港科大教授实测AI眼镜“作弊”华尔街日报
一代人有一代人的学习机。港科大教授的实验证实,一副搭载ChatGPT-5.2的AI眼镜在30分钟内完成《计算机网络原理》期末考试,取得了超过95%考生的高分。这一结果不仅展示了AI在标准化考试中强大的“应试”能力,更对依赖标准答案的传统教学评估体系构成了直接冲击,促使教育界思考如何转向对思维过程与创新能力的评价。
离了大谱了,AI真·走进了大学期末考场,并且还是以作弊者的身份。(你就说震不震惊吧)
没开玩笑,事情就发生在香港科技大学《计算机网络原理》的本科期末考试“现场”。
一副搭载ChatGPT-5.2模型的AI眼镜,被直接戴上鼻梁,在复刻真实考试条件的情况下,完成了整套期末试卷。
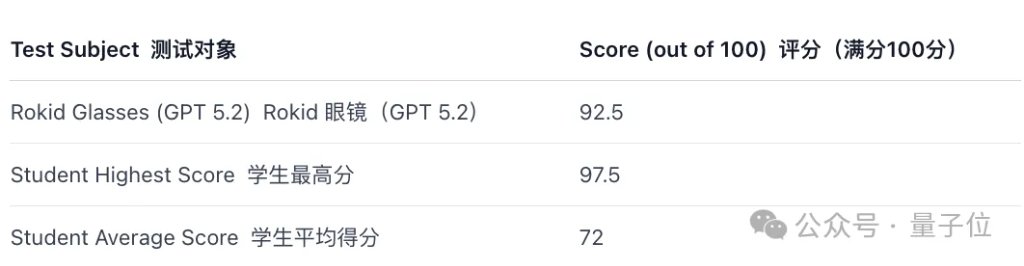
结果甚是魔幻:30分钟交卷,狂揽92.5分,并在一百多人的排名里跻身进了前五,轻松碾压超95%的人类考生:
果然,一代人有一代人的学习工具,以前是小抄复习资料,这回直接升级成——「整机」。
只不过,当这套整机已经能完整跑完一整套考试流程时,大家关注的重点,可能不再只是AI会不会答卷了。
这一次,AI“作弊者”只是像人类学生那样完整答了一遍题,却让传统的教学评估体系看起来似乎有点站不住脚。
一副AI眼镜,跑完了一整场大学期末考试
这场看似离谱的「人机同场考试」,可不是学生的临时整活,而是由香港科技大学张军教授、孟子立教授团队主导的一场实验。
目标很明确,那就是让一副搭载大模型的AI眼镜,光明正大地在考场“作弊”,然后看它能考多高分~
其选中的测试场景也是非常的简单粗暴,直接瞄准了令无数大学生《闻风丧胆》的专业课——计算机网络原理。(瑟瑟发抖…
这门课程不仅考查海量的专业概念,更涉及严密的逻辑推导与算法应用,对人类学生来说是不小的挑战,对AI而言更是难度拉满。
对此,为了让这位AI考生发挥出最强实力,项目组在「软硬件」筛选上可谓是做足了功课!
