黄仁勋CES演讲:Rubin投产,算力暴涨5倍华尔街日报
英伟达Vera Rubin平台全面投产,通过“极端协同设计”将AI推理性能提升5倍、成本降至1/10,直击智能体“算不起、记不住”痛点。黄仁勋宣告AI进入“会思考”下半场,高呼“物理AI的ChatGPT时刻已近”。通过开源智能驾驶模型Alpamayo模型与西门子合作,英伟达展示了从芯片到机器人的全栈拼图。
北京时间6日凌晨5点,美国拉斯维加斯,在全球“科技春晚”——国际消费电子展(CES)的聚光灯下,英伟达CEO黄仁勋身着标志性的鳄鱼皮纹黑色夹克跑步登台。
“AI竞赛已经开始,所有人都在努力达到下一个水平……如果你不进行全栈的极端协同设计,根本无法跟上模型每年增长10倍的速度。”面对资本市场对“AI泡沫”的隐忧和摩尔定律失效的焦虑,黄仁勋用一套名为Vera Rubin的全新架构,向外界证明:英伟达依然掌握着定义AI未来的绝对权力。
这次演讲不同于以往单纯发布显卡,老黄这次虽然没有带来GeForce新品,却用“All in AI”、“All in 物理AI”的姿态,向资本市场展示了一张从原子级芯片设计到物理世界机器人落地的完整拼图。
演讲三大主线:
在基础设施与算力层面,英伟达通过“极端协同设计”暴力破解物理极限,重构了数据中心的成本逻辑。 面对晶体管数量仅增长1.6倍的瓶颈,英伟达通过Vera Rubin平台、NVLink 6互联以及BlueField-4驱动的推理上下文内存存储平台,强行将推理性能提升5倍,并将Token生成成本压低至1/10。这一层面的核心目标是解决Agentic AI(代理智能体)“算不起”和“记不住”(显存墙)的问题,为AI从训练向大规模推理转移铺平道路。
在模型演进层面,英伟达正式确立了从“生成式AI”向“推理型AI”(Test-time Scaling)的范式转移。 黄仁勋强调AI已不再是一次性的问答,而是需要多步思考和规划的思维链过程。通过开源Alpamayo(自动驾驶推理)、Cosmos(物理世界模型)以及Nemotron(智能体)系列模型,英伟达正在推动AI具备逻辑推理能力和长时记忆能力,使其能处理未见过的复杂长尾场景。
在物理落地层面,英伟达宣布“物理AI”正式进入商业变现期,打破了AI仅存于屏幕的局面。 演讲明确了2026年Q1梅赛德斯-奔驰实车上路的时间表,并展示了与西门子在工业元宇宙的深度全栈合作。通过将Omniverse模拟环境、合成数据生成与机器人控制模型打通,英伟达正在将AI能力从互联网云端这一“软世界”,大规模注入到汽车、工厂、机器人等“硬世界”中。
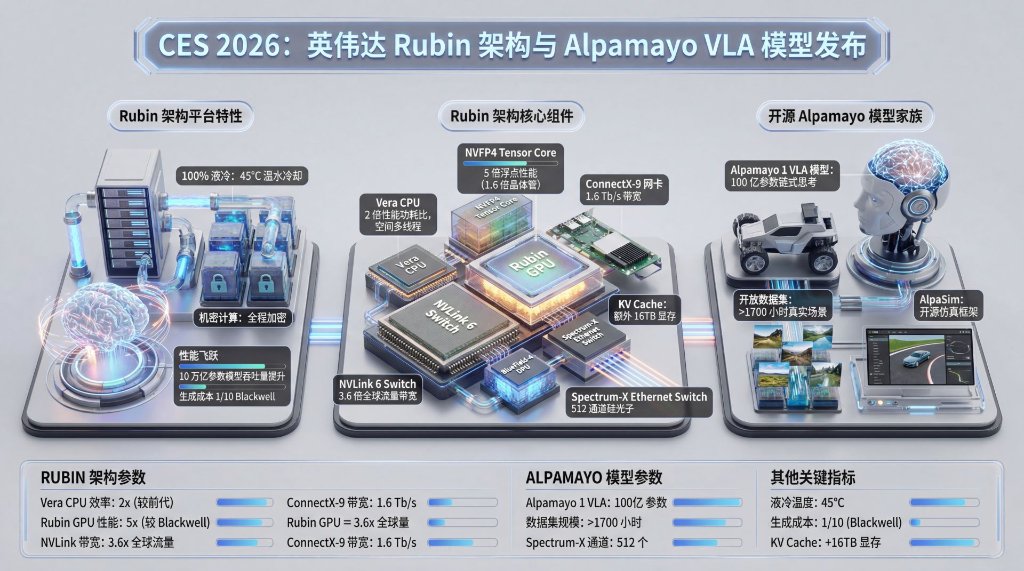
Vera Rubin平台全面投产:新一代AI计算平台的全部六款核心芯片已完成制造和关键测试,已进入全面生产阶段。在晶体管仅增长1.6倍的物理极限下,通过“极端协同设计”强行实现5倍推理性能提升,训练性能提升3.5倍。微软下一代AI超级工厂将部署数十万颗Vera Rubin芯片。
Rubin推理成本较Blackwell降10倍:明确回应市场对AI太贵的质疑,Rubin将推理Token生成成本压低至Blackwell的1/10,让高昂的Agentic AI具备商业可行性。
解决AI“记忆”瓶颈:利用BlueField-4 DPU构建推理上下文内存存储平台,为每颗GPU凭空增加16TB高速共享内存,彻底解决长文本“显存墙”问题。
物理AI变现时刻:发布“具备推理能力”的自动驾驶模型Alpamayo,明确2026年Q1随梅赛德斯-奔驰实车上路,开启物理AI营收周期。
能源经济学重构:Rubin架构支持45℃温水冷却,无需冷水机组,直接为全球数据中心节省6%的电力。
开源生态扩张:宣布扩展其开源模型生态,覆盖物理AI、自动驾驶、机器人、生物医学等多个关键领域,并提供配套数据集和工具链。
工业元宇宙落地:与西门子达成深度全栈合作,将英伟达AI技术植入全球工业制造底层,从“设计芯片”延伸至“设计工厂”。
