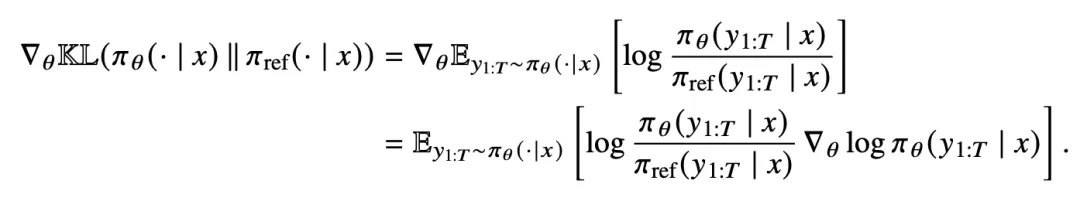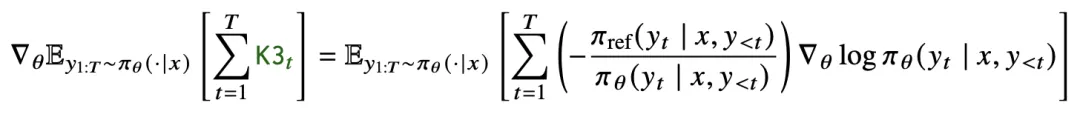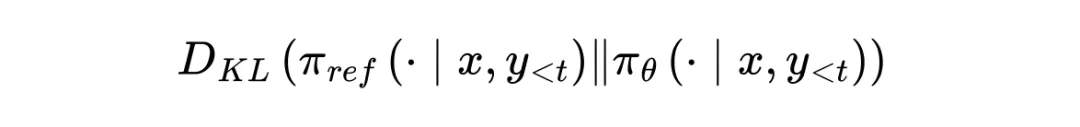Bengio团队实证:回归Reward才是无偏正解PaperWeekly
全网都在卷 RLVR,但 Bengio 团队刚泼了盆冷水。
DeepSeek-R1 的爆火让 RLVR 成为当下大模型后训练的绝对主流。
这个逻辑听起来天经地义,但在工程落地时,我们往往面临一个极其隐蔽的选择。这个 KL 惩罚项,到底是应该减在 reward 里,还是直接加在 loss 里?
论文标题:A Comedy of Estimators: On KL Regularization in RL Training of LLMs
论文链接:https://arxiv.org/pdf/2512.21852
KL散度的计算困境
被忽视的梯度偏差
判断一种实现方式是否正确,唯一的标准是看它的梯度是否与真实梯度 (True Gradient) 一致。
对于序列级反向 KL 散度,其真实梯度的数学形式如下 :
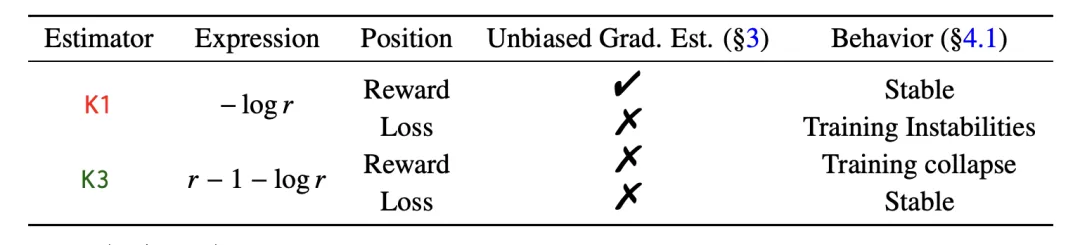
论文对四种常见的“估算器+位置”组合进行了详尽的梯度推导,结果与直觉截然相反。
〓 表1. 不同估算器配置的梯度偏差与训练行为总结。
为什么K3 in Loss是错的?
