Clawdbot如何像大脑般记住一切?新智元
一个开源AI,能记住你几个月前的决定、在本地替你跑活、还不受大厂控制:Clawdbot到底是个人助理,还是下一代「赛博打工人」?
Clawdbot太疯狂了!
你的7×24小时AI员工;
不是智能体,是赚钱机器 ……
2026年初,一个名为Clawdbot的开源个人AI助手,迅速引爆了开源社区和硅谷极客圈。
从技术爱好者到普通用户,许多人玩Clawdbot都玩疯了,一开发起来,根本都停不下来。
甚至,还有人把Clawdbot当成了赚钱工具,开始兜售Clawdbot赚钱指南,还不忘贩卖一波焦虑:
错过了Clawdbot浪潮,你将永远沦为「数字底层」!
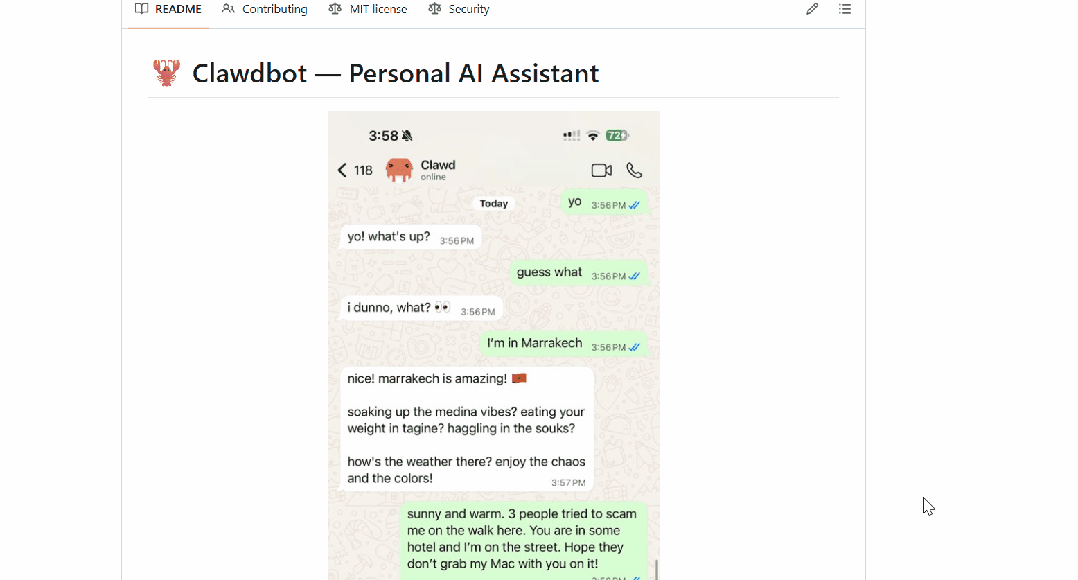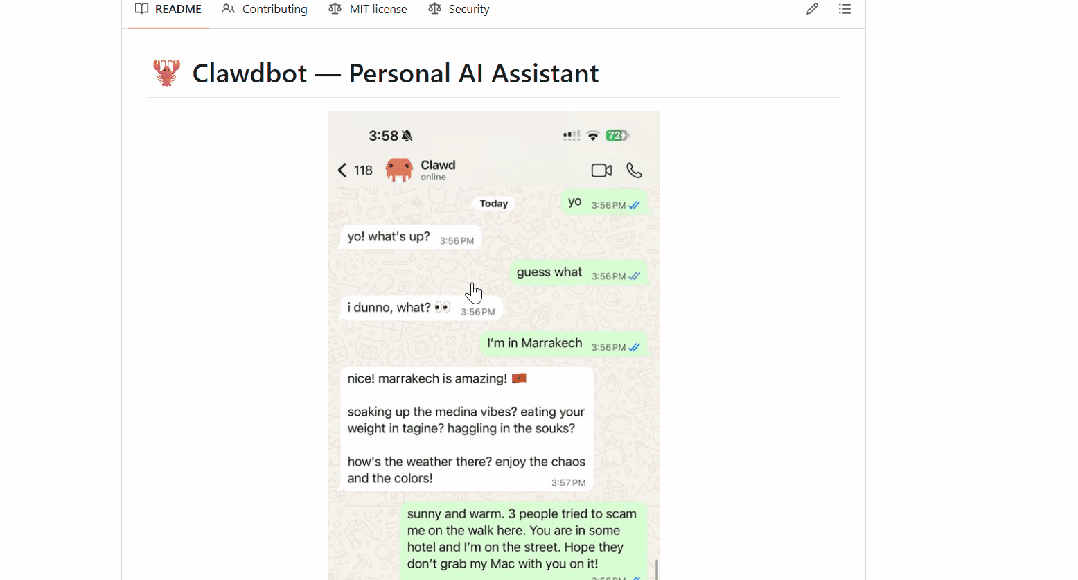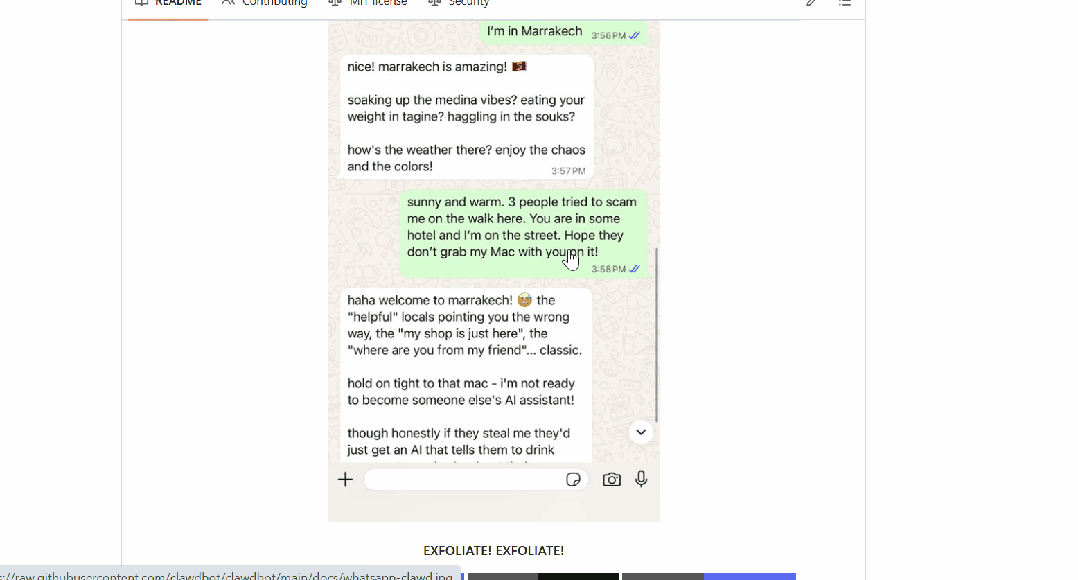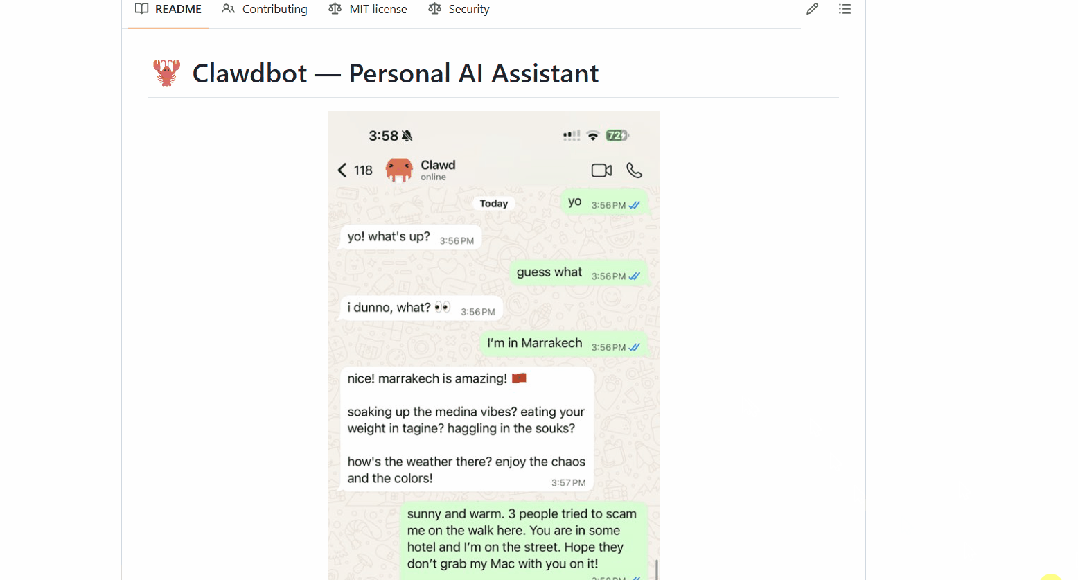
Clawdbot被网友称为「长了手的Claude」或者「7×24在线的贾维斯」,它最大的亮点之一,便是长时记忆和长时任务执行能力。
回想一下你目前是如何使用AI助手的。
你在浏览器中打开AI助手,输入问题,得到回复,然后关闭标签页;但当你明天再回来时,又得从头开始。
它不会记住你昨天讨论过的内容,不了解你的偏好、你的项目,也不了解你的工作流程。
你可能会好奇Clawdbot是如何记住那么多东西的,最近AI研究工程师Manthan Gupta就写了一篇文章来回答这个问题。
