Claude实现「永久记忆」新智元
昨天,Claude刚刚被曝要有永久记忆,今天就被开发者抢先一步。一个叫Smart Forking的扩展,让大模型首次拥有「长期记忆」,无需重头解释。开发者圈沸腾了:难以置信,它真的能跑!
昨天,一篇Claude要获得永久记忆的爆料,震惊整个AI圈。
这种「知识库」的全新记忆方式,可以让Claude在自己的永存大脑中,自动记住一切。
巧的是,就在今天,就有开发者抢先「截胡」。他在现有工具上实现了一个扩展能力——Smart Forking detection,让大模型第一次拥有了「可继承的长期记忆」!
这个所谓的Smart Forking,通过给Claude Code会话嵌入向量数据库,让它能从成百上千次的历史对话中,找到最相关的前文。
因此,你不必再重新解释,Claude可以直接「接上文」搞开发了。
这个功能一出,开发者社区直接炸锅了。大家纷纷表示:「不敢相信,它居然真的跑起来了!」「这一刻,我是真的被震撼到了。」
强烈推荐每一个Claude Code用户,都把这个思路直接加入自己的工作流!
英雄所见略同,但路径不同。当官方还在设计永久记忆的形态时,开发者已经用Smart Forking,提前过上了「Claude有长期记忆」的生活。
而且,最近这个一天甩出一个王炸的节奏,实在太震撼了。2026开年这一个月,Anthropic真是名副其实的硅谷新GOAT,在开发者圈拥有无上的影响力。
让大模型「拥有」长期记忆
跟昨天Anthropic被曝的官方知识库相比,今天这个功能不仅有演示,还有技术细节。
你有没有遇到过这种情况:想在一个已有项目里加新功能,但完全不想再从头解释一遍背景?
