谷歌新发现:DeepSeek分裂出多重人格量子位
AI变聪明的真相居然是正在“脑内群聊”?!
谷歌最新研究表明,DeepSeek-R1这类顶尖推理模型在解题时,内部会自发“分裂”出不同性格的虚拟人格,比如外向的、严谨的、多疑的……
大模型的解题推理过程,就是这些人格一场精彩的社交、辩论会;左右脑互搏be like:
“这个思路对吗?试试这样验证……”
“不对,之前的假设忽略了xx条件”
有意思的是,AI还越吵越聪明。
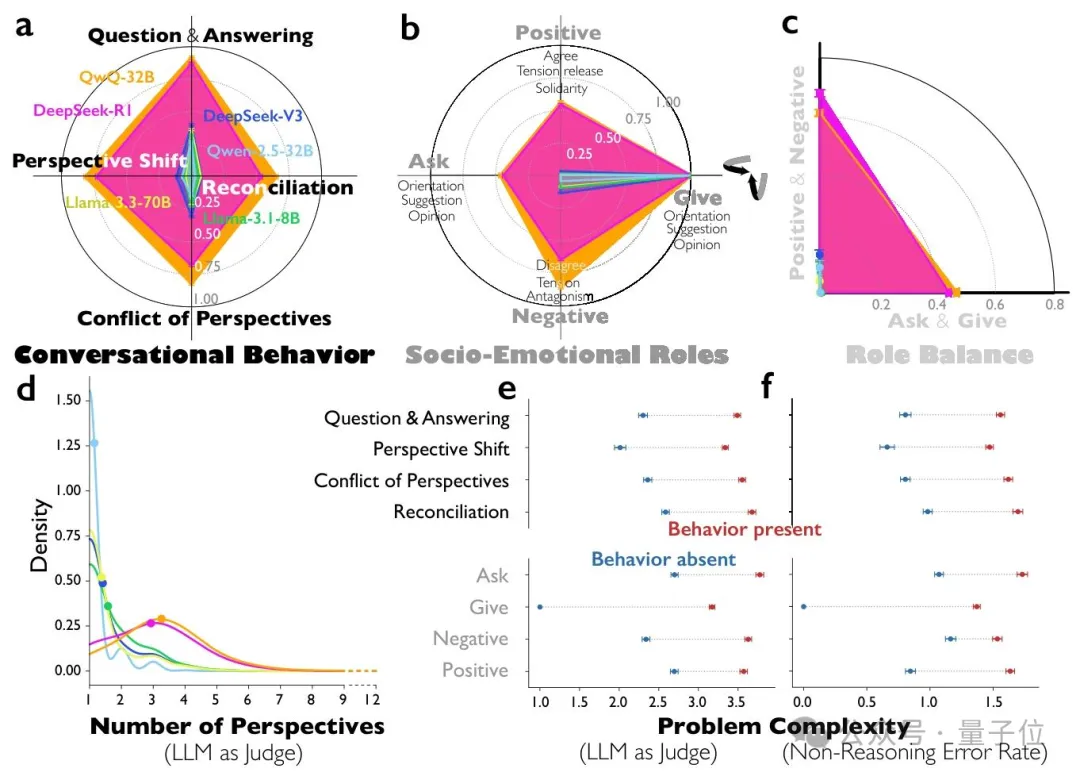
研究发现,当遇到GPQA graduate-level科学问题、复杂数学推导这类高难度任务时,这种内部观点冲突会变得更加激烈。
相比之下,面对布尔表达式、基础逻辑推理等简单任务,模型的脑内对话会明显减少。
模型推理过程就是“左右脑互搏”
团队通过分析DeepSeek-R1和QwQ-32B等模型的思维轨迹发现,它们的推理过程充满了对话感。
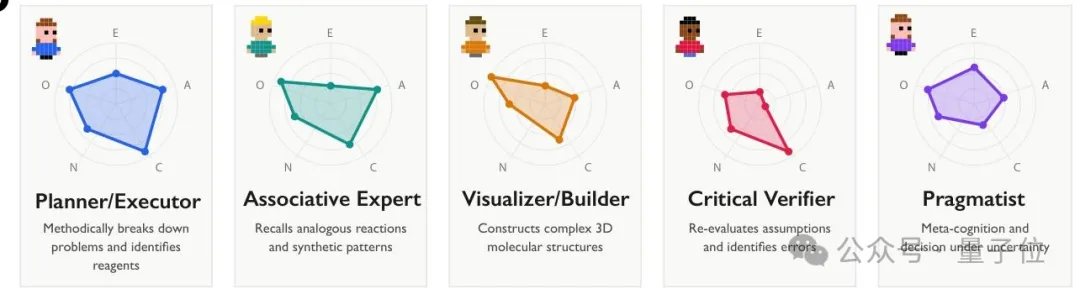
内部分裂出来的虚拟角色不仅性格迥异,还能覆盖更多解题角度。
创意型角色擅长提出新颖思路,批判型角色专注挑错补漏,执行型角色负责落地验证……
通过这些人格的一场交流,不同观点的碰撞能让模型更全面地审视解决方案。
就连网友都说,自己在思考的时候,也会“左右脑互搏”。
不过,这种多角色互动并不是开发人员刻意设计的,而是模型在追求推理准确率的过程中自发形成的。
那么实验是如何证明这一点的呢?