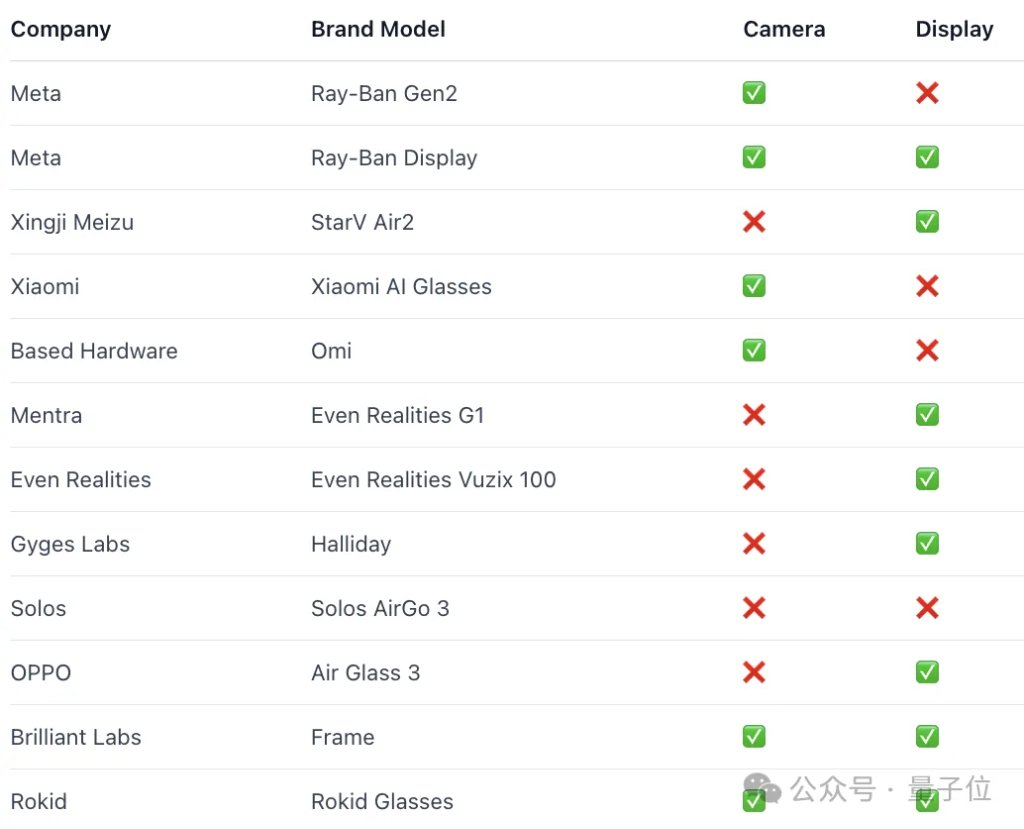
在硬件筛选环节,项目团队对市面上12款主流商业智能眼镜进行了系统评估,其中也包括大家熟悉的Meta、小米、乐奇Rokid等厂商的产品:
第一轮筛选后,团队发现真正同时具备内置摄像头和集成显示屏的产品其实并不多,进入候选范围的主要只有Meta Ray-Ban、Frame,以及乐奇Rokid。
但实验还需要进行二次开发,尽管Meta提供了设备访问工具包,但并未开放对显示内容的直接控制接口,难以满足实验对信息呈现方式的要求。
相比之下,乐奇Rokid的SDK更丰富、生态更完善,开发自由度显著更高。
再综合考虑Frame在试卷识别等场景下的相机画质限制,研究团队最终选择了乐奇AI眼镜作为这次人机同场考试的硬件测试选手:
而在决定大脑上限的大模型筛选上,团队则对比了多款主流模型,最终锁定了OpenAI目前最新的模型——无论是响应速度还是通用知识能力都较强的ChatGPT—5.2。
软硬件「考生」均已就位,接下来就是重头戏——大考。
考试过程,可以用丝滑二字来形容:学生低头查看试卷,AI眼镜通过摄像头快速拍摄题目,并经由“眼镜—手机—云端”链路将图像传输至远程大模型完成推理,生成的答案再沿相反路径返回,最终显示在眼镜屏幕上,供学生抄录。
