AI精准编辑门槛大降:开源框架,即插即用量子位
想给照片里的猫换个颜色,结果总是编辑失败?想让视频里的人换件衣服,人脸却糊成一片或完全改变?
在AI视觉编辑领域,如何在修改目标属性的同时,精准保留背景和非编辑属性的一致性,一直是个“鱼和熊掌”的难题。
近日,来自中山大学iSEE实验室、香港中文大学MM Lab、新加坡南洋理工大学、香港大学的研究团队发布了最新研究成果ProEdit。
该方法通过对注意力机制和初始噪声潜在分布的“精准手术”,实现了超高精度的图像与视频编辑,且完全无需训练、即插即用。
△ 图1. ProEdit在图像和视频编辑上与现有方法的对比
为什么AI编辑总是“改不动”?
目前,基于反演(Inversion-based)的编辑方法(如RF-Solver、FireFlow)通常采用全局注入策略:为了保持背景尽量一致,它们会将原图的大量信息强行“塞”进生成过程。
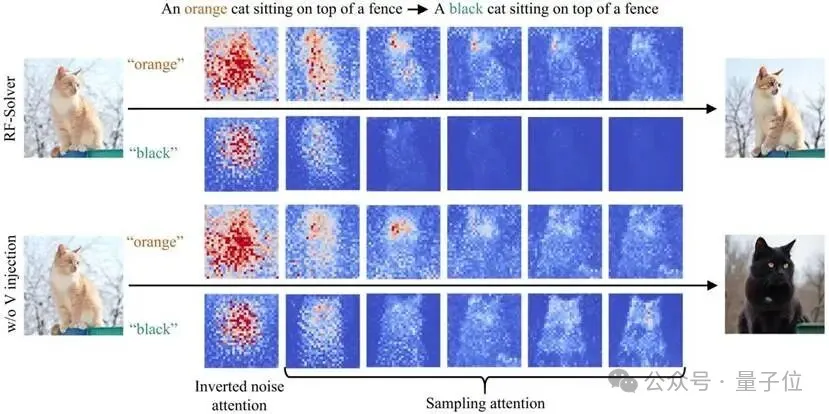
但研究团队通过文本与图像的注意力可视化发现,这种做法存在严重的“源图像信息过度注入”问题:
注意力过度注入:
现有方法通过全局注入了过多的源图像注意力特征,导致模型更听源图像的话,而忽略了用户的编辑指令(Prompt)。
潜在空间锁死:
反演后的初始噪声中残留了太强的源图像分布信息,使得模型倾向于“重建”原图,而不是“编辑”新图。
结果就是:现有方法下,你想把“橙色猫”改写成“黑色猫”,AI可能还是给你一只橙色猫。而去除源图像注意力注入机制,又难以保持背景和非编辑属性的一致性。
△ 图2. 现有方法与去除注意力注入下的注意力可视化与编辑效果
ProEdit两把精准的“手术刀”
为了破解上述难题,ProEdit提出了两个核心模块,从两个维度消除源图像信息的干扰:
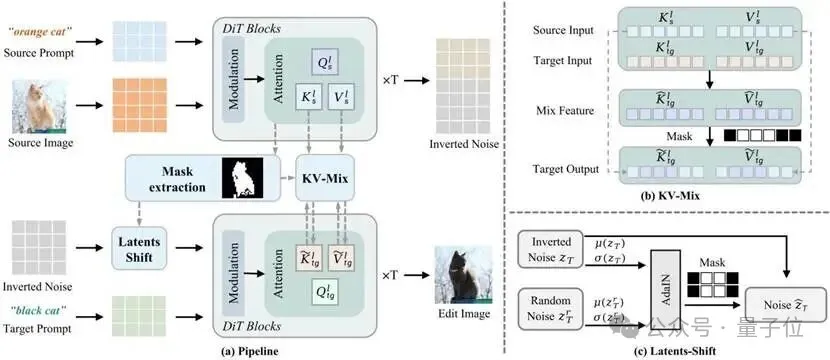
△ 图3. ProEdit方法概览。
包含KV-Mix和Latents-Shift两个核心模块与总体流程
1. KV-Mix:注意力层面的“混合注入机制”
注意力注入机制对于保持背景一致性至关重要,但ProEdit不再盲目进行全局注入,而是通过注意力图(Attention Map)提取出掩码(Mask),以识别出“编辑区”和“非编辑区”。
