老黄开年演讲「含华量」爆表新智元
CES巨幕上,老黄的PPT已成中国AI的「封神榜」。DeepSeek与Kimi位列C位之时,算力新时代已至。
万众瞩目的2026 CES科技盛宴上,一张PPT瞬间燃爆AI圈。
老黄主旨演讲上,中国大模型Kimi K2、DeepSeek V3.2,以及Qwen赫然上屏,位列全球开源大模型前列,性能正在逼近闭源模型。
这一刻,是属于中国AI的高光时刻。
另外,OpenAI的GPT-OSS和老黄自家的Nemotron,也做了标注。
https://img5.angelyun.com/2026/0_7/oid750045_1.jpe
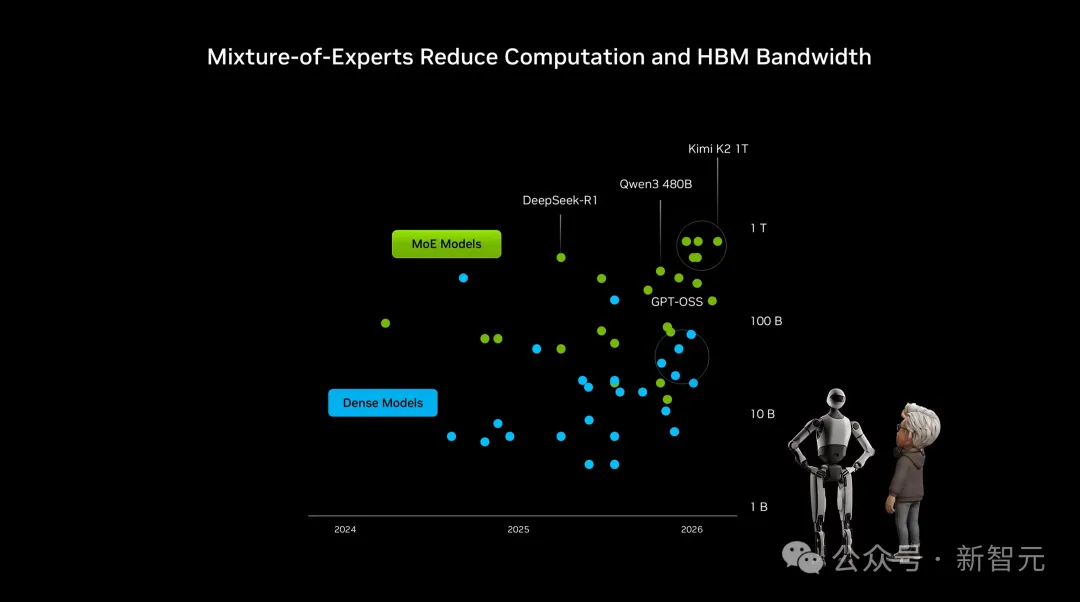
而且,DeepSeek-R1、Qwen3 和 Kimi K2 代表着MoE路线下顶级规模的尝试,仅需激活少量参数,大幅减少计算量和HBM显存带宽的压力。
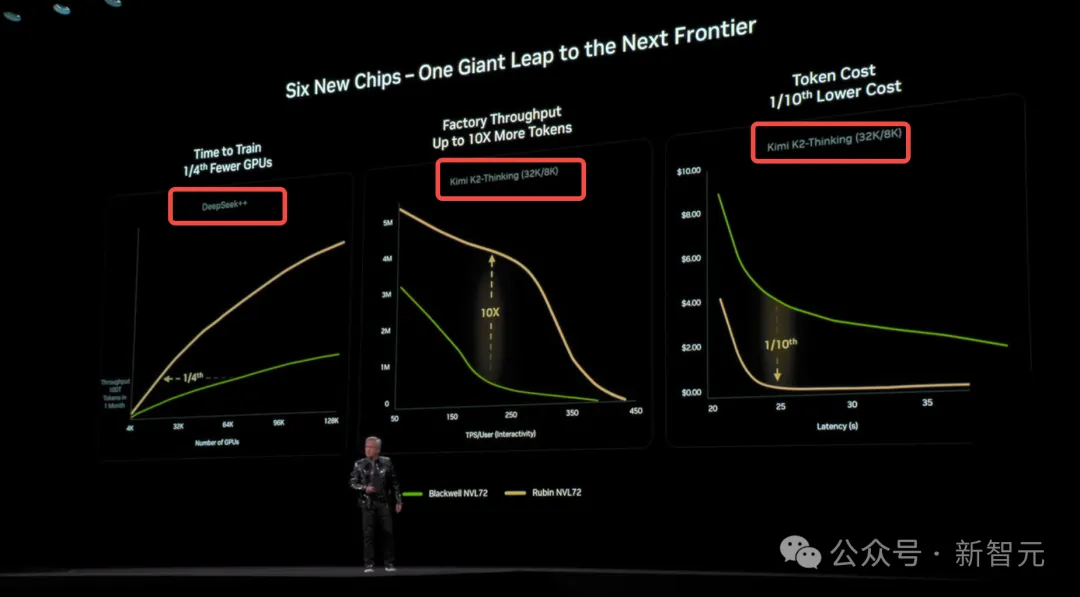
在下一代Rubin架构亮相的核心环节上,老黄还选用了DeepSeek和Kimi K2 Thinking来秀性能。
