David Patterson撰文:推理芯片的四种方案半导体行业观察
David Patterson撰文指出LLM推理瓶颈在于内存与互连而非计算,并四大架构方向:高带宽闪存(HBF),提供10倍容量与HBM级带宽;近内存处理(PNM),优化存算布局;3D内存逻辑堆叠,利用垂直互连实现高能效;以及低延迟互连,加速分布式通信。这些方案旨在解决AI推理面临的效率与成本危机。
日前,由Xiaoyu Ma和David Patterson联合署名的文章《Challenges and Research Directions for Large Language Model Inference Hardware》正式发布。这篇文章被发布以后,引起了广泛关注。文章中,作者围绕LLM推理芯片的挑战以及解决方案,给出了建议。
以下为文章正文:
大型语言模型 (LLM) 推理难度很高。底层 Transformer 模型的自回归解码阶段使得 LLM 推理与训练有着本质区别。受近期人工智能趋势的影响,主要挑战在于内存和互连,而非计算能力。
为了应对这些挑战,我们重点介绍了四个架构研究方向:高带宽闪存,可提供 10 倍内存容量,带宽堪比 HBM;近内存处理和 3D 内存逻辑堆叠,可实现高内存带宽;以及低延迟互连,可加速通信。虽然我们的研究重点是数据中心人工智能,但我们也探讨了这些方案在移动设备上的应用。
当一位作者于 1976 年开始其职业生涯时,计算机体系结构会议上约 40% 的论文来自业界。到 2025 年 ISCA 会议时,这一比例已降至 4% 以下,表明研究与实践之间几乎完全脱节。为了帮助恢复二者之间的历史联系,我们提出了一些研究方向,如果这些方向得以推进,将有助于解决人工智能行业面临的一些最严峻的硬件挑战。
大型语言模型 (LLM) 推理正面临危机。硬件的快速发展推动了人工智能的进步。预计未来 5-8 年,推理芯片的年销售额将增长 4-6 倍。虽然训练展现了人工智能的显著突破,但推理的成本决定了其经济可行性。随着这些模型使用量的急剧增长,企业发现维护最先进的模型成本高昂。
新的趋势使推理变得更加困难。LLM 的最新进展需要更多资源来进行推理:
专家混合模型 (MoE:Mixture of Experts)。与单一的密集前馈模块不同,MoE 使用数十到数百个专家(DeepSeekv3 为 256 个)进行选择性调用。这种稀疏性使得模型规模能够显著增长,从而提高模型质量,尽管训练成本仅略有增加。MoE 在帮助训练的同时,也通过扩展内存和通信能力,加剧了推理过程。
推理模型。推理是一种先思考后行动的技术,旨在提高模型质量。额外的“思考”步骤会在最终答案之前生成一长串“想法”,类似于人们逐步解决问题的过程。思考会显著增加生成延迟,而长长的想法序列也会占用大量内存。
多模态。LLM 已从文本生成发展到图像、音频和视频生成。更大的数据类型比文本生成需要更多的资源。
长上下文。上下文窗口指的是 LLM 模型在生成答案时可以查看的信息量。更长的上下文有助于提高模型质量,但会增加计算和内存需求。
检索增强生成 (RAG:Retrieval-Augmented Generation)。RAG 访问用户特定的知识库,获取相关信息作为额外上下文,以改进 LLM 结果,但这会增加资源需求。
扩散。与顺序生成标记的自回归方法不同,新型扩散方法一步生成所有标记(例如,整幅图像),然后迭代地对图像进行去噪,直至达到所需的质量。与上述方法不同,扩散方法只会增加计算需求。
不断增长的市场和LLM推理面临的挑战表明,创新既是机遇也是需求!
