感谢AI:视频压缩到了0.02%量子位
原生1个G的视频,现在只需要传200K数据就能看了——
视频数据的压缩率干到了0.02%,但依旧能保持画面的高清、连贯和画面细节。
或许你会问,这又有什么用呢?
想象一下,你身处于太平洋的一搜远洋货轮中,卫星信号只有一两格,刷个朋友圈,加载内容的圈圈都要转好久。
但正是因为有了这项AI技术,现在在如此极端的环境之下,你甚至可以直接看高清的世界杯直播!
没错,视频传输的物理法则,算是被重写了。
而这项新研究,正是来自中国电信人工智能研究院(TeleAI)的技术——生成式视频压缩(GVC,Generative Video Compression)。
作为国资央企、全球领先的综合智能信息服务运营商,中国电信不仅拥有覆盖海陆空天的通信网络基础设施,更具备将前沿AI技术与实际通信场景深度融合的能力。
这种“云网融合+AI原生”的独特优势,使得GVC技术从实验室走向远洋船舶、应急现场等真实极端环境成为可能。
那么这项研究到底是如何做到的,以及又能给我们现实生活带来什么改变,我们继续往下看。
用计算,换宽带
在介绍这项黑科技之前,我们需得先聊聊现在的视频是怎么传输的。
无论是你要看的Netflix、B站,还是微信视频通话,背后主要依靠的是HEVC(H.265)或VVC(H.266)这类传统视频编码标准。
这些技术的底层逻辑,说白了是像素的极致搬运:编码器拼命计算哪些像素是不变的、哪些是移动的,然后尽可能多地保留像素信息,再想办法塞进有限的带宽里。
这种逻辑在宽带富裕时很完美,但在极限环境下(极低带宽)会迅速崩盘。
一旦带宽不够,传统编码器为了凑合传输,只能疯狂丢弃高频信息。结果我们都见过:画面糊成一团,甚至直接卡死。
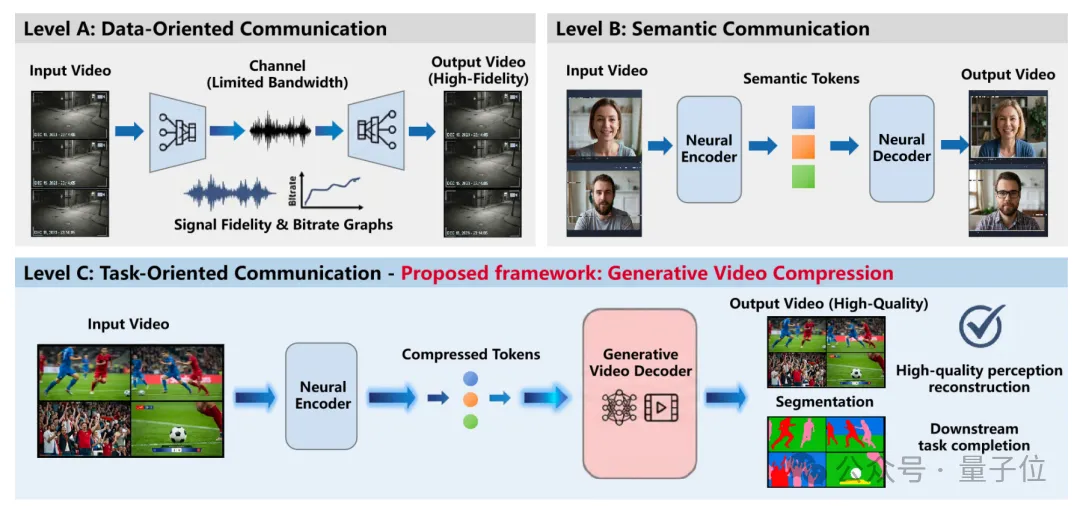
但 TeleAI 团队换了个思路,如果我不传像素了呢?
GVC的核心逻辑是:不再传递画面本身,而是传递“如何画出这幅画面”的指令。
传统压缩:就像是把《蒙娜丽莎》拍一张照片,尽量压缩这张照片发给你。如果网不好,照片就糊得像一堆色块。
生成式视频压缩(GVC):我不发照片了。我发给你一段描述——“一位女士,神秘微笑,背景是山水,光影是从左侧来的……”,以及她嘴角上扬的精确弧度数据。你的接收端坐着一位AI画师(生成式模型),听到描述后,现场给你画出一幅《蒙娜丽莎》。
刚刚说的只是打个比方,实际情况要复杂得多,传输的内容也并非只有文字。
这就是技术报告中提到的核心理念:用计算,换宽带(Trading computation for bandwidth)。
把传输的压力,转移到了推理计算上。
GVC到底压了些什么?
既然不传像素,那这0.02%的数据里到底装了什么?
技术报告揭示了GVC系统的内部构造,它主要由神经编码器(Neural Encoder)和生成式视频解码器(Generative Video Decoder)两部分组成。
里面传输的是一种被称为压缩Token 的极小数据包,这些Token里包含了视频的灵魂,主要分为两类:
语义信息(Semantic Information): 这是一个什么场景?有人吗?有车吗?物体的大致结构是什么?这是画面的骨架。
运动信息(Motion Dynamics): 这些物体下一秒往哪动?风怎么吹?车轮怎么转?这是画面的灵魂。
经过 TeleAI 团队的测试,这些Token的大小可以被压缩到极致的0.005 bpp - 0.008 bpp(bits per pixel,比特每像素)。
这是什么概念?通常我们看的高清视频,bpp至少在0.1以上。GVC直接把数据量砍掉了两个数量级。
除此之外,在接收端,还有一个扩散模型(Diffusion Model) 严阵以待。
它接收到这些简短的Token指令后,利用预训练好的海量世界知识(比如它本来就知道海浪长什么样,足球长什么样),结合指令中的特征,开始脑补并生成视频。
这在通信理论上,实现了一次巨大的跨越。
香农-韦弗(Shannon-Weaver)通信模型将通信分为三个层级:
Level A:技术问题(传得准不准?)
Level B:语义问题(意思对不对?)
Level C:有效性问题(能不能完成任务?)
传统视频压缩在死磕Level A,而GVC直接跳到了Level C。
它不在乎每一个像素点是否和原图一模一样(比如这片树叶的纹理是否100%重合),它在乎的是:在人眼看来,这是否是一场连贯、清晰、真实的球赛?在机器看来,能否准确识别出这是否是越位?
数据实测:非常省流
极端压缩听起来很玄,但具体指标并不含糊。
技术报告中展示了在MCL-JCV权威数据集上的测试结果,数据非常硬核。
画质吊打传统算法
在极低码率下(0.005 bpp左右),使用LPIPS(一种更符合人类视觉感知的画质评价指标)进行对比:
传统霸主HEVC已经彻底崩溃,画面基本是马赛克乱舞,LPIPS数值飙升(越低越好)。
GVC生成的画面依然保持了清晰的纹理和结构,LPIPS数值显著低于HEVC。
技术报告中给出了一个惊人的对比结论:传统方法(如HEVC)要想达到和GVC同样的视觉画质,需要消耗6倍以上的带宽!
这意味着,在同样的渣画质网络下,GVC能让你看清C罗的表情,而HEVC只能让你看清C罗是个移动的色块。
不只是给人看,机器也能用
有人会问:AI生成的视频,会不会失真?比如把球生成没了?
这是一个非常犀利且实在的问题。