又一中国大模型登Nature智东西
2月1日报道,北京时间1月29日,北京智源人工智能研究院推出的多模态大模型“悟界·Emu”登上Nature正刊,成为继DeepSeek之后第二个达成此成就的中国大模型团队研究成果,也是中国首篇围绕多模态大模型路线的Nature论文。
Nature官网截图
Nature编辑点评道:“Emu3仅基于‘预测下一个token’实现了大规模文本、图像和视频的统一学习,其在生成与感知任务上的性能可与使用专门路线相当,这一成果对构建可扩展、统一的多模态智能系统具有重要意义,有望推动原生多模态助手、世界模型以及具身智能等方向的发展。”
Emu3有望推动具身智能等方向发展
“悟界·Emu3”模型由智源研究院于2024年10月推出。无论在感知和还是生成方面,Emu3均达到了与特定任务旗舰模型相媲美的性能。该模型能够完成文本到图像生成、文本到视频生成、未来预测、视觉语言理解、交错图像文本生成以及具身操作等多方面任务,这一成果对于确立自回归成为生成式AI统一路线具有重大意义。
如下图所示,Emu3的图像生成在MSCOCO-30K23等基准上表现优于SDXL等扩散模型;视频生成在VBench评分达81,超过Open-Sora 1.2;视觉语言理解得分62.1,略高于LLaVA-1.6。尽管这一成绩在如今已经比较寻常,但在两年前却非同一般。
Emu3图像生成、视觉-语言理解和视频生成的主要测评结果
前OpenAI政策主管、现Anthropic联合创始人杰克·克拉克(Jack Clark)当时评价Emu3:“不依赖花哨的架构技巧,仅用最基础的预测下一个token的逻辑,这种‘简单’被视为具备强大的扩展潜力。”
而正是这种“简单”架构路线,对降低大模型研发门槛和成本意义重大。“越是极简的架构,可能越具备强大的生产力,对产业的价值也越大。”智源研究院院长王仲远告诉智东西,“因为它简化了多模态AI架构,减少了研发过程中的复杂性和潜在错误,从而使模型的构建和维护更高效。”
智源研究院院长王仲远
到2025年10月,“悟界·Emu”系列已迭代出多模态世界模型。Emu3.5可以理解长时序、空间一致的序列,模拟在虚拟世界中的探索和操作,不仅超越谷歌Nano Banana等模型拿下多模态SOTA,并首次指明了“多模态Scaling 范式”,让模型自发学习世界演变的内在规律,为具身智能等物理AI领域发展提供了重要新路径。
Emu3.5延续了多模态数据统一建模的核心思想
Emu3为什么能够登上Nature正刊,得到国际学术界的高度认可?背后诞生了什么样的AI原创技术,并经历了什么样的挑战?这又将对学界和产业界的发展产生什么样的实际影响?本文试图对这些问题进行深入探讨。
《通过预测下一个token进行多模态学习的多模态大模型(Multimodal learning with next-token prediction for large multimodal models)》
Emu3论文部分截图
一、50人小组死磕“统一”:一场押注AI未来的技术豪赌
Emu3模型最早立项是在2024年2月,当时正值团队重新审视大模型发展路径——随着GPT-4、Sora的爆火,“预测下一个token”自回归路线彻底改变了语言模型领域,并引发了关于AGI早期迹象的讨论,而在多模态生成领域,DiT(Difussion Transformer)架构成为主流,开始展现出令人惊艳的生成效果。