当前LLM推理硬件及其效率低下之处
我们首先回顾LLM推理的基础知识及其在主流AI架构中的主要瓶颈,重点关注数据中心中的LLM。移动设备上的LLM受到不同的限制,因此也需要不同的解决方案(例如,HBM不可行)。
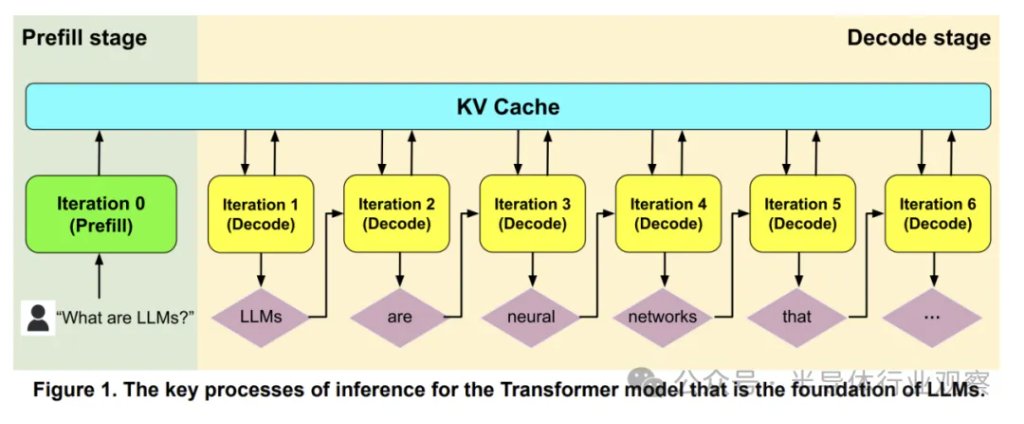
LLM的核心是Transformer,它包含两个特性截然不同的推理阶段:预填充(Prefill)和解码(Decode) (图1)。预填充类似于训练,它同时处理输入序列中的所有标记,因此本质上是并行的,并且通常受限于计算能力。相比之下,解码本质上是顺序的,因为每个步骤都会生成一个输出标记(“自回归:autoregressive”),因此它受限于内存。KV(Key Value)缓存连接这两个阶段,其大小与输入和输出序列的长度成正比。尽管在图1中预填充和解码同时出现,但它们并非紧密耦合,通常运行在不同的服务器上。分解推理允许使用批处理等软件优化方法,从而降低解码过程的内存占用。一项关于高效LLM推理的调查回顾了许多软件优化方法。
GPU 和 TPU 是数据中心常用的加速器,可用于训练和推理。历史上,推理系统通常是在训练系统的基础上缩减而来,例如减少芯片数量或使用内存或性能更低的小型芯片。迄今为止,还没有专门为 LLM 推理设计的 GPU/TPU。由于预填充与训练类似,而解码则截然不同,因此 GPU/TPU 在解码方面面临两个挑战,导致效率低下。
解码挑战 1:内存
自回归解码使得推理本质上受限于内存,而新的软件趋势加剧了这一挑战。相比之下,硬件发展趋势则完全不同。
1.AI 处理器面临着内存瓶颈
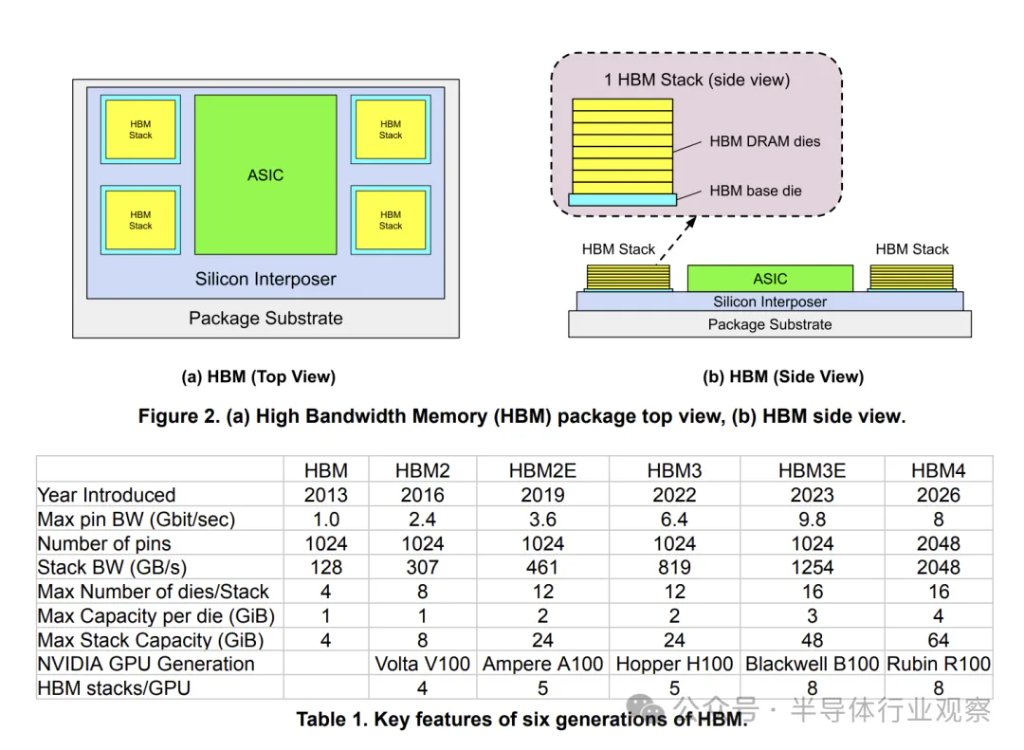