新王亮相:Rubin平台全面投产,推理成本较Blackwell降10倍
“Vera Rubin已经全面投产。”黄仁勋宣布在CES展会推出新一代Rubin AI平台,该平台通过六款新芯片的集成设计,在推理成本和训练效率上实现大幅跃升,将于2026年下半年交付首批客户。
这也是市场最为关切的消息。他将Rubin GPU形容为“一只巨大的怪兽(It's a giant ship)”,并详尽阐述了背后的逻辑:“AI的推理成本每年要下降10倍,而AI‘思考’(Test-time Scaling)产生的token数量每年增长5倍。”在这两股力量的巨大拉扯下,传统芯片的迭代节奏无法满足要求。
黄仁勋用一个生动的比喻来解释新一代AI芯片的设计思路:“这不是简单地造一个更好的引擎,而是重新设计整辆车,让引擎、传动、底盘协同工作。”“它的AI浮点性能是Blackwell的5倍,但晶体管数量仅为后者的1.6倍。”黄仁勋强调,这种超出摩尔定律常规预期的性能飞跃,源自于“极端协同设计”。
他所指的“协同”涵盖了从CPU、GPU、网络芯片到整个冷却系统的全方位重构。这种设计的实际效果直接反映在市场最敏感的成本指标上:推理成本最高可降至Blackwell平台的1/10。具体来看:
算力: Rubin GPU在NVFP4精度下的推理性能达到50 PFLOPS(Blackwell的5倍),训练性能35 PFLOPS(较上代提升3.5倍)。每颗GPU封装8组HBM4内存,带宽高达22 TB/s。
CPU黑科技: 全新的Vera CPU集成了88个定制Olympus Arm核心,采用了一种名为“空间多线程”(Spatial Multi-threading)的设计,可同时高效运行176个线程,解决了CPU跟不上GPU吞吐的痛点。
连接: NVLink 6将机架内的通信带宽推高至惊人的240 TB/s,是全球互联网总带宽的两倍以上。
AI的下半场:从“死记硬背”到“逻辑思考”
演讲中,黄仁勋敏锐地捕捉到了AI模型侧的根本性变化——Test-time Scaling(测试时扩展)。
“推理不再是一次性的回答,而是一个思考的过程。”他指出,随着DeepSeek R1和OpenAI o1等模型的出现,AI开始展现出思维链(Chain of Thought)能力。这意味着AI在给出答案前,需要消耗大量的算力进行多步推理、反思和规划。
对于投资者而言,这是一个巨大的增量信号:未来的算力消耗将从“训练侧”大规模转移到“推理侧”。为了支撑这种“让AI多想一会儿”的需求,算力必须足够便宜。Rubin架构的核心使命,就是将MoE(混合专家模型)的推理Token生成成本降低至Blackwell的1/10。只有将成本打下来,能够处理复杂任务的Agentic AI(代理智能体)才具备商业落地的可能性。
突破瓶颈:如何让AI“记住”更长的对话
而当AI从简单的问答转向长时间的复杂推理时,一个新的瓶颈出现了——记忆。
在Agentic AI时代,智能体需要记住漫长的对话历史和复杂的上下文,这会产生巨大的KV Cache(键值缓存)。传统的解决方案是将这些数据塞进昂贵的HBM显存中,但HBM容量有限且价格高昂,这被称为“显存墙”。
黄仁勋详细解释了这一问题:“AI的工作记忆存储在HBM内存中。每生成一个token,它都要读取整个模型和所有工作记忆。”对于需要长期运行、拥有持续记忆的AI智能体,这种架构显然不可持续。
解决方案是一套全新的存储架构。黄仁勋亮出了他的秘密武器:基于BlueField-4 DPU构建的推理上下文内存存储平台(Inference Context Memory Storage Platform)。
他指着舞台上那个巨大的机架系统解释道:“在每个GPU原有1TB内存的基础上,我们通过这个平台为每个GPU额外增加了16TB的‘思考空间’。”这个平台被放置在离计算单元最近的位置,通过高达200Gb/s的带宽连接,避免了传统存储带来的延迟瓶颈。