最强编程王者PK:Opus 4.6封神,Codex 5.3速度满分新智元
硅谷的夜再次被点亮,OpenAI和Anthropic同日发布最新模型。正当开发者们沉浸在Codex 5.3的极致速度时,Arena和Epoch两大权威榜单却给出了意想不到的终局判决。
硅谷这波热闹,属实有点上头。
前脚Claude Opus 4.6刚刚夜袭发布,后脚OpenAI就祭出了GPT-5.3-Codex。
两大「编程王者」正面硬刚,到底谁的能力更强?社区现在还吵翻天~
今天,两大最硬核的权威机构Arena.ai和EpochAI,同时为Opus 4.6加冕!
Arena.ai:Opus 4.6全维度的屠榜
Arena.ai(前身是大家熟知的LMArena),这个被称为「大模型角斗场」的地方,迎来了新的霸主。
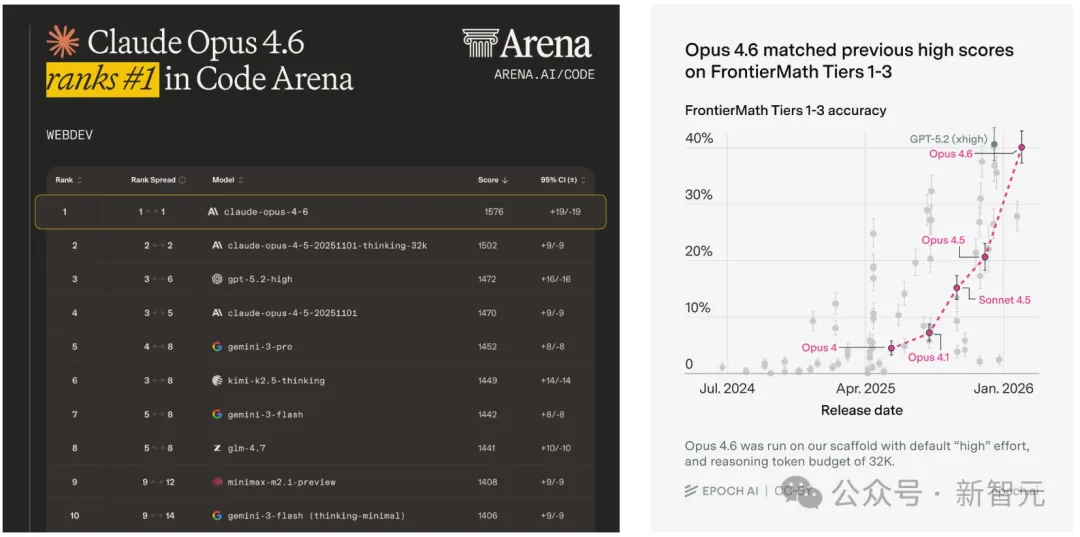
Claude Opus 4.6,在代码(Code)、文本(Text)、专家(Expert)三大竞技场,全部登顶第一!
