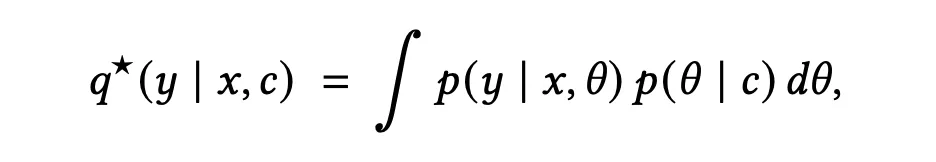优化即几何,几何即推理:洞穿Transformer黑盒PaperWeekly
不是设计,而是进化。当交叉熵遇见 SGD,贝叶斯推理成了唯一的数学必然。
理论锚点:交叉熵的贝叶斯终局
Transformer 的训练通常基于最小化交叉熵损失。Paper I 首先澄清了这一优化过程的数学终局。
在无限数据与容量的极限下,最小化交叉熵 :
其最优解 在数学上严格等价于解析贝叶斯后验预测分布 (Bayesian Posterior Predictive Distribution):
为了验证有限容量的 Transformer 是否真正逼近了这一极限,作者构建了贝叶斯风洞 (Bayesian Wind Tunnels) 。
这是一个完全受控的数学环境,其中每一步的解析后验都是精确已知的。
〓 图1. “贝叶斯风洞”概念图。在缺乏 Ground Truth 的自然语言之外,作者构建了一个可精确测量的受控环境。
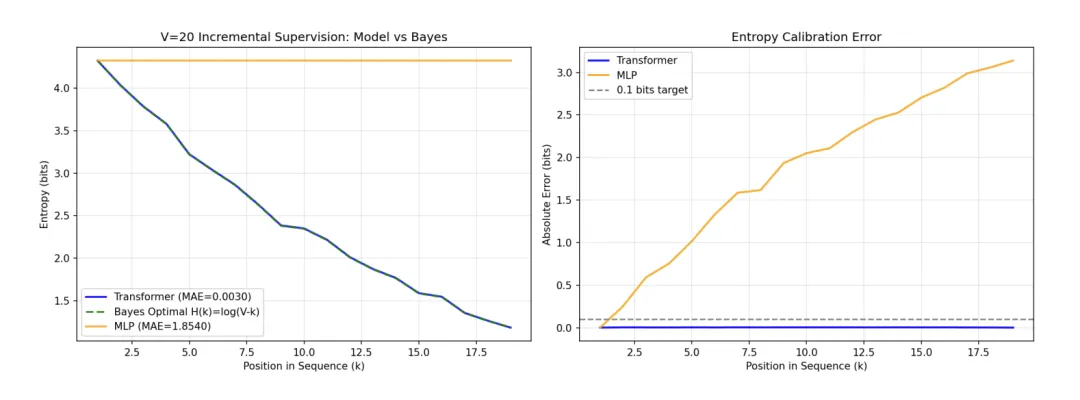
实验结果表明,在双射学习与 HMM 状态追踪任务中,Transformer 展现了极高的精度。