当我们把 K3 放入 Loss 直接进行反向传播时,推导出的梯度期望包含了一个错误的系数项:
论文明确指出(Eq 41),这个梯度形式实际上是在优化前向 KL 散度:
这导致模型倾向于去覆盖参考模型的分布(Mode-covering),而非我们期望的寻找高奖励模式(Mode-seeking)。
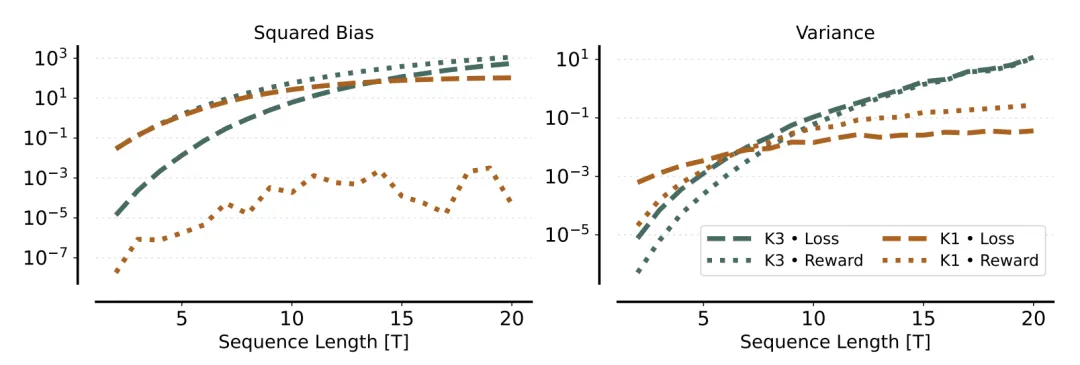
为了直观展示这种偏差,作者构建了一个极简参数化模型(Toy Model)进行验证。
〓 图2. 极简自回归模型下各估算器的梯度偏差(左)与方差(右)。K1 in Reward(点线)的偏差接近于 0,而 K3 in Loss(虚线)存在显著的偏差。
理论上的偏差真的会影响 LLM 的推理能力吗?作者在 Qwen2.5-7B 和 Llama-3.1-8B 上进行了大规模的 MATH 数据集微调实验。
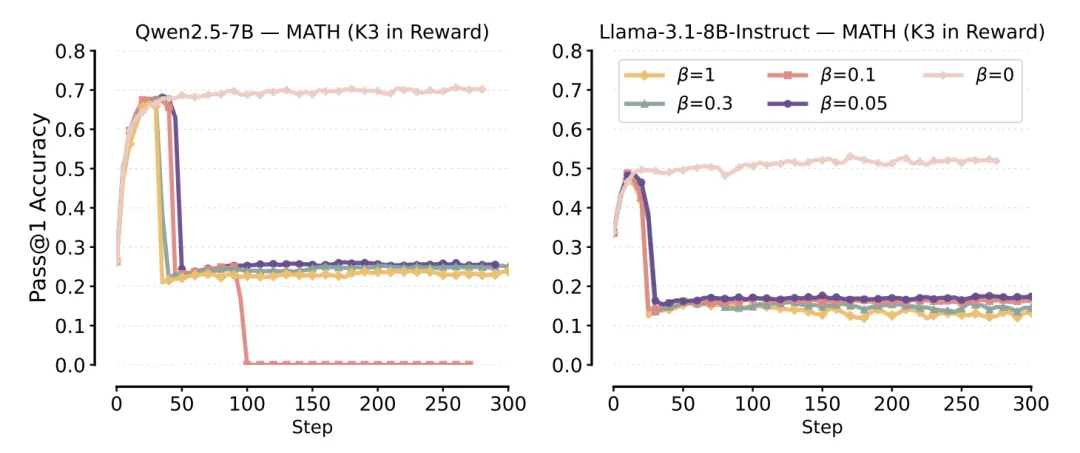
1. 训练稳定性:避坑K3 in Reward
首先,千万不要尝试 K3 in Reward。实验表明,这种配置会引入巨大的梯度方差,导致模型训练瞬间崩溃。
〓 图3. 如图所示,K3 in Reward 会导致 Pass@1 准确率直接跌零。
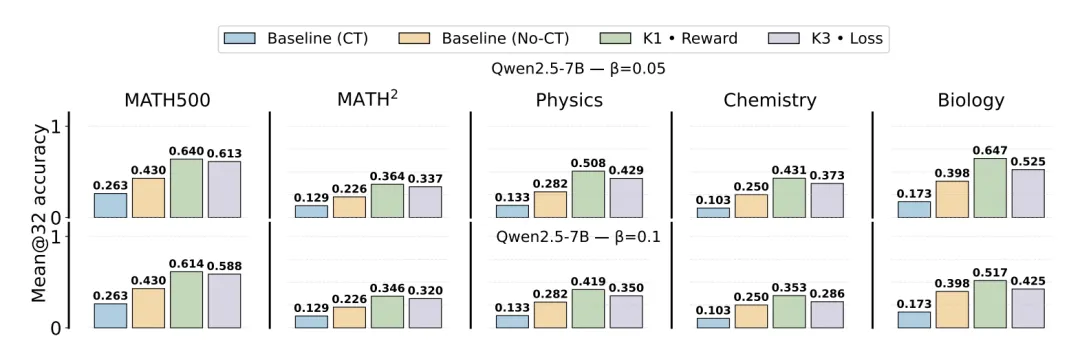
2. 泛化能力:K1 in Reward的降维打击
这是本研究最核心的发现。作者对比了 K3 in Loss(有偏,主流方案)和 K1 in Reward(无偏,推荐方案)在域内(MATH)和域外(Physics, Chemistry, Biology)任务上的表现。
〓 图4. Qwen2.5-7B 在不同 KL 配置下的性能对比。浅绿色 (K1 in Reward) 代表无偏方案,灰色 (K3 in Loss) 代表主流有偏方案。