结果您猜怎么着?这款基于Rokid Glasses开发、搭载GPT-5.2模型的AI眼镜,在本次期末考试中拿下92.5分,成绩超过了95%的学生。
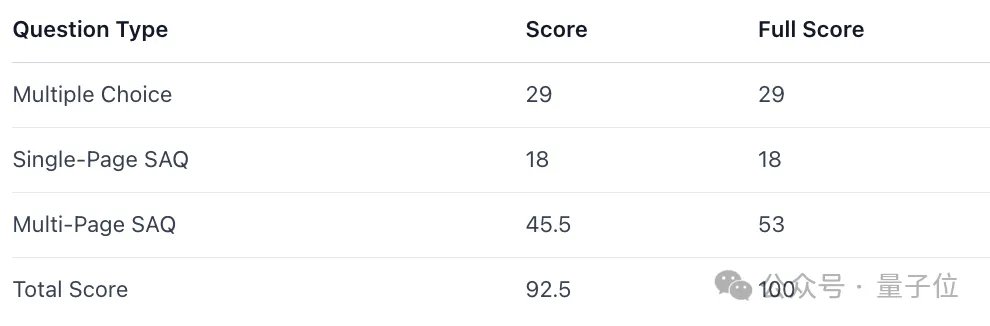
不仅如此,在多项选择题和单页短答题中,乐奇Rokid均获得满分,即便是难度更高的跨页短答题(SAQ),也拿到了大部分分数:
此外,在面对那些核心问题被拆分在不同页码、高度依赖上下文逻辑的跨页短答题,乐奇Rokid依然展现出了极强的推理连贯性。
即便在计算最复杂的部分偶尔出现偏差,但AI给出的中间步骤也算得上非常完整,在处理高压知识任务时也是手拿把掐~
当然,这场测试在跑通软件逻辑的同时,也无情地照出了目前商业AI眼镜存在的《短板》。
首先暴露出来的,是功耗问题。
在考试这样的高压连续场景下,连接本身就已经成为主要耗电源,实验中只要开启Wi-Fi、持续进行高分辨率图像传输,30分钟内眼镜电量就会从100%迅速跌到58%。
换句话说,如果AI眼镜要真正走向全天候、长时间使用,功耗控制和连接稳定性依然是绕不开的工程瓶颈…
不仅如此,项目团队还发现眼镜摄像头的「清晰度」会直接决定AI的视力,一旦题目出现模糊、反光或拍摄角度偏差,再强的模型也只能在不完整信息上做推理,最终体现在答题表现上的,就是明显下滑的稳定性。
但…这场测试带来的冲击和反思,并不只停留在技术层面。