非编辑区:全量注入原图的K(Key)和V(Value)注意力特征,保证背景的一致性。
编辑区:将原图与目标的K(Key)和V(Value)注意力特征按比例混合。这种“混合”机制让模型既能按照编辑指令(Prompt)进行编辑,又能参考原图的结构,实现平滑过渡。
2. Latents-Shift:潜变量空间的“分布偏移”
受风格迁移算法AdaIN的启发,ProEdit引入了Latents-Shift模块。
它在编辑区域通过引入高斯噪声,对反演后的初始噪声(Inverted Noise)进行分布的统计量偏移,从而消除了源图像分布对初始噪声分布的过度影响。
效果:彻底打破源图像对编辑图像属性的“紧箍咒”,让颜色、姿态、数量等属性修改变得轻而易举。
精准编辑,背景一致
通过上述流程,ProEdit能够遵循编辑指令,实现精准、背景一致的编辑。
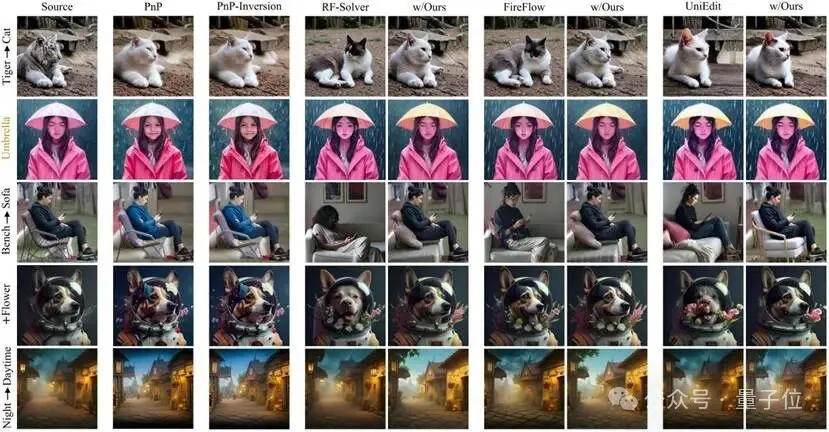
△ 图4. ProEdit图像编辑效果对比。
ProEdit可以即插即用到现有的Solver当中提升编辑效果
与现有基于反演的编辑方法对比,ProEdit在以下方面表现出了显著优势:
背景一致性:
精确的掩码(Mask)分离出了非编辑区域,确保了在修改目标属性时背景的一致性。
非编辑属性的一致性:
在编辑某个特定属性时(如颜色)时,其他属性(如物体的姿态、纹理特征)能够保持一致性。
编辑精准度与指令遵循度:
在图像和视频编辑中均实现了更彻底、更精准的属性转换。
△ 图5. ProEdit编辑视频效果展示
战绩斐然:全线SOTA,即插即用
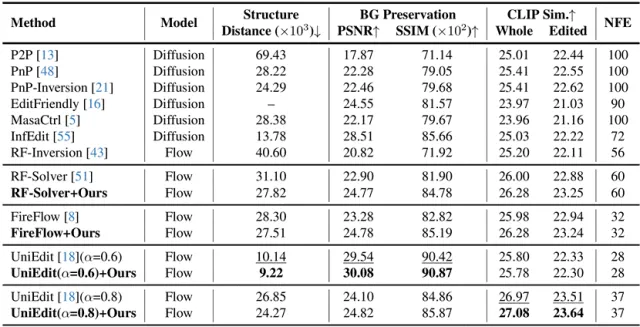
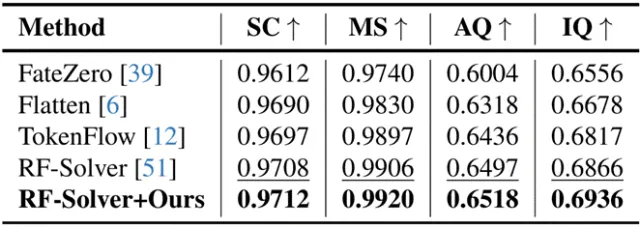
为了科学评估ProEdit在图像/视频的编辑质量,研究团队在PIE-Bench上进行了图像编辑实验,在互联网视频组成的视频编辑数据上进行了视频编辑实验。
△ 表1. PIE-Bench上的图像编辑实验结果
△ 表2. 互联网视频数据上的视频编辑实验结果