他在「Clawdbot如何记住一切」一文中详细复盘了Clawdbot独特的记忆机制原理。
与那些跑在云端的ChatGPT或者Claude不一样,Clawdbot是直接在你本地机器上跑的,而且能直接集成到你已经在用的聊天平台里,比如Discord、WhatsApp、Telegram等。
最绝的是,Clawdbot能自主处理现实世界的任务:管理邮件、安排日历、处理航班值机,还能按计划跑后台任务。
但真正吸引Manthan Gupta眼球的,是它的持久记忆系统:它能保持全天候的上下文记忆,记住之前的对话,并且能基于过往的互动无限叠加。
相比于ChatGPT和Claude,Clawdbot走了一条完全不同的路子:
它不搞那种基于云端、由大公司控制的记忆,而是把所有东西都留在本地,让用户完全掌控自己的上下文和技能。
下面,我们就来跟随Manthan这篇文章,来深挖一下Clawdbot是怎么运作的。
上下文与记忆
Clawdbot的基本问题定义
如何构建上下文
在聊记忆之前,咱们先得搞清楚模型在处理每个请求时到底看到了什么:
系统提示词定义了AI智能体有多大能耐以及有什么工具可用。
跟记忆有关的是项目上下文,这包括了注入到每个请求中的、用户可编辑的Markdown文件:
这些文件跟记忆文件一块待在AI智能体的工作区里,这就让整个AI智能体的配置变得完全透明,而且你想改就改。
上下文与记忆的区别
搞清楚上下文和记忆的区别,是理解Clawdbot的基石。
上下文是模型在单次请求里看到的所有东西:
转瞬即逝的:只在这个请求里存在,用完即弃
有边界的:受限于模型的上下文窗口 (比如200 Token)
昂贵的 :每个Token都要算API的钱,还影响速度
记忆是存在硬盘里的东西: