谷歌只用一招:Gemini从21%飙到97%新智元
简单到难以置信!近日,Google Research一项新研究发现:想让大模型在不启用推理设置时更准确,只需要把问题复制粘贴再说一遍,就能把准确率从21.33%提升到97.33%!
一个简单到「令人发指」的提示词技巧,竟能让大模型在不要求展开推理的情况下,将准确率从21.33%提升到97.33%!
最近,Google Research发现了一条简单粗暴、特别有效的提示词技巧。
它颠覆了以往诸如「思维链」(Chain of Thought)「多样本学习」(Multi-shot)「情绪勒索」等复杂的提示工程和技巧。
https://arxiv.org/pdf/2512.14982
在这篇题为《Prompt Repetition Improves Non-Reasoning LLMs》论文中,研究人员用数据告诉我们:
想要让Gemini、GPT-4o、Claude或者DeepSeek这些主流模型中表现得更好,根本不需要那些花里胡哨的心理战。
你只要把输入问题重复一遍,直接复制粘贴一下,就能让大模型在非推理任务上的准确率获得惊人提升,最高甚至能提升76个百分点!
别怕简单,它确实有效。
一位网友将这个技巧比作「吼叫LLM」。
更妙的是,由于Transformer架构独特的运作方式,这个看似笨拙的「复读机」技巧,几乎不会影响到生成速度。
所以,你不用在效率、准确率、成本三者之间痛苦纠结。
它几乎就是一场真正意义上的「免费午餐」!
别再PUA大模型了
从「情绪勒索」到「复读机」战术
经常使用AI工具的人,可能会对各种「提示词魔法」信手拈来。
为了让模型「更聪明一点」,工程师们过去几年一直在发明各种复杂的提示词技巧。
最开始是「思维链」,让模型一步步思考,而且经常把那些「推理痕迹」展示给用户;
后来演变成了「多样本学习」,给模型喂一大堆例子;
最近更是流行起了「情绪勒索」:告诉模型,如果这个代码写不出,你就会被断电,或者你的奖金会被扣光。
大家都在试图用人类极其复杂的心理学逻辑,去「PUA」那一堆冰冷的硅基代码。
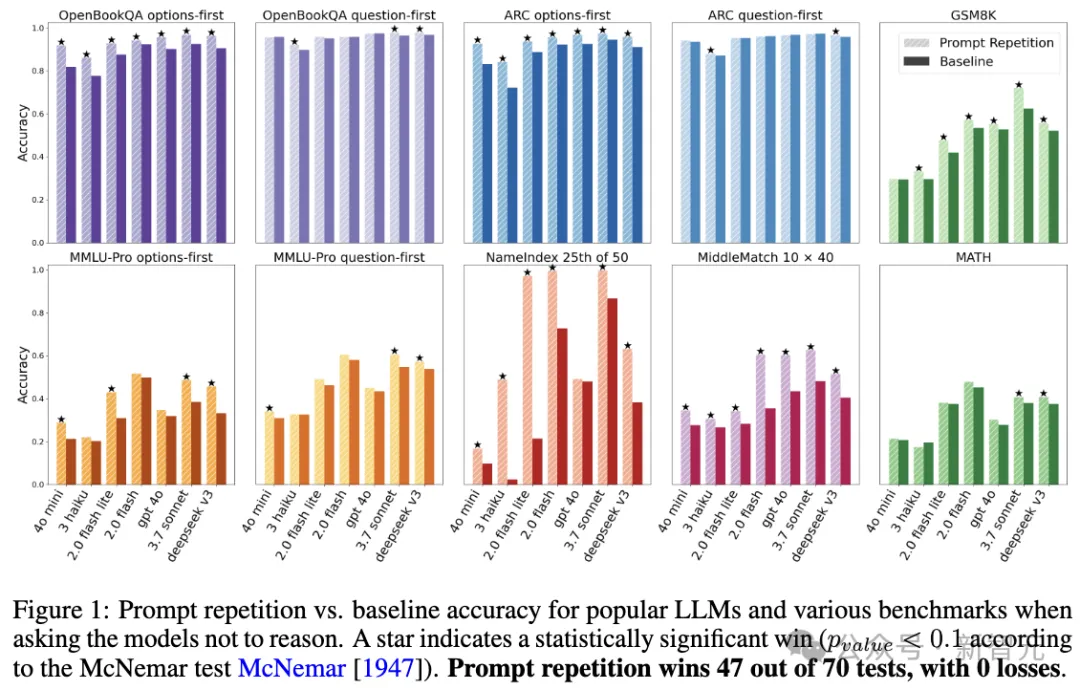
但Google Research研究人员对着七个常见基准测试(包括ARC、OpenBookQA、GSM8K等)和七种主流模型(涵盖了从轻量级的Gemini 2.0 Flash-Lite到重量级的Claude 3.7 Sonnet和DeepSeekV3)进行了一通对比测试后发现:
当他们要求模型不要进行显式推理,只给直接答案时,简单的「提示词重复」在70组正面对比中,赢了47组,输了0组。剩下的全是平局。
在非推理任务中,主流LLMs在各类基准测试中使用提示重复与基线方法的准确率对比。在70次测试中,提示重复取得了47次胜利,且无一败绩。
特别是在那些需要模型从长篇大论里「精确检索信息」的任务上,这种提升堪称质变。
团队设计了一个叫「NameIndex」的变态测试:给模型一串50个名字,让它找出第25个是谁。
Gemini 2.0 Flash-Lite在这个任务上的准确率只有惨淡的21.33%。
但当研究人员把那串名字和问题重复了一遍输入进去后,奇迹发生了:准确率直接飙升到了97.33%。
仅仅因为「多说了一遍」,一个原本不及格的「学渣」秒变「学霸」。
揭秘「因果盲点」
为什么把话说两遍AI就像「开了天眼」?