在Rubin暴力加成下,Kimi K2 Thinking推理吞吐量直接飙了10倍。更夸张的是,token成本暴降到原来的1/10。
这种「指数级」的降本增效,等于宣告了:AI推理即将进入真正的「平价时代」。
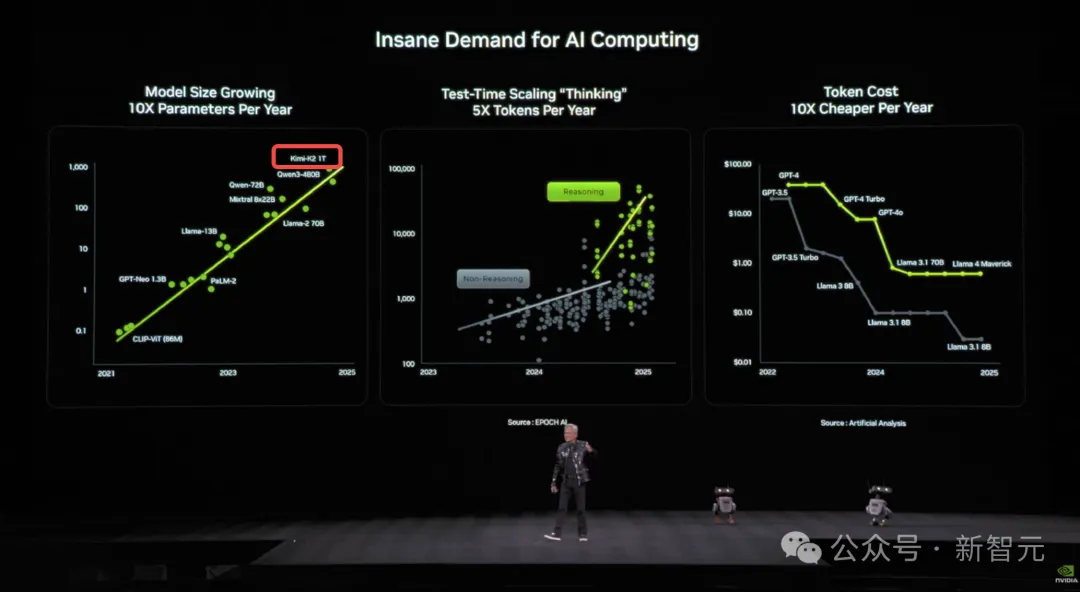
另外,在计算需求暴涨这页PPT上,480B的Qwen3和1TB的Kimi K2成为代表性模型,验证了参数规模每年以十倍量级scaling。
不得不说,老黄整场发布会上,中国AI模型的含量超标了。
推理狂飙十倍
中国模型成老黄「御用」AI?
无独有偶,英伟达去年12月的一篇博客中,也将DeepSeek R1和Kimi K2 Thinking作为评判性能的标杆。
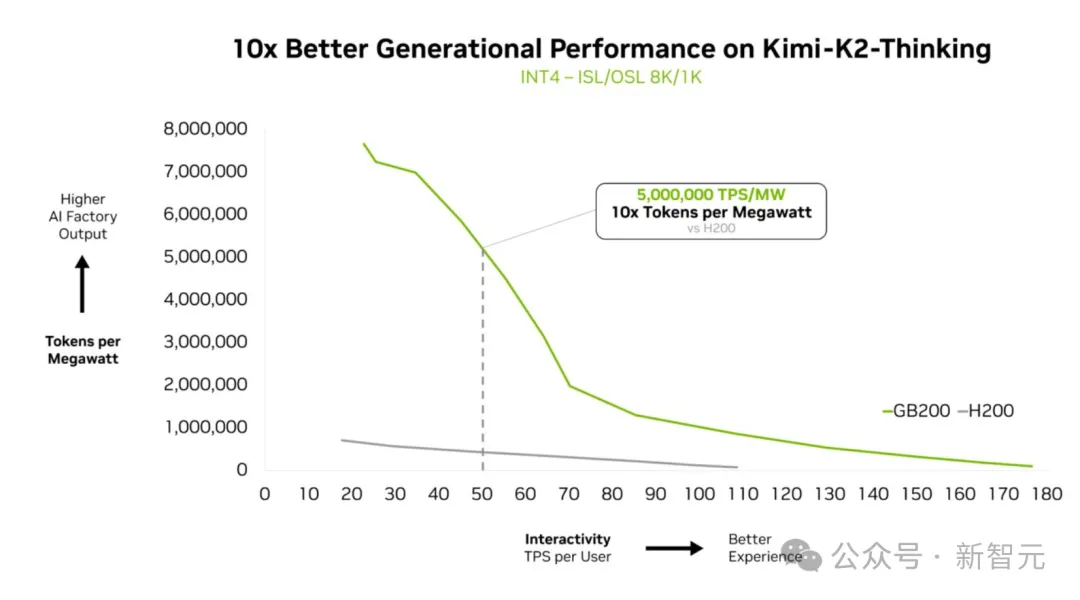
实测显示,Kimi K2 Thinking在GB200 NVL72上性能可以暴增10倍。
另外,在SemiAnalysis InferenceMax测试中,DeepSeek-R1将每百万token的成本降低10倍以上。包括Mistral Large 3在内同样获得了十倍加速。