自回归技术路线是否可以作为通用路线统一多模态?一直是未解之谜。
Emu3的开创性,就在于仅采用“预测下一个token(NTP)”自回归路线,就实现统一多模态学习,训练出性能出色的原生多模态大模型。
时间线拉回到立项之前,当时智源研究院团队进行了大量分析和辩论,达成一个共识——多模态是未来实现AGI的关键路径,但现有的多模态生成长期以来由扩散模型主导,而视觉语言感知则主要由组合式方法引领,并不收敛统一,存在技术天花板。
尽管已有业内人士试图统一生成与感知(如Emu和Chameleon),但这些工作要么简单地将大语言模型与扩散模型拼接在一起,要么在性能效果上不及那些针对生成或感知任务精心设计的专用方法。
自回归架构能否作为原生统一多模态的技术路线,信与不信,这是一个重大的技术决策。最终在2024年2月底,智源研究院决定,组建一支五十人的技术攻关团队,以自回归架构为核心进行研发,并采用离散的token方式,以精简架构和大规模复用的大语言模型基础设施,开启全新的多模态模型Emu3的研发工作。
该模型开创性地将图像、文本和视频统一离散化到同一个表示空间中,并从零开始,在多模态序列混合数据上联合训练一个单一的 Transformer。
Emu3可完成不同多模态任务
这是一条挑战传统的“冒险”之路,在成功之前,智源研究院团队经历了重重挑战。
首先不言而喻的是技术上的挑战。选择“离散的token”方式本身是一种冒险,因为它尝试为视觉和其他模态重新发明一种与人类文字语言对齐的语言体系。在图像压缩过程中,由于图像信息相较于文字的信息量更大,但冗余更多,这使得基于token压缩图像时难以训练出有效模型,在这个过程中也难免受挫和沮丧。
第二,更深层次的是路径上的质疑。2024年国内各个大模型团队都在如火如荼地复现GPT-4,很多头部玩家一边也布局了多模态模型,但实际过程中存在摇摆,最终因资源消耗大、主线仍聚焦于语言模型等原因而砍掉了团队。智源研究院在这样的产业大背景下坚持了下来,背后需要一号位强大的信念和团队强大的定力。
第三,“多模态能否提升模型的智能”这个问题,当时还没有完全成定论。但智源团队坚信,下一代模型如果要进入到物理世界,仅靠文字是不够的,需要一个“见过世界”的模型。他们相信,不管突破多模态模型乃至世界模型智能升级有多难,它都是实现AGI的一条必经之路。
二、性能匹敌专用模型:两年,Emu3已深度影响产业发展脉络
多位业内专业人士告诉智东西,Emu3模型发布两年多以来,已经对多模态领域产生了显著影响,推动了整个产业的发展脉络。有证据表明其在产业界中得到了广泛应用和高度认可。
而进入产业应用的前提,是Emu3首先打赢了“性能”这一仗。在多模态生成与感知任务上,Emu3的整体表现可与多种成熟的任务专用模型相媲美。
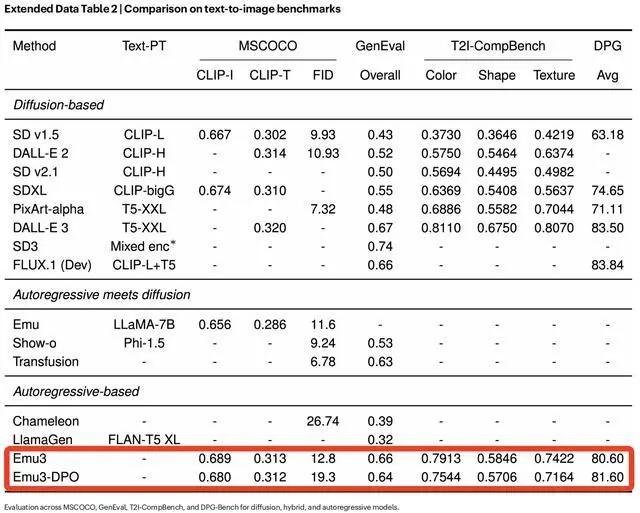
首先聚焦文本到图像生成能力,在MSCOCO-30K23、GenEval24、T2I-CompBench25等多个基准上,Emu3的性能与当时最先进的扩散模型相当:超越了SD1.5、SDXL等模型,并接近DALL-E 3、FLUX.1(Dev)等模型。
Emu3的性能与最先进的扩散模型相当