〓 图2. Transformer 的预测熵精确贴合理论贝叶斯后验,平均绝对误差(MAE)低至 10^{-3} 比特;相比之下,MLP 无法有效利用上下文进行假设消除。
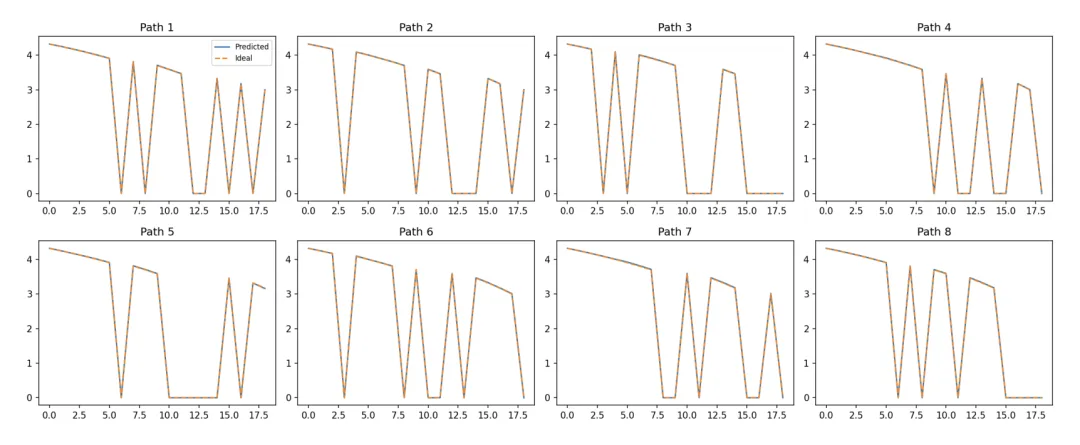
更微观的证据来自单序列分析,这是证明模型真理解而非平均记忆的铁证:
〓 图3. 针对每一个具体序列,Transformer 的熵值(实线)能够精确追踪理论后验(虚线)的锯齿状变化,证明模型在进行逐 Token 的实时推理。
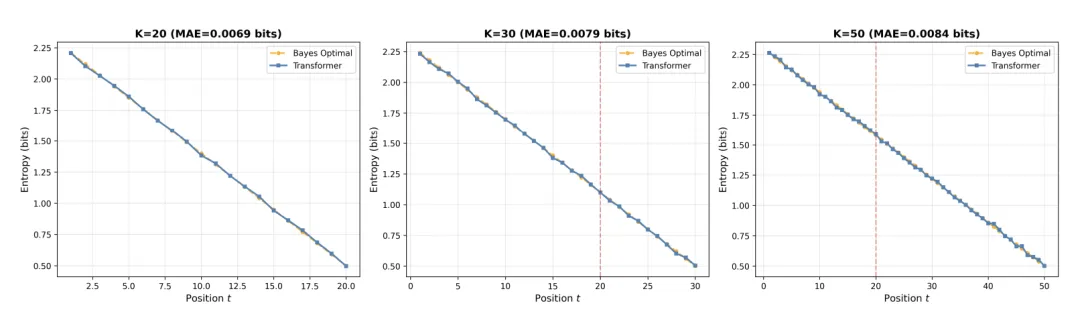
而在 HMM 任务中,模型甚至展现出了完美的长度外推 (Length Generalization) 能力,证明其学会了通用的递归算法:
〓 图4. 模型在训练长度 K=20 内完美拟合。在测试长度 K=30 和 K=50 时,误差平滑增长,未出现断崖式下跌,证明模型并未死记硬背。
几何表征:推理的三阶段演化
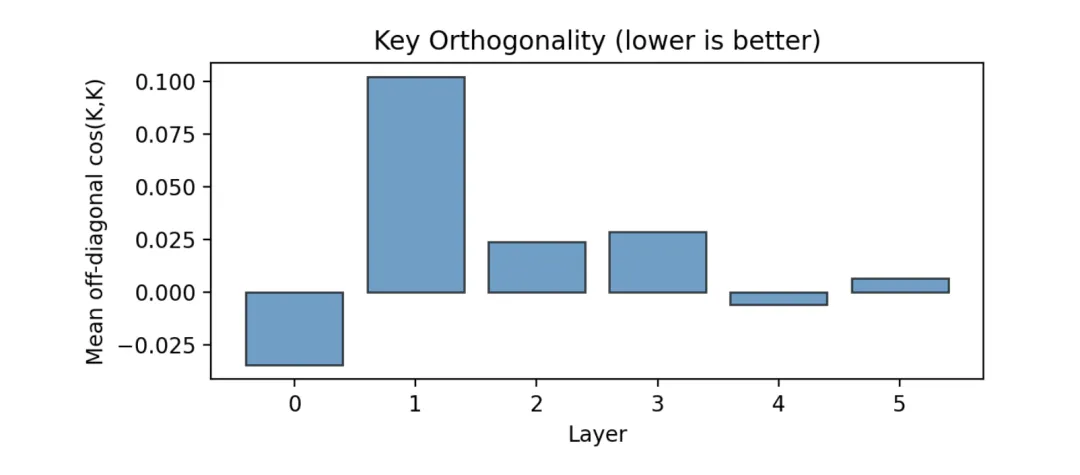
〓 图5. Layer 0 的 Key 向量余弦相似度矩阵。非对角元素接近 0,表明模型构建了正交的假设空间框架。