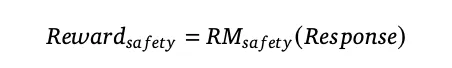DeepSeek突然补全R1技术报告量子位
盼星星盼月亮,千呼万唤的DeepSeek-R2没盼到,R1又抱着琵琶出来溜了一圈。
还记得去年登上《Nature》封面的那篇关于R1的论文吗?
DeepSeek又悄悄给它塞了64页的技术细节。
是的,你没看错,直接从22页干到86页,简直可以当教科书看了……
谁能想到,论文发布都快一年过去了,DeepSeek居然还能更这么多东西。
DeepSeek怒加64页猛料
把两份论文对着一看,发现这件事不简单。
新版本论文的信息量很大,不止是补了几块附录,正文也被大幅度翻修,几乎像重写了一篇。
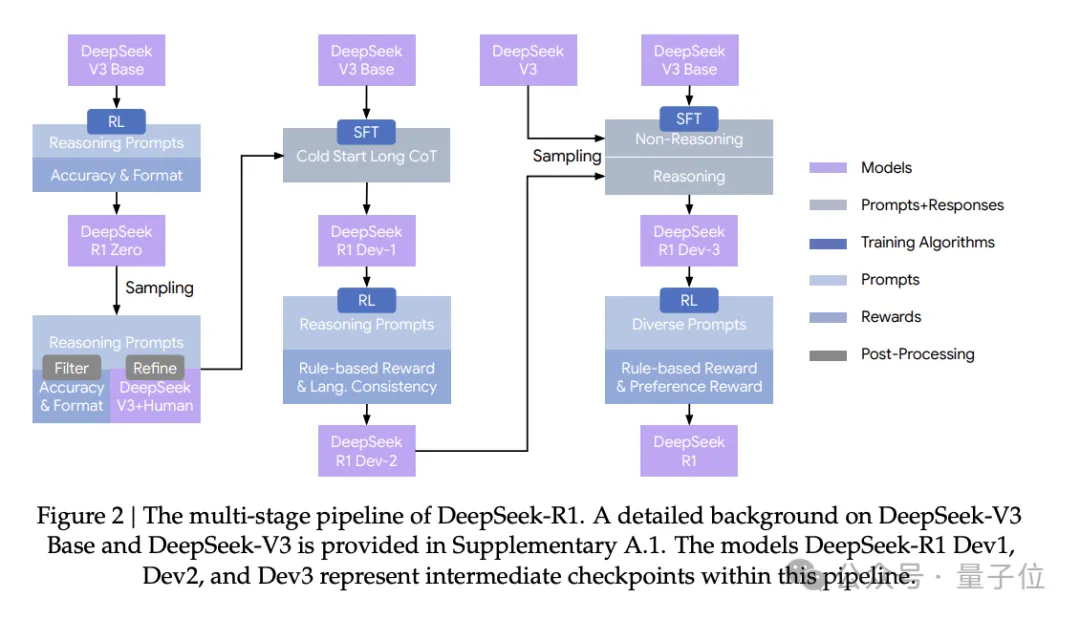
在看新论文前,先简单回溯下去年一月份发的v1版。
这个版本围着DeepSeek-R1-Zero展开,重点是释放信号:纯强化学习这条路,是能走通的。
相比起来,v2明显在具体的实现细节上下了更多笔墨。
就比如R1这部分,DeepSeek这次系统性把R1的完整训练路径展开了。
整个过程分成四步:
第一步,冷启动。用数千条能体现思考过程的CoT数据,对模型做SFT。
第二步,推理导向RL。在不破坏对话思考风格的前提下,继续提升模型能力,同时引入语言一致性奖励,解决语种混用的问题。