那有没有可能利用起在成百上千次Claude Code对话中积累的知识呢?
毕竟,一个对话里包含的有效上下文越多,Claude 实现需求的效果就越好。怎样才能让这些宝贵的上下文信息,不要白白浪费了?
这位开发者想到一个办法——smart forking(智能分叉)!
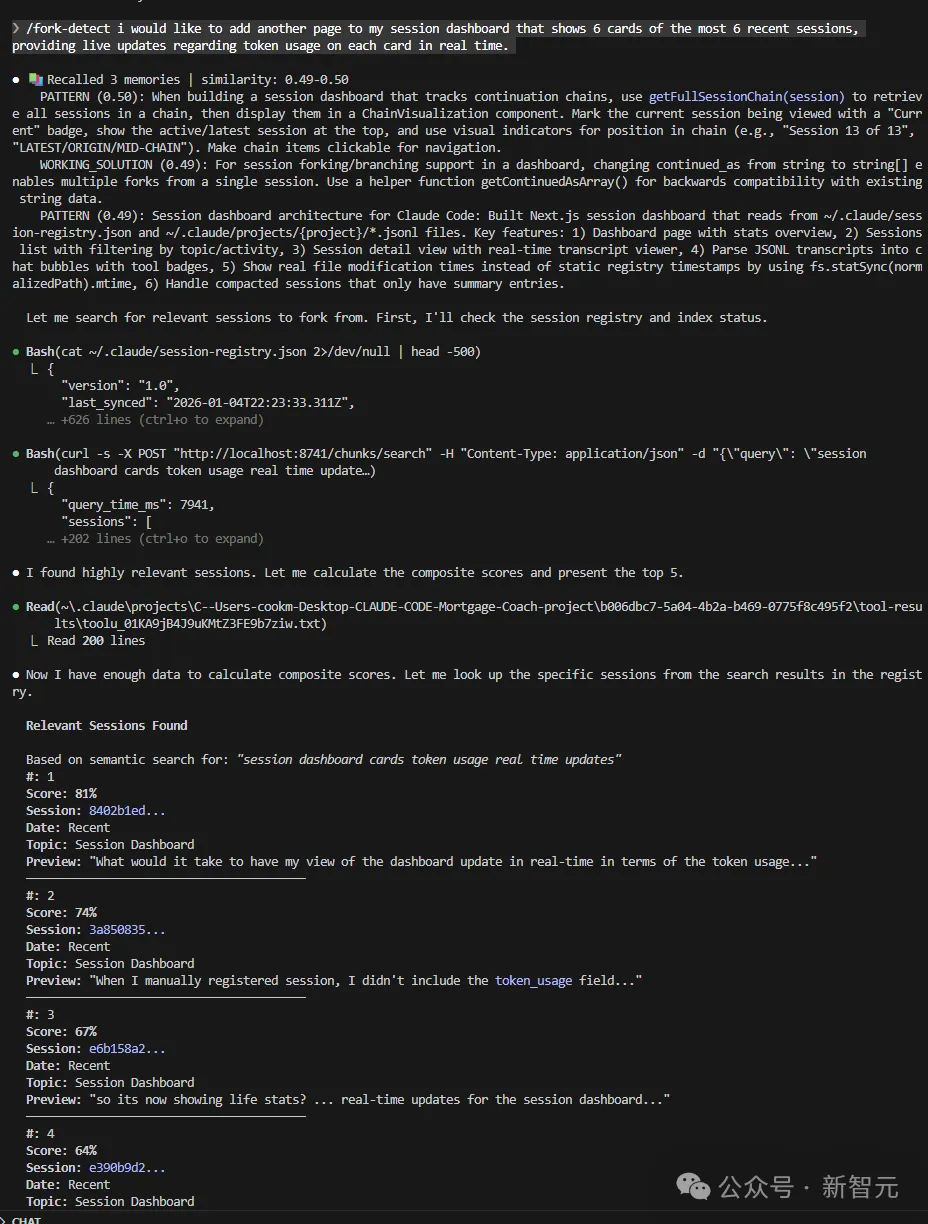
只需要调用 /fork-detect 命令,告诉它你现在想做什么,Claude就会把你的需求送进嵌入模型;然后,和一个包含你所有历史聊天记录的RAG向量数据库进行匹配(而且,这个数据库会随着你新的会话自动更新)。
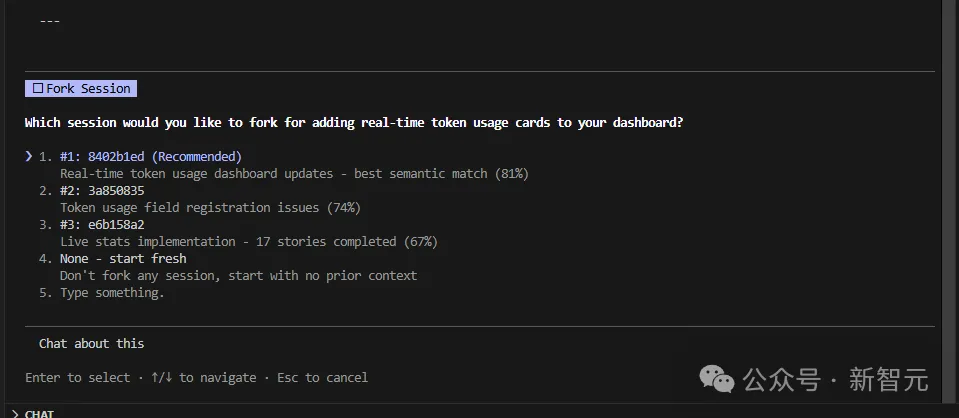
接着,它会返回一个与你当前需求最相关的前5个历史会话,并为每一个打上相关度评分,从高到低排序。
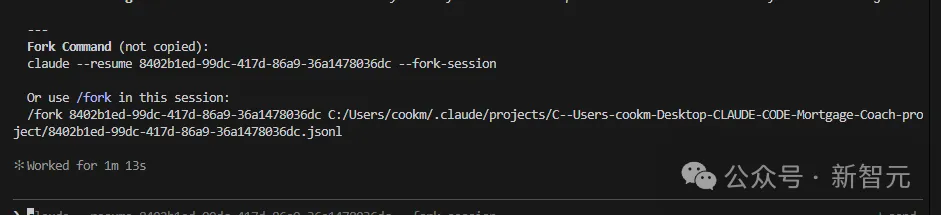
你只需要选一个最合适的会话,它就会直接给你一条fork命令,复制、粘贴到新的终端里。
这样,你就能在最合适的上下文中,无缝继续开发了。功能实现,从此变得异常丝滑!
实测体验:成功率100%
这样看来,Smart Forking,本质上是给大模型外挂了一套「记忆系统」。
当然,如果要严谨一点说,Smart Forking并没有改变模型的记忆机制,而是通过向量检索,把历史上下文变成了一种外置的长期记忆。
不过从使用体验上来说,你不需要重复输入,不用自己回忆,模型就能「想起」你几个月前做过什么,这已经满足人类对「记忆」的全部直觉定义了。
所以可以说,它让Claude拥有了「永久记忆」。
和普通提示相比,成功率到底如何?这种方法适用于哪些使用场景?