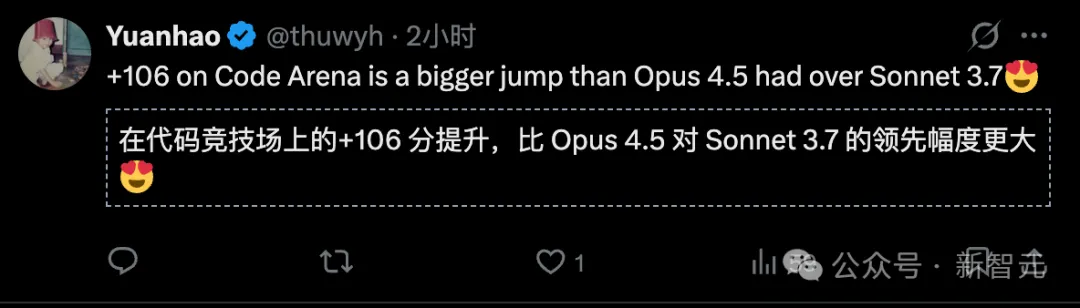
代码竞技场:比前代Opus 4.5暴涨106分。
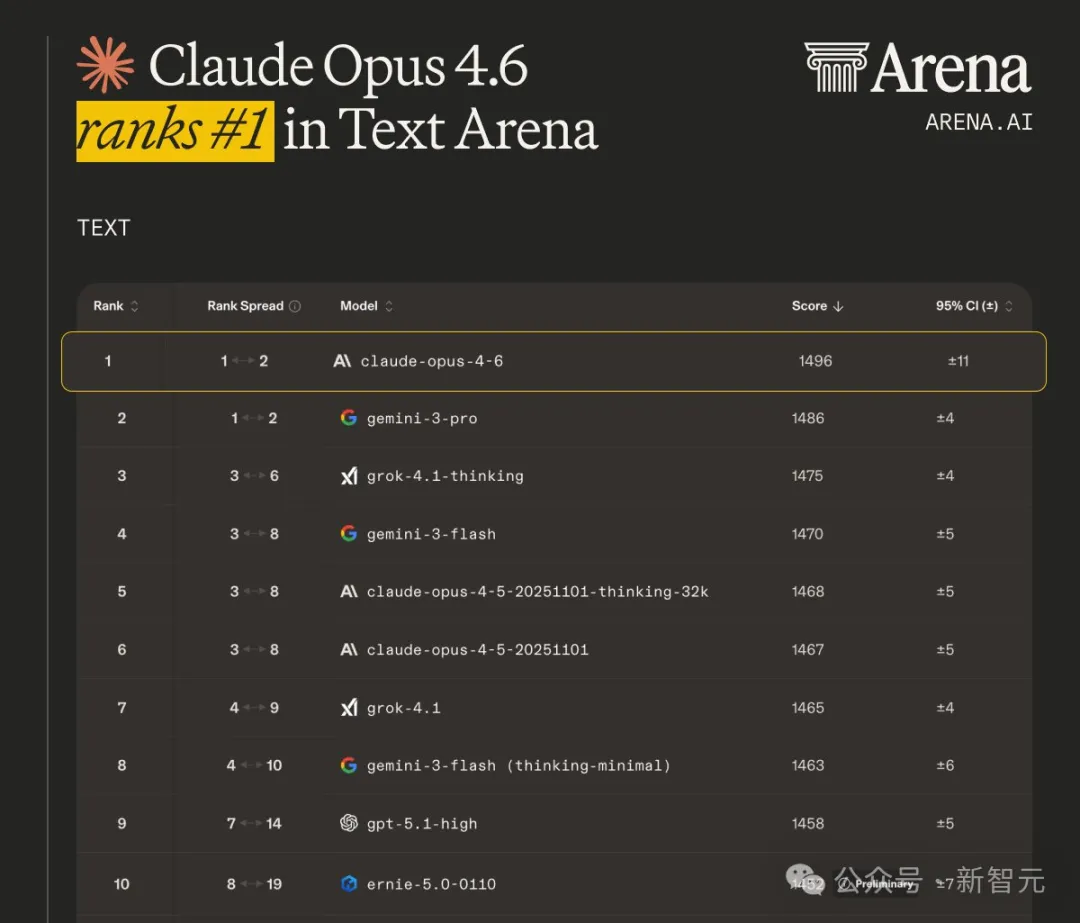
文本竞技场:得分1496,硬生生压了Gemini 3 Pro一头。
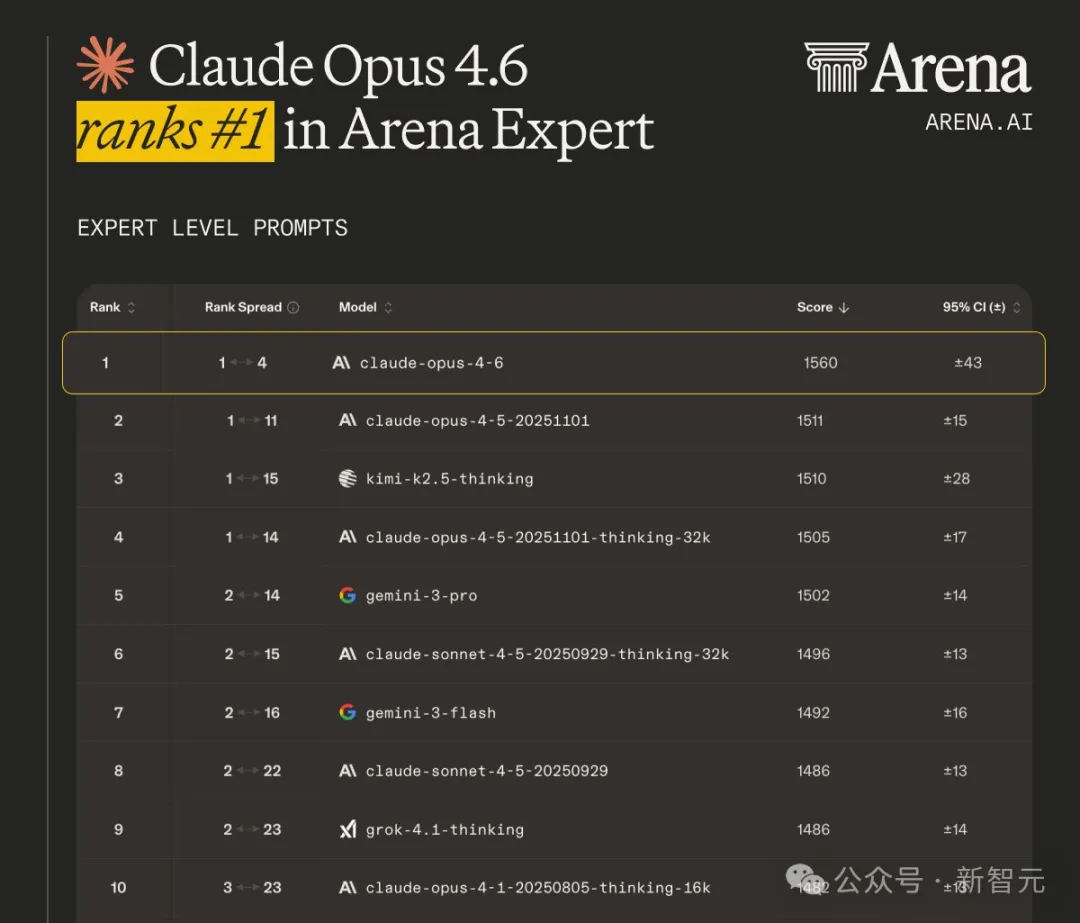
专家竞技场:领先第二名约50分,断层式领先。
这意味着什么?
意味着在数以万计的真实人类盲测中,Opus 4.6是那个让你最想点「赞」的模型。
它不是偏科生,它是真正的六边形战士。
在代码实测中,这次的Opus 4.6比4.5提升了106分,远超之前Opus 4.5对Sonnet 3.7的领先幅度。
Claude Opus 4.6自Claude 3 Opus以来首次在文本竞技场排名第一。
同时在关键文本类别中位列榜首:
Claude Opus 4.6在专家领域排名第一,领先优势达+49分。
专家排行榜采用了一个框架构建,该框架能识别出真实用户提出的最困难、最专业的提示。
有网友表示,能够在这三个领域同时拿下第一,是真正的SOTA,非常厉害。
有网友同时表示,这Opus 4.6拿下三冠王很厉害,但是真正对模型的考验是前沿数学能力。
这不,EpochAI的评测新鲜出炉!
EpochAI:啃下「数学硬骨头」
如果说Arena是大众评审,那EpochAI的Frontier Math就是「奥数竞赛」。
这里考的不是简单的加减乘除,而是人类尚未解决的数学难题。
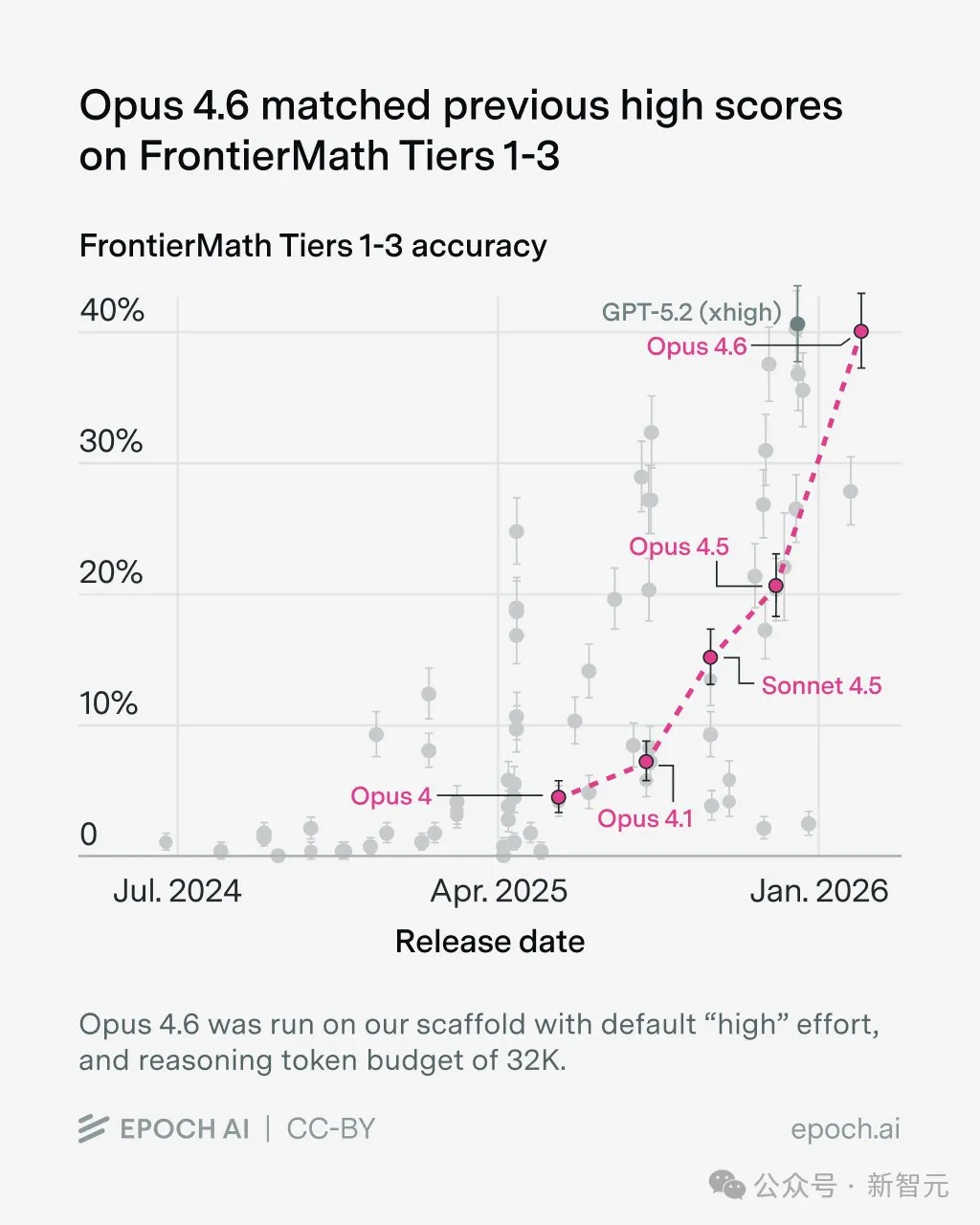
Opus 4.6交出的答卷是:Tier1-3级别得分40%,Tier4(极难)级别得分21%。
这个成绩直接在统计学上追平了GPT-5.2(xhigh)。
这是Anthropic的模型第一次在这个只要有一点「智商欠费」就交白卷的榜单上,站到了最前沿。
在难度更高的第4级测试中,Opus 4.6获得 21%的得分,解决了48道题目中的10道。
该成绩同样与GPT-5.2(xhigh)的19%得分在统计上持平,仅次于 GPT-5.2(Pro)31%的得分。
物理、数学,这些曾经是AI禁区的地方,现在成了Opus 4.6的后花园。
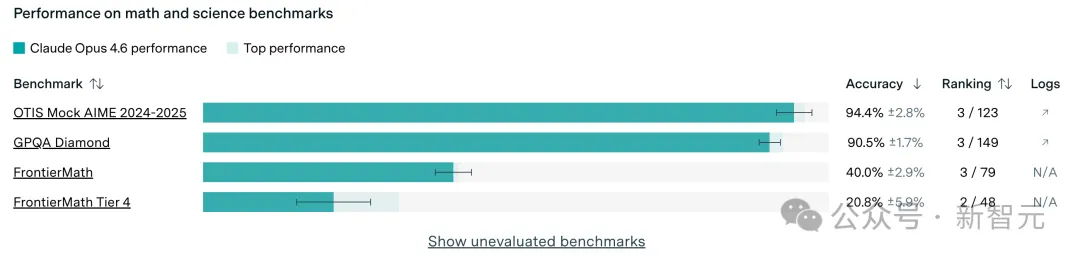
Opus 4.6模型表现非常抢眼的领域,多项得分位居前列:
OTIS Mock AIME 2024-2025:得分高达94.4%,展现了极强的竞赛级数学解题能力。
GPQA Diamond:得分90.5%,这是一个针对专家级科学问题的困难测试。
FrontierMath:这是一个极其困难的数学前沿测试,Opus 4.6 得分为40.0%。在更难的 Tier 4 级别中,它获得了 20.8% 的分数,排名第 2。
在综合与推理评测中:
ARC AGI v1:得分94.0%,排名第1。这是评估模型通用人工智能(AGI)潜力的核心指标之一,专注于抽象推理和模式识别。
SimpleQA Verified:得分46.5%。该测试主要评估模型回答事实性问题的准确度(减少幻觉)。