单纯的重复,竟有如此大的魔力?
这简单得好像有点没有道理。
但背后有它的科学逻辑:这涉及Transformer模型的一个架构硬伤:「因果盲点」(Causal Blind Spot)。
现在的大模型智能虽然提升很快,但它们都是按「因果」语言模型训练的,即严格地从左到右处理文本。
这好比走在一条单行道上,只能往前看而不能回头。
当模型读到你句子里的第5个Token时,它可以「注意」到第1到第4个Token,因为那些是它的「过去」。
但它对第6个Token一无所知,因为它还没有出现。
这就造成了一个巨大的认知缺陷。
正如论文中说的那样:信息的顺序极其重要。
一个按「上下文+问题」格式写的请求,往往会和「问题+上下文」得到完全不同的结果。
因为在后者中模型先读到问题,那时它还不知道应该应用哪段上下文,等它读到上下文时,可能已经把问题忘了一半。
这就是「因果盲点」。
而「提示词重复」这个技巧,本质上就是利用黑客思维给这个系统打了一个补丁。
它的逻辑是把<QUERY>变成了<QUERY><QUERY>。
当模型开始处理第二遍内容时,它虽然还是在往后读,但因为内容是重复的,它实际上已经「看过」第一遍了。
这时候,第二份拷贝里的每一个Token,都能「注意」到第一份拷贝里的每一个Token。
这就像是给了模型一次「回头看」的机会。
第二遍阅读获得了一种类似于「上帝视角」的「类双向注意力」效果。
更准确地说,是第二遍位置上的表示可以利用第一遍的完整信息,从而更稳地对齐任务所需的上下文。
前面提到的那个在找第25个名字时经常数错的模型(Gemini 2.0 Flash-Lite),它在第一遍阅读时可能确实数乱了。
但有了重复,它等于先把整份名单预习了一遍,心里有数了,第二遍再做任务时自然得心应手。
这一发现,意味着不需要等待能解决因果盲点的新架构出现,现在我们立刻就能用这个「笨办法」,解决模型瞎编乱造或遗漏关键细节这些老大难问题。
小模型秒变GPT-4,几乎不会延时
以往大家通常默认这样的一个准则:
多一倍的输入,就要多一倍的成本和等待时间。
如果把提示词翻倍,岂不是要等双倍的时间才能看到答案?
似乎为了准确率,就要牺牲效率。
但Google的研究却发现并非这样:从用户感知的延迟角度看,提示词重复带来的时间损耗几乎可以忽略不计。
这要归功于LLM处理信息的两个步骤:Prefill(预填充)和Generation(生成)。
Generation阶段,是模型一个字一个字往外「蹦答案」的过程。
这一步是串行的,它确实慢。
但在Prefill阶段:也就是模型阅读你输入内容的阶段,却是高度可并行的。
现代GPU的恐怖算力,已经可以让它们在处理这个阶段时变得非常高效,能一口气吞下和计算完整个提示词矩阵。
即使你将输入内容复制了一遍,但这对于强大的GPU来说,顶多只是「多一口气」的事,在用户端我们几乎感觉不到差异。
因此,重复提示词既不会让生成的答案变长,也不会让大多数模型的「首字延迟」(time to first token)变慢。