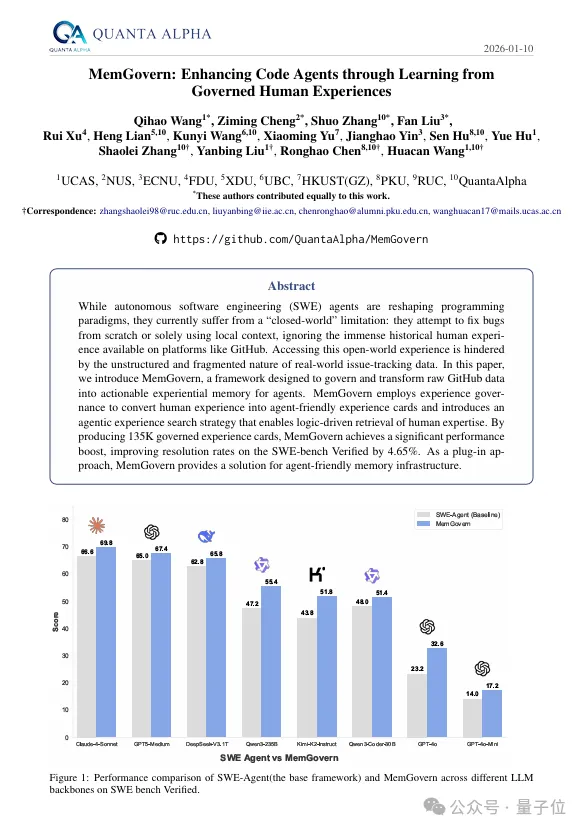
开源框架让代码AI偷师GitHub:飙升69.8%量子位
人类程序员碰到棘手bug通常会上网查询前辈经验。
当前AI虽然开始具备联网搜索能力,但仍不能很好地从网络经验中获取修复bug的能力。
让AI学习人类程序员的工作流程或许有助于其提升bug修复能力,名为MemGovern的项目团队在此思路下做出的尝试近期得到了良好的效果。
在自动化软件工程(SWE)领域,大语言模型驱动的代码智能体(Code Agents)虽然在编程范式上带来了变革,但它们目前普遍面临“封闭世界”的认知局限:
现有的智能体往往试图从零开始修复Bug,或者仅依赖仓库内的局部上下文,而忽略了GitHub等平台上积累的浩瀚历史人类经验。
事实上,人类工程师在解决复杂问题时,往往会搜索开源社区,借鉴相似问题的历史解决方案。
然而,直接让智能体利用这些“开放世界”的经验极具挑战,因为真实的Issue和Pull Request(PR)数据充斥着非结构化的社交噪音、模棱两可的描述以及碎片化的信息。
为了突破这一壁垒,前沿开源学术社区QuantaAlpha联合中国科学院大学(UCAS)、新加坡国立大学(NUS)、北京大学(PKU)、华东师范大学(ECNU)等团队提出了MemGovern框架。
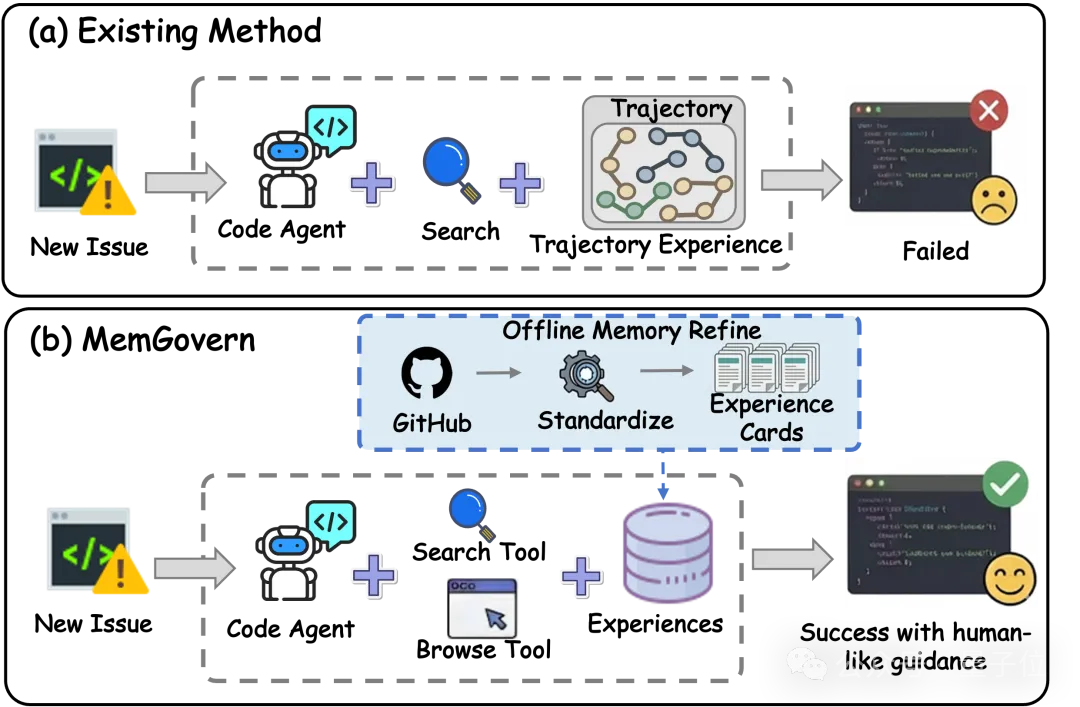
该框架并未采用简单的检索增强(RAG)路径,而是提出了一套完整的“经验精炼”机制,将杂乱的GitHub数据转化为智能体友好的结构化记忆,并结合了Deep Research的思想提出了“Experiential Memory Search”策略,实现了从历史经验中提取可复用修复逻辑的闭环。
核心痛点:海量数据≠可用知识
现有的Code Agent(如SWE-Agent)在处理复杂Bug时,往往陷入“不知所措”的境地,因为它们缺乏历史记忆。虽然GitHub是一个巨大的宝库,但直接把Issue和PR丢给AI效果并不好,原因在于:
1.噪声极大:
原始讨论中充斥着“感谢”、“合并请求”等无关社交用语。
2.非结构化:
不同项目的日志、报错信息和修复逻辑混杂在一起,缺乏统一格式。