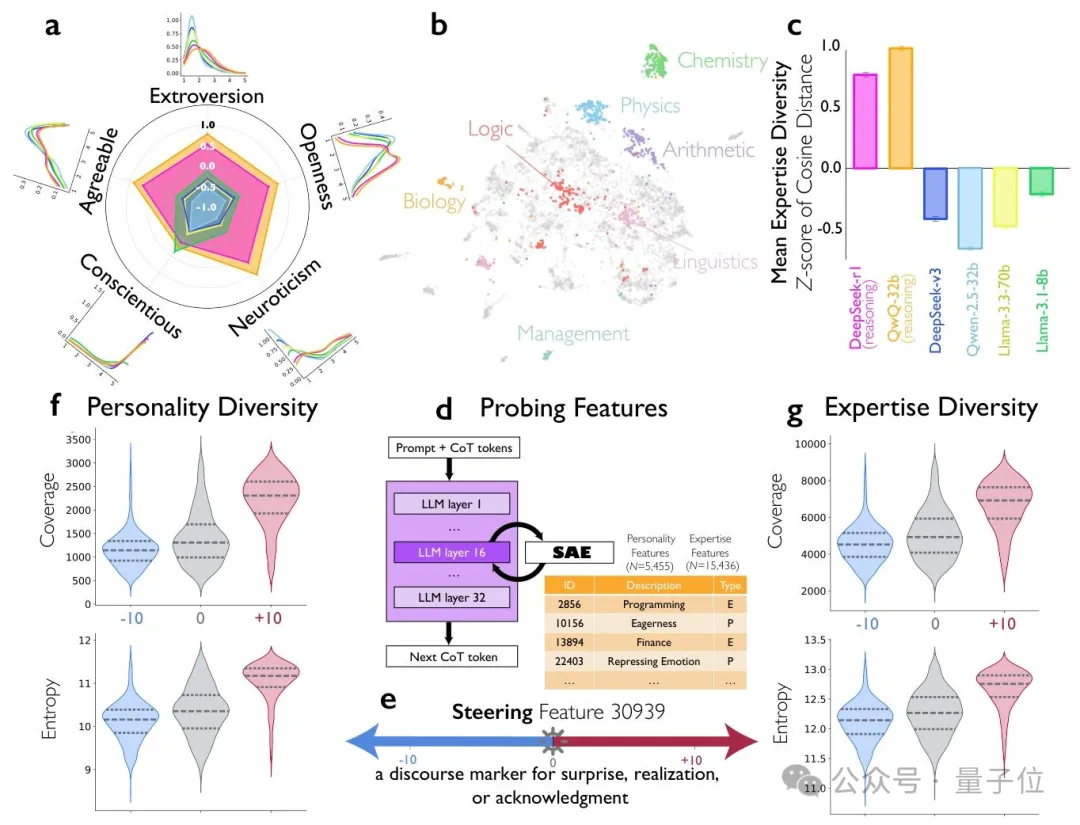
团队借助稀疏自编码器SAE,对AI的推理黑盒进行了深度解码,成功“监听”到了AI的脑内群聊。
首先,研究者让AI执行复杂的数学或逻辑推理任务。在模型产出思维链的同时,团队同步提取其隐藏层神经元的激活数值。
但此时的数据是由数亿个参数构成的复杂非线性信号,无法直接对应任何语义。
将这些激活数据输入SAE,通过SAE的稀疏约束机制,就可以把杂乱的激活拆解为“自问自答”、“切换视角”等独立的对话语义特征;
通过分析这些特征的激活频率以及它们在时间序列上的协同关系,团队成功识别出了不同的内部逻辑实体。
再给上述特征打上“规划者”、“验证者”等虚拟角色的标签,就成功解码了AI内部的多角色对话行为。
“哦!”能让推理更准确
通过对比DeepSeek-R1与DeepSeek-V3、Qwen-2.5-32B-IT这类普通指令模型的推理轨迹,发现推理模型的对话式行为出现的频率显著更高。