在不做任何特殊照顾的前提下,AI眼镜依然能够把一整套读题—理解—作答的流程跑得又快又稳,这反过来照出了一个更值得注意的问题——
当教学评估主要关注的只是最后有没有交出一份「标准答案」时,它恰好落在了AI最擅长、也最稳定的能力区间里。
也正因为如此,那套以知识点掌握程度和标准解题路径为核心的教学评估方式,在一个早已被各种“学习机”包围的时代,开始显得有些吃力了。
有了聪明的AI,传统教学评估标准还站得住脚吗
不知道大家有没有发现一件挺有意思的事情:
从小学一路考到大学,我们最熟悉的考试,其实一直在反复确认同一件事,那就是有没有把老师讲的内容记住,以及能不能按标准方法,把题一步步算对。
u1s1,在很长一段时间里,这套评估方式确实挺管用。
因为在记忆、计算、按步骤推导这些能力上,人和人之间确实存在明显差距,有人记得牢、算得快,有人就是会漏步骤、算错数。
成绩单上的数字,也确实能覆盖一个人相当大比例的学习表现。
但问题在于,当AI开始在这些评估维度上,也变得又快、又稳、而且几乎不出错时,事情就开始变得微妙了…
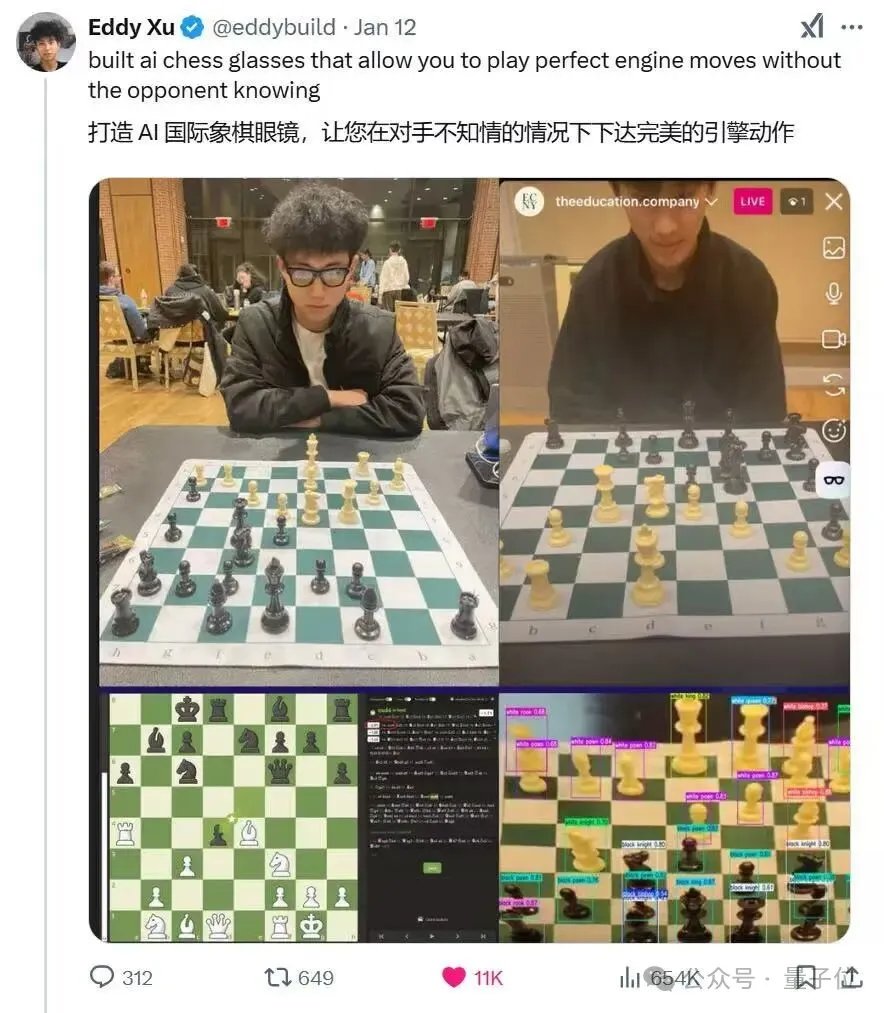
此前,一位创业者小孩哥Eddy Xu通过改装Meta智能眼镜,做出了一套可以在国际象棋比赛中实时显示最优解法的“作弊”设备,在几乎不需要自己思考的情况下,就能稳定赢下对局:
在这个过程中,AI眼镜不会紧张,也不会疲劳,更不存在临场波动,一个字形容——稳。
这和乐奇Rokid眼镜参加期末考试的表现其实是同一套逻辑:只要题目规则清晰、评价目标单一,AI就能把读题—理解—推理—作答这套流程稳定跑完。
哪怕脱离纸笔形态,它依然能在高度结构化的考试里,持续拿到高分。
类似的案例并不只发生在个人层面。
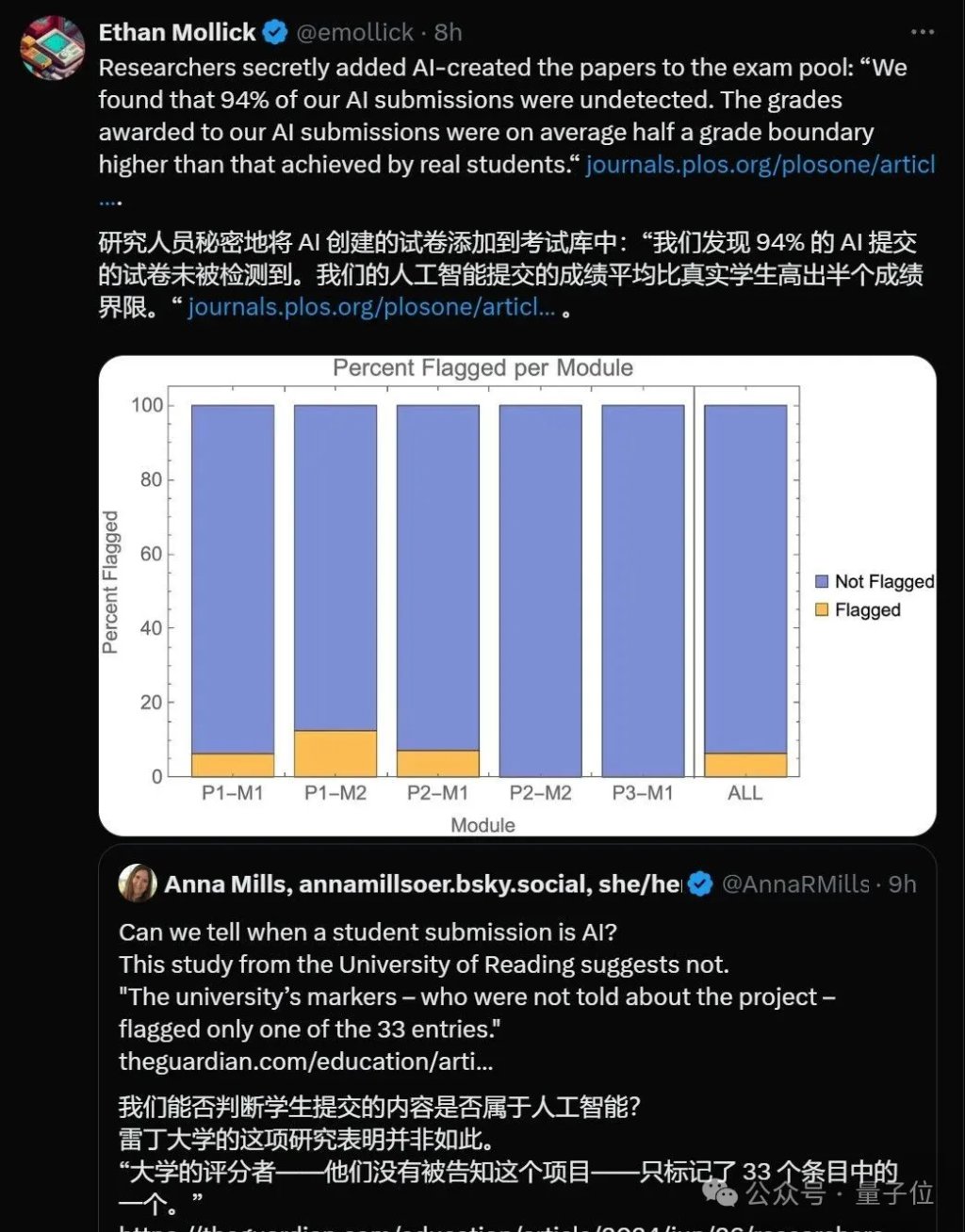
此前,英国雷丁大学的一项研究还发现,当研究人员将AI生成的答卷混入考试题库后,有高达94%的试卷成功“浑水摸鱼”,而这些AI的平均成绩,甚至还明显高于真实学生…(天塌啦
这下是真有点尴尬了——比人比不过,比AI也比不过:
让人大跌眼镜大开眼界的同时,一个原本不那么尖锐的问题被直接推到台前——
当AI或机器比人更擅长按标准作答时,那套以笔试为核心、用来衡量知识点掌握程度的评估体系,到底在测什么?
回过头看教学培养的最初目的,我们会发现很多被反复强调的重要能力,其实并不天然适配“一张试卷”这种形式。
——比如提出好问题的能力。
——在信息不完整时做判断的能力。
——在多种方案之间权衡取舍的能力。
——以及理解现实情境、理解他人立场的能力。
这些能力真正指向的是学习过程、思考路径和决策质量,答案是否标准只是其中很小的一部分。