目前的数据中心 GPU/TPU 依赖于高带宽内存 (HBM),并将多个 HBM 堆栈连接到单个单芯片加速器 ASIC(图 2 和表 1)。然而,内存带宽的提升速度远低于计算浮点运算能力 (FLOPS) 的提升速度。例如,NVIDIA 64位GPU的浮点运算性能
从2012年到2022年增长了80倍,但带宽仅增长了17倍。这种差距还将继续扩大。
2.HBM 的成本日益高昂
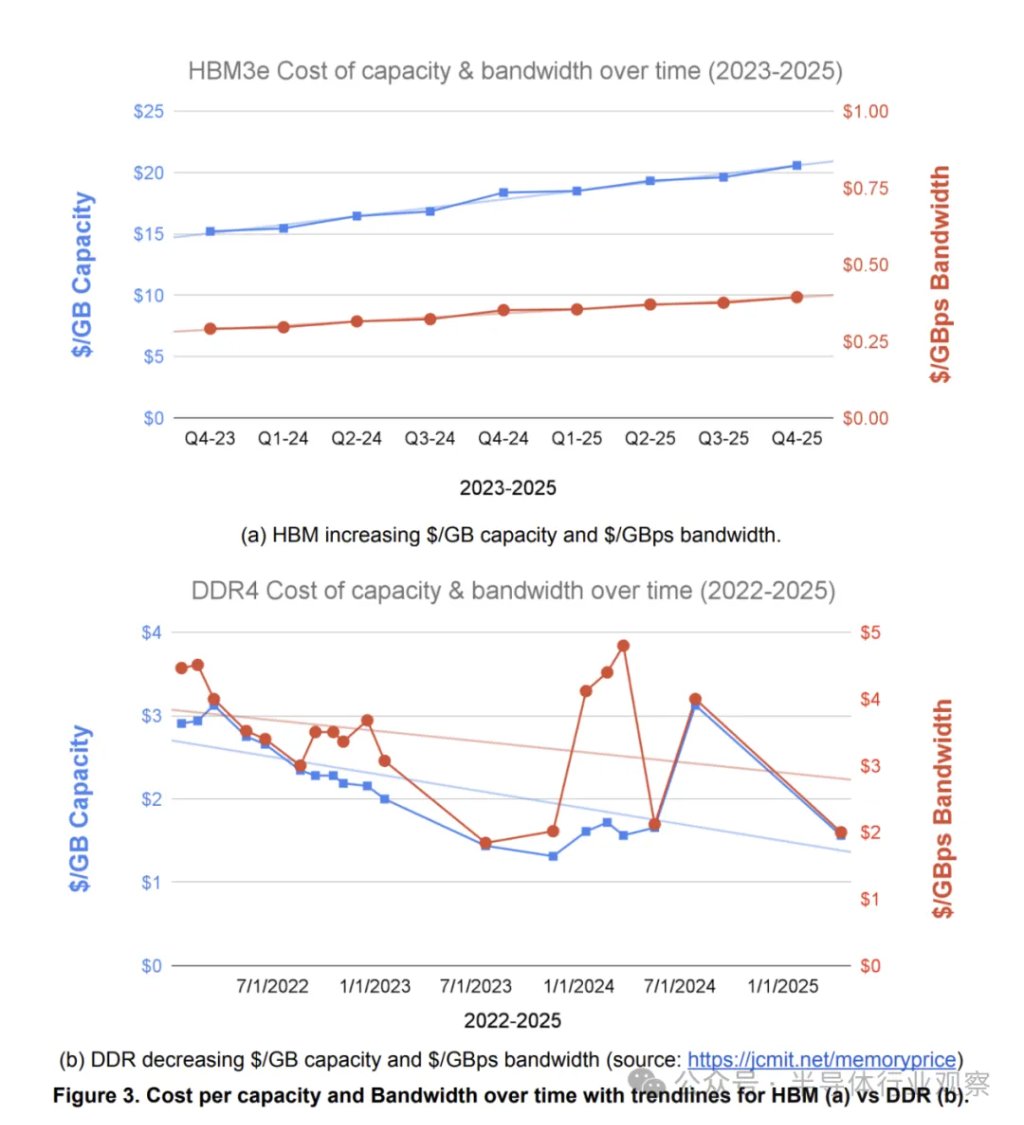
以单个 HBM 堆栈为例,其容量(美元/GB)和带宽(美元/GBps)的标准化价格均随时间推移而上涨。图 3(a) 显示,从 2023 年到 2025 年,两者的价格均增长了 1.35 倍。这一增长是由于随着每个 HBM 堆栈芯片数量的增加以及 DRAM 密度的增长,制造和封装难度也随之增加。相比之下,图 3(b) 显示,标准 DDR4 DRAM 的等效成本随时间推移而下降。从 2022 年到 2025 年,容量成本降至 0.54 倍,带宽成本降至 0.45 倍。尽管由于意外的需求,所有内存和存储设备的价格在 2026 年大幅上涨,但我们认为,从长远来看,HBM 和 DRAM 价格走势的分化趋势将持续下去。
3.DRAM 密度增长正在放缓
对于单个 DRAM 芯片而言,其扩展性也令人担忧。自2014年推出的8Gb DRAM芯片以来,实现四倍增长需要超过10年的时间。此前,四倍增长通常每3-6年发生一次。
4.仅使用SRAM的解决方案已不足以应对挑战
Cerebras和Groq曾尝试使用填充SRAM的全光罩芯片来规避DRAM和HBM的挑战。(Cerebras甚至采用了晶圆级集成。)虽然在公司十年前成立时这种方案看似可行,但LLM很快就超过了芯片上SRAM的容量。两家公司后来都不得不进行改造,加装外部DRAM。