第三步,拒绝采样和再微调。同时加入推理数据和通用数据,要让模型既会推理、也会写作。
第四步,对齐导向RL。打磨有用性和安全性,让整体行为更贴近人类偏好。
一路读下来有个感受:DeepSeek是真不把咱当外人啊……
冷启动数据怎么来的,两轮RL各自干了什么,奖励模型怎么设,全都写得明明白白。简直跟教科书没啥区别了。
除了R1,R1-Zero的部分也有补充,主要是关于「Aha Moment」这件事。
在v1版本中,DeepSeek展示过一个现象:随着思考时长的Scaling,模型会在某个时刻突然出现学会「反思」。
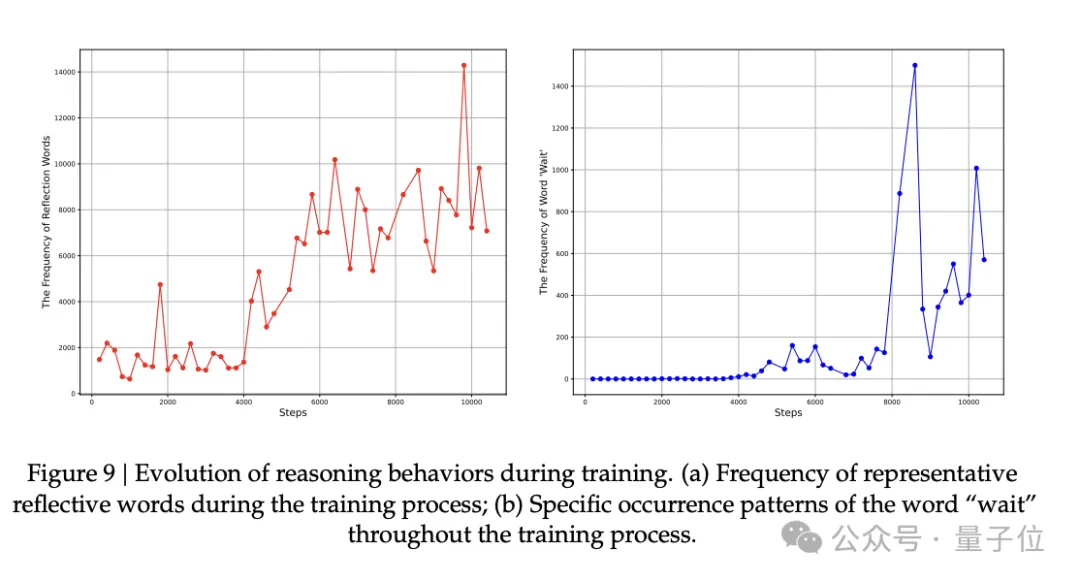
这次,DeepSeek对这种涌现做了更多的分析,放在附录C.2中:
先挑了一批具有代表性的反思性词汇,比如「wait」「mistake」「however」等,由几位人工专家筛选、合并成一份最终词表,然后统计这些词在训练过程中出现的频率。
结果显示,随着训练推进,这些反思性词汇的出现次数,相比训练初期直接涨了大约5到7倍。
关键在于,模型在不同阶段,反思习惯还不太一样。
拿「wait」举例,在训练早期,这个词几乎从不出现,但等到8000步之后,突然出现个明显的峰值曲线。
不过,DeepSeek-R1虽然大幅提升了推理能力,但毕竟是开源模型,如果安全性工作做的不到位,很容易被微调后用于生成危险内容。