3.难以检索:
简单的语义匹配容易被表面关键词误导,无法触达深层的修复逻辑。
MemGovern的出现,就是为了把这些“原始数据”变成AI真正能用的“经验卡片”。
经验精炼机制(Experience Refinement Mechanism)
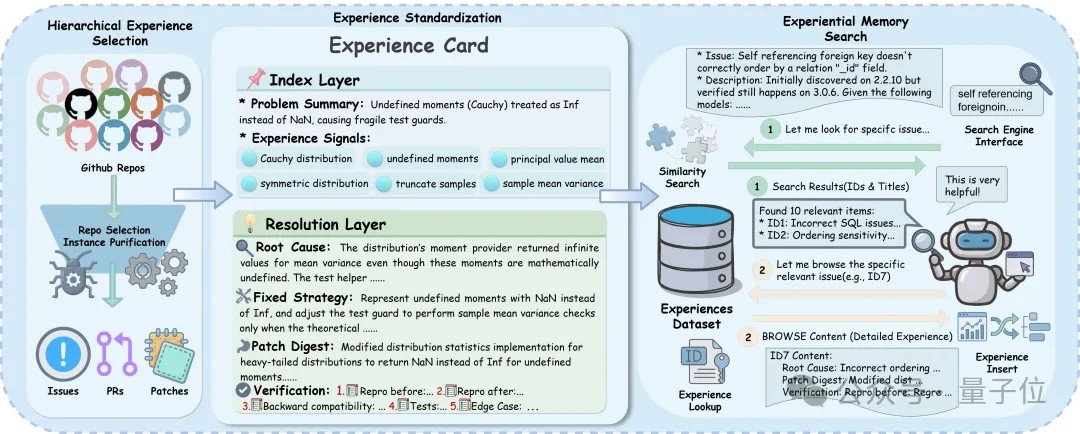
MemGovern并没有直接将原始的GitHub Issue和PR扔给智能体,而是构建了一套层次化的筛选与内容净化流水线。
层次化选择(Hierarchical Selection):首先,通过综合考量Star数与维护活跃度(Issue/PR频率),筛选出高质量的仓库源;随后,在实例层面进行严格清洗,仅保留包含完整证据链(问题-代码-验证)的“闭环”修复记录。
标准化经验卡片(Experience Card):这是MemGovern的独创设计。原始记录被重构为标准化的经验卡片,每张卡片被显式地解耦为两层:
索引层(Index Layer,):包含标准化的问题摘要与关键诊断信号(如异常类型、错误签名),用于基于症状的高效检索。
决议层(Resolution Layer,):封装了根因分析(Root Cause)、修复策略(Fix Strategy)、补丁摘要(Patch Digest)以及验证方法(Verification)。
这种结构化设计有效解决了检索信号与推理逻辑混淆的问题,显著提升了知识的可用性。目前,团队已成功构建了包含135,000条高保真经验卡片的知识库。
代理式经验搜索(Agentic Experience Search):像人类一样“搜索-浏览”文档传统的RAG(检索增强生成)往往是一次性把检索结果塞给模型,容易导致上下文超长且充满噪声。MemGovern采用了更符合人类直觉的Search-then-Browse(先搜后看)模式:
Searching(搜索)
智能体首先根据当前Bug的症状(如报错堆栈)在索引层进行广度搜索,快速定位可能相关的候选案例。
Browsing(浏览)
智能体自主选择最有希望的案例,查看其详细的“解决方案层”。这种机制允许智能体深入理解修复逻辑,排除无关干扰。