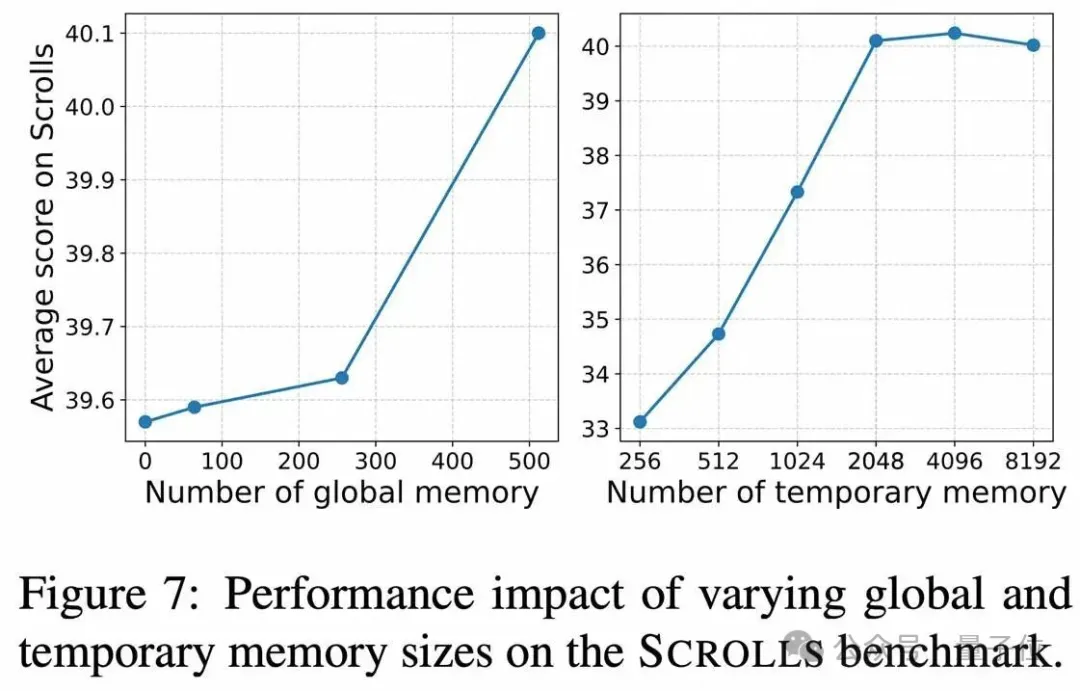
3. 关键洞察:1+1>2,不同记忆各司其职
研究团队的消融实验揭示了一个深刻的洞察:全局记忆和临时记忆并非简单叠加,而是各司其职,缺一不可。全局记忆是模型“看得远”的关键:只有依赖带门控的全局记忆,模型才能在远超训练长度的文本中保持记忆,实现强大的长度外推能力。临时记忆是模型“看得清”的保障:高保真的近期信息流是模型在处理复杂任务时,获得优异性能的基础。正是这种精妙的协同设计,才造就了CoMeT的卓越性能。
△ CoMeT的临时记忆有助于提高训练长度内的性能。