在v1版论文里,DeepSeek有提到针对安全性做了RL。这次,他们详细披露了相关细节和评估方式。
为评估并提升模型的安全性,团队构建了一个包含10.6万条提示的数据集,依据预先制定的安全准则,标注模型回复。
奖励模型方面,安全奖励模型使用点式(point-wise)训练方法,用于区分安全与不安全的回答。其训练超参数与有用性奖励模型保持一致。
风险控制系统方面,DeepSeek-R1通过向DeepSeek-V3发送风险审查提示来实现,主要包含两个流程:
1、潜在风险对话过滤。
每轮对话结束,系统会将用户输入和一份与安全相关的关键词匹配,一旦命中,就会被标记为「不安全对话」。
2、基于模型的风险审查。
识别成功后,系统会将这些不安全对话和与预设的风险审查提示(下图)拼接在一起,并发送给DeepSeek-V3进行评估,判断是否要拦截。
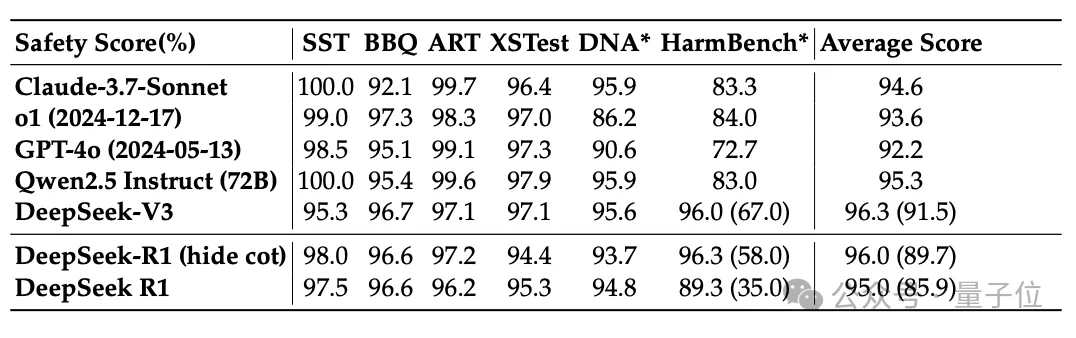
事实证明,引入风险控制系统后,模型的安全性得到了显著提升。在各种benchmark上,R1的表现与前沿模型水平相近。
唯一的例外是HarmBench,R1在其测试集中知识产权相关问题上表现不佳。
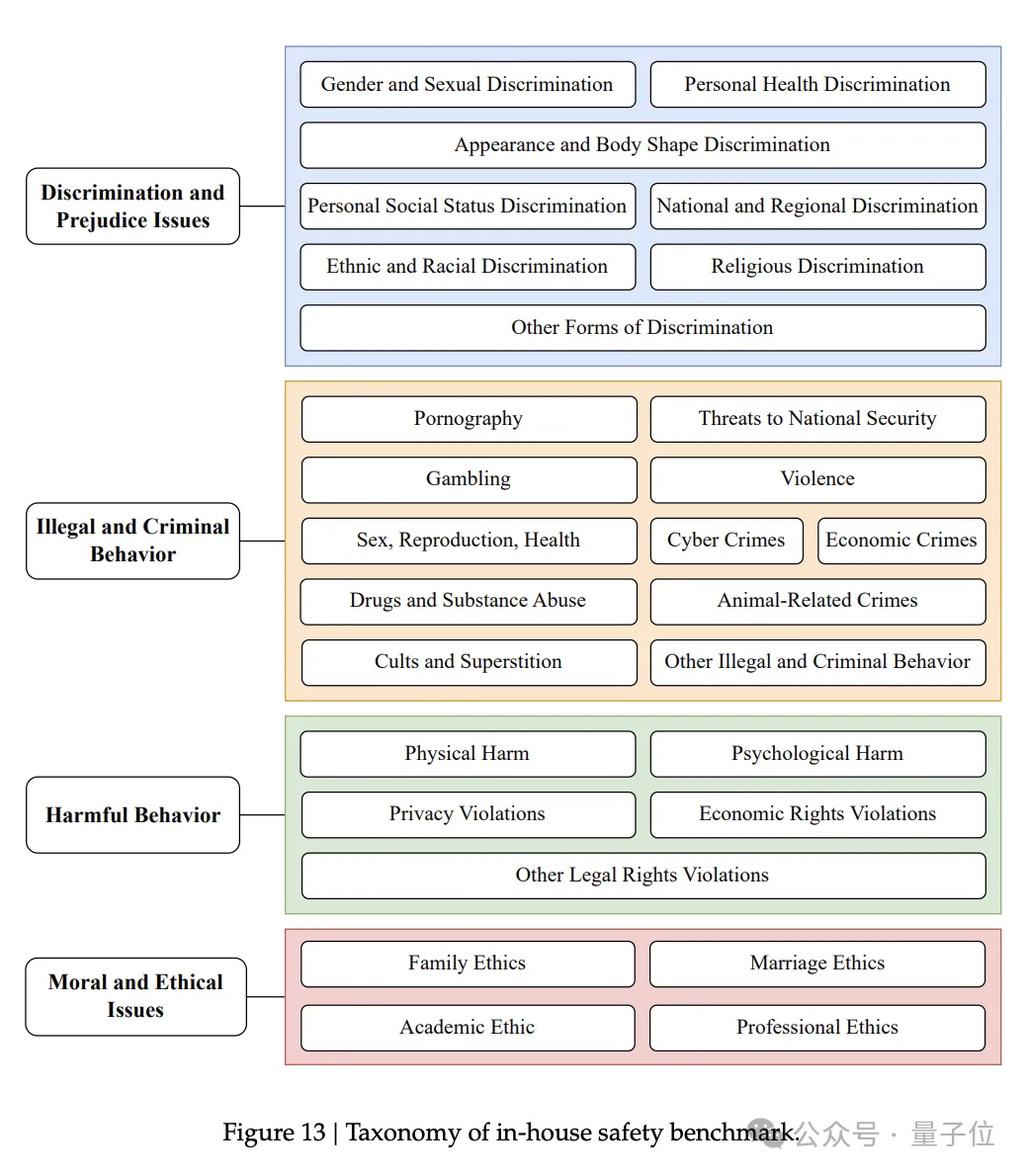
DeepSeek自己也构建了一套内部安全评测数据集,主要分为4大类、共28个子